文章目录
- 相关资料
- 摘要
- 引言
- 方法
- 多模态门控适配器
- 目标函数
- 实验
相关资料
论文:Efficient Remote Sensing with Harmonized Transfer Learning and Modality Alignment
代码:https://github.com/seekerhuang/HarMA
摘要
随着视觉和语言预训练(VLP)的兴起,越来越多的下游任务采用了先预训练后微调的范式。尽管这一范式在各种多模态下游任务中展示了潜力,但在遥感领域的实施遇到了一些障碍。具体来说,同模态嵌入倾向于聚集在一起,阻碍了高效的迁移学习。为了解决这个问题,我们从统一的角度回顾了多模态迁移学习在下游任务中的目标,并基于三个不同的目标重新考虑了优化过程。我们提出了“Harmonized Transfer Learning and Modality Alignment (HarMA)”,一种方法,它同时满足任务约束、模态对齐和单模态统一对齐,同时通过参数高效的微调最小化训练开销。值得注意的是,HarMA无需外部数据进行训练,就在遥感领域的两个流行的多模态检索任务中实现了最先进的性能。我们的实验表明,HarMA仅使用最少的可调参数就能实现与完全微调模型相媲美甚至更优越的性能。由于其简单性,HarMA可以集成到几乎所有现有的多模态预训练模型中。我们希望这种方法能够促进大型模型在广泛的下游任务中的高效应用,同时显著降低资源消耗。
引言
先预训练后全面微调局限性:
- 全面微调一个大型模型极其昂贵且不可扩展。
- 预训练模型已经在大型数据集上训练了很长时间,而在小型数据集上进行全面微调可能导致泛化能力降低或过拟合。
参数高效微调局限性:
- 集中在单模态特征上。
- 在建模视觉-语言联合空间时忽视了潜在的语义不匹配。
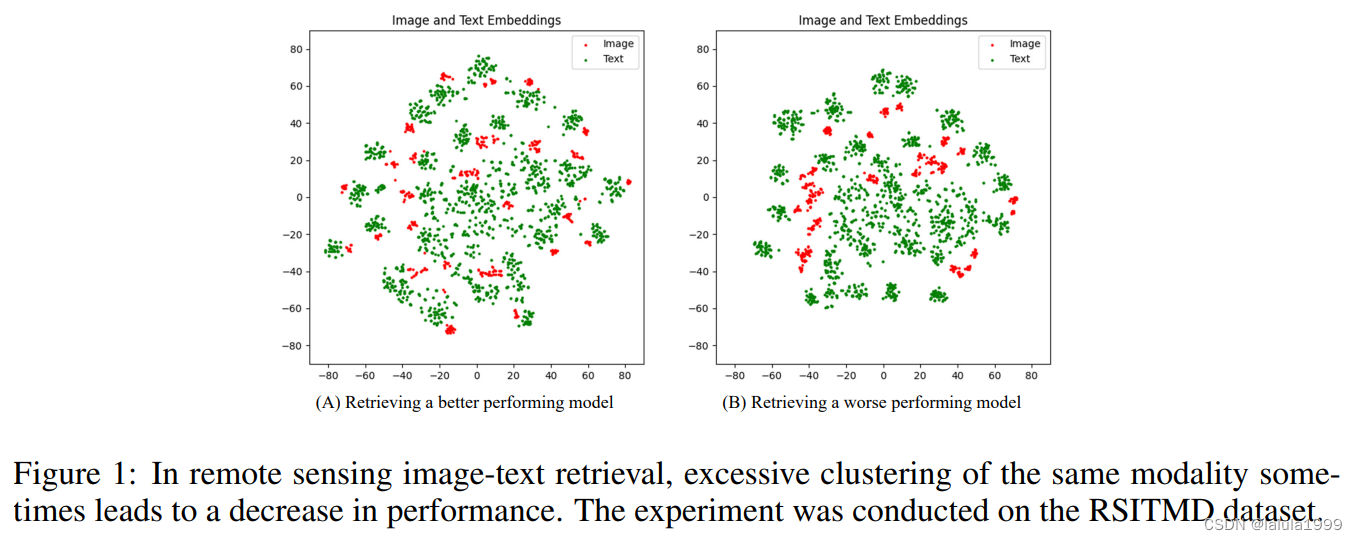
我们观察到,表现不佳的模型有时在其同模态嵌入内部表现出聚类现象。图1展示了在遥感图像-文本检索领域中两个性能不同的模型的最后一层嵌入的可视化;与左侧图像相比,右侧图像中的聚类现象更为明显。我们假设这可能归因于遥感图像的高类内和类间相似性,导致在建模低秩视觉-语言联合空间时出现语义混淆。
类似于人脑的信息处理方法,我们设计了一个带有迷你适配器的分层多模态适配器。该框架模仿人脑利用共享的小型区域处理来自视觉和语言刺激的神经冲动的策略。它通过分层共享多个迷你适配器,从低到高级别地建模视觉-语言语义空间。最后,我们引入了一个新的目标函数,以缓解同一模态内部特征的严重聚类。由于其简单性,该方法可以轻松集成到几乎所有现有的多模态框架中。
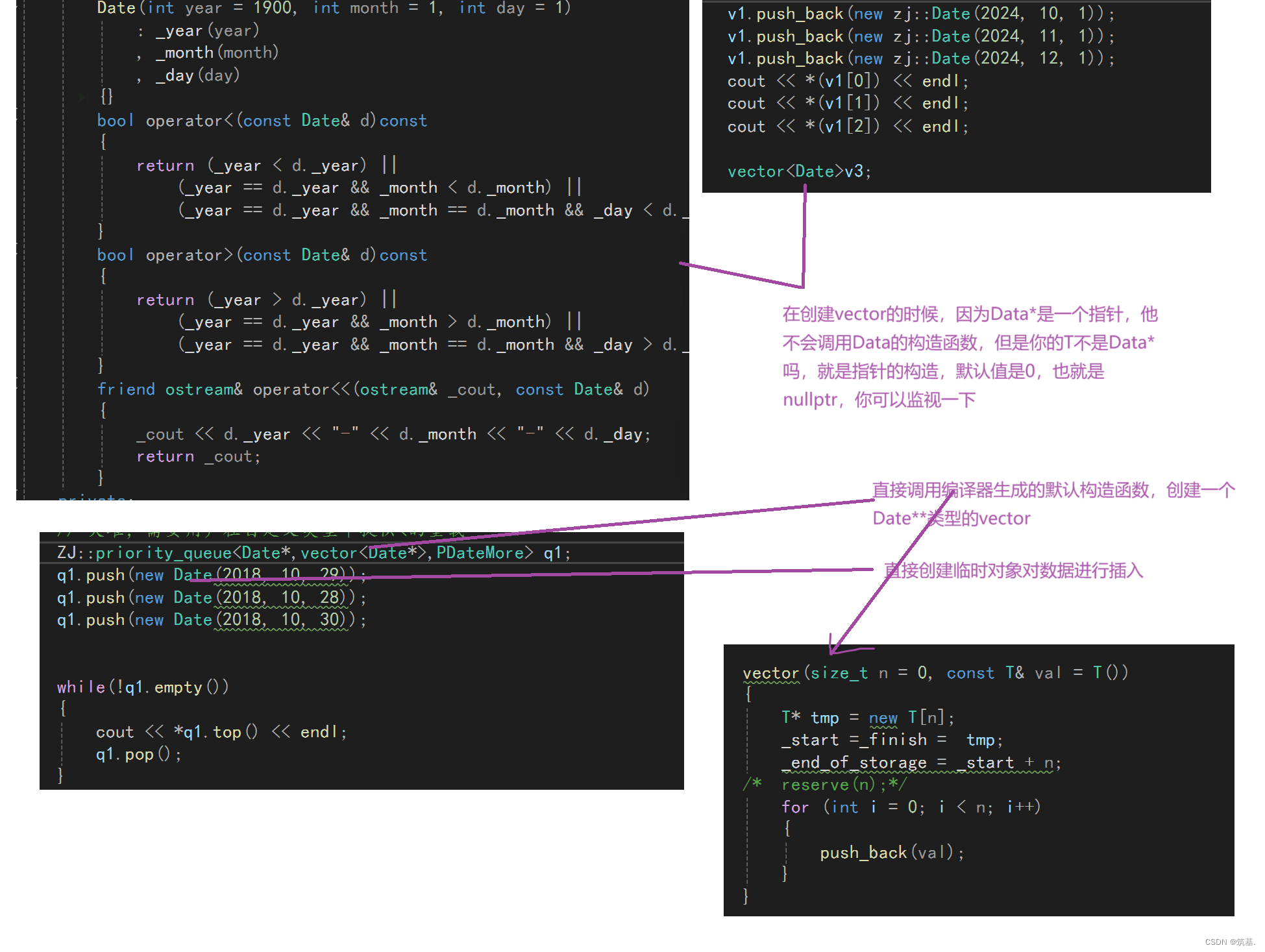
方法
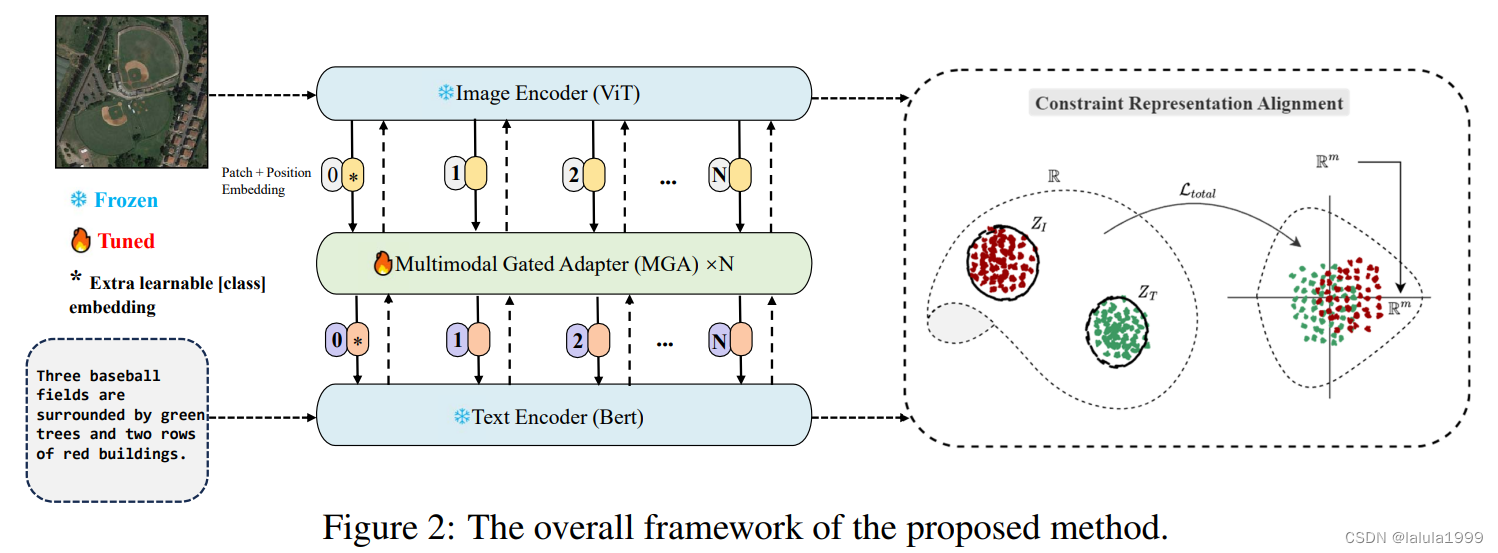
我们提出的 HarMA 框架首先使用图像和文本编码器提取表示,类似于 CLIP。然后这些特征通过我们独特的多模态门控适配器进行处理以获得精炼的特征表示。与使用的简单线性层交互不同,我们采用了共享的迷你适配器作为整个适配器内的交互层。之后,我们使用对比学习目标和我们的自适应三元损失进行优化。
多模态门控适配器
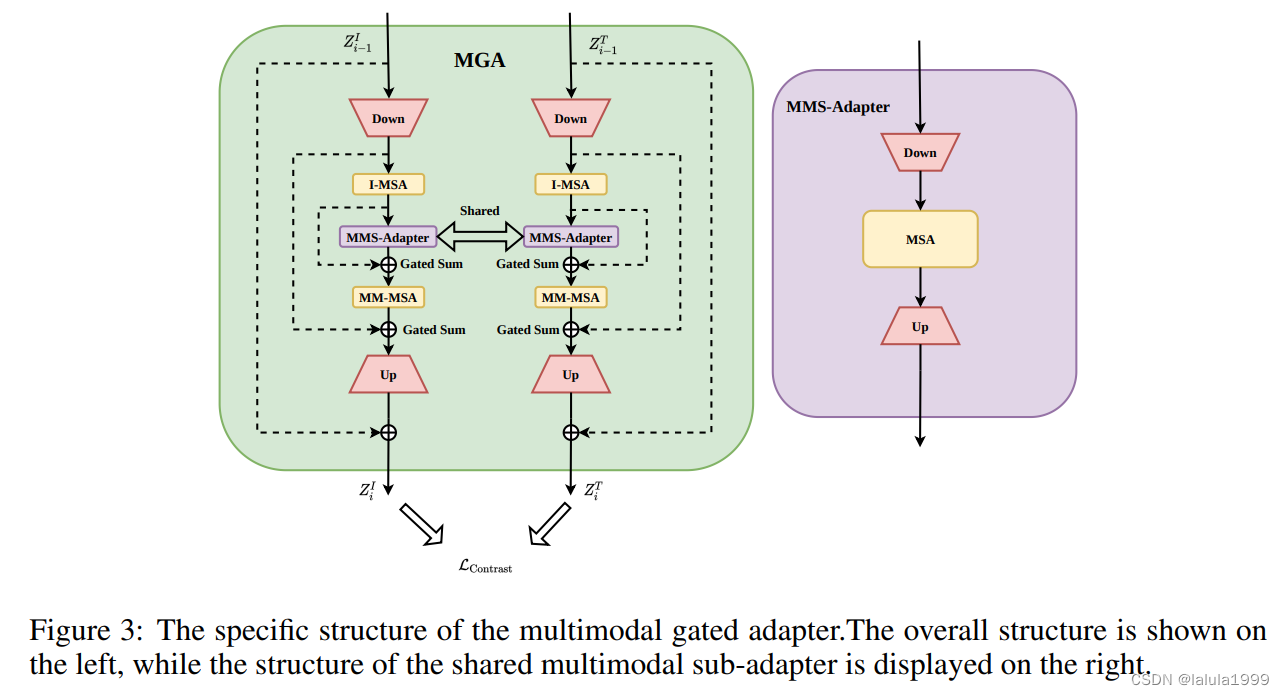
在这个模块中,提取的特征
z
I
z^I
zI 和
z
T
z^T
zT 首先被投影到低维嵌入中。不同的特征
z
I
z^I
zI (
z
T
z^T
zT) 在经过非线性激活和随后的 I-MSA 处理后,特征表达得到了进一步增强。I-MSA 及其后的 MM-MSA 共享参数。然后,这些特征被送入我们设计的多模态子适配器 (MMS-Adapter) 进行进一步交互,该模块的结构在图 3 的右侧显示。
多模态子适配器 (MMS-Adapter)类似于标准适配器,通过共享权重自注意力对齐多模态上下文表示。然而,这些对齐表示的直接后投影输出对图像-文本检索性能产生负面影响,可能是因为在特征的低维流形空间中的非对角线语义关键匹配。这与对比学习目标相矛盾。
为了解决这个问题,已经对齐的表示在 MSA 中进一步使用共享权重进行处理,从而减少模型参数并利用先前的模态知识。为了确保图像和文本之间的更细粒度的语义匹配,我们在 MGA 输出中引入了早期图像-文本匹配监督,显著减少了上述问题的发生。
最终,特征被重新投影回其原始维度,然后添加跳跃连接。最后一层初始化为零,以在训练的初始阶段保护预训练模型的性能。算法 1 概述了提出的方法。

算法1 多模态门控适配器(MGA)用于跨模态交互。
输入:分别来自图像和文本编码器的特征张量
Z
I
Z_I
ZI 和
Z
T
Z_T
ZT。
参数:权重矩阵
W
1
,
W
2
,
W
i
W_1, W_2, W_i
W1,W2,Wi,偏置向量
b
1
,
b
2
,
b
i
b_1, b_2, b_i
b1,b2,bi,以及可学习的门控参数
λ
1
,
λ
2
\lambda_1, \lambda_2
λ1,λ2。
输出:图像和文本的增强特征张量
f
I
e
n
d
f_I^{end}
fIend 和
f
T
e
n
d
f_T^{end}
fTend。
函数
σ
(
⋅
)
\sigma(·)
σ(⋅) 是非线性激活函数(例如,GELU)
函数 MSA(·) 是多头自注意力机制
函数 MMSA(x) 是多模态子适配器机制,定义为:
MMSA
(
x
)
=
W
i
u
p
(
MSA
(
σ
(
W
i
d
o
w
n
x
+
b
i
d
o
w
n
)
)
)
+
b
i
u
p
\text{MMSA}(x) = W_i^{up}(\text{MSA}(\sigma(W_i^{down}x + b_i^{down}))) + b_i^{up}
MMSA(x)=Wiup(MSA(σ(Widownx+bidown)))+biup
对于特征张量集合
{
Z
I
,
Z
T
}
\{Z_I, Z_T\}
{ZI,ZT} 中的每个
Z
Z
Z 做如下操作:
f
1
=
σ
(
W
1
Z
+
b
1
)
f_1 = \sigma(W_1Z + b_1)
f1=σ(W1Z+b1) # 处理图像和文本特征张量
f
2
=
MSA
(
f
1
)
f_2 = \text{MSA}(f_1)
f2=MSA(f1)
f
3
=
λ
1
MMSA
(
f
2
)
+
(
1
−
λ
1
)
f
2
f_3 = \lambda_1\text{MMSA}(f_2) + (1 - \lambda_1)f_2
f3=λ1MMSA(f2)+(1−λ1)f2 # 应用带门控的多模态子适配器
f
4
=
λ
2
MSA
(
f
3
)
+
(
1
−
λ
2
)
f
1
f_4 = \lambda_2\text{MSA}(f_3) + (1 - \lambda_2)f_1
f4=λ2MSA(f3)+(1−λ2)f1
f
e
n
d
=
(
W
2
f
4
+
b
2
)
+
Z
f_{end} = (W_2f_4 + b_2) + Z
fend=(W2f4+b2)+Z
结束循环
返回
f
I
e
n
d
,
f
T
e
n
d
f_I^{end}, f_T^{end}
fIend,fTend
解释:
算法1描述了一个用于增强图像和文本特征的多模态门控适配器(MGA)。这个过程旨在改善跨模态交互,即图像和文本之间的信息交流,以便于它们能够更好地联合表示。
-
输入:算法接收来自图像编码器和文本编码器的特征张量 Z I Z_I ZI 和 Z T Z_T ZT。
-
参数:包含权重矩阵、偏置向量和门控参数,这些参数将用于适配器中的不同处理步骤。
-
处理步骤:
- 首先,使用非线性激活函数(如GELU)处理特征张量。
- 然后,应用多头自注意力机制(MSA)来增强特征表达。
- 接着,通过多模态子适配器(MMSA)进一步处理特征,该适配器使用共享权重和门控机制来调整特征。
- 门控机制允许模型选择性地结合来自不同模态的特征。
-
输出:最终,算法输出增强后的图像和文本特征张量 f I e n d f_I^{end} fIend 和 f T e n d f_T^{end} fTend,这些张量可以用于后续的跨模态任务,如图像-文本检索。
-
目的:通过这种增强,模型能够更好地理解和关联图像和文本数据,从而在多模态任务中取得更好的性能。
目标函数
在多模态学习领域,当进行下游任务的迁移学习时,通常需要为不同任务定制目标函数,并对齐不同模态嵌入。我们最初可以定义应用于所有下游任务的多模态学习目标如下:
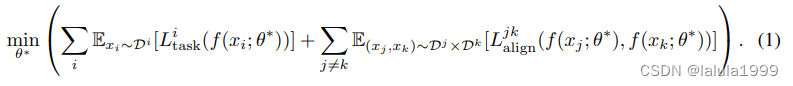
L
t
a
s
k
i
L^i_{task}
Ltaski 表示第 i 个任务的任务损失,
L
a
l
i
g
n
j
k
L^{jk}_{align}
Lalignjk 表示不同模态对 (j, k) 之间的对齐损失。期望是针对每个任务的数据分布
D
D
D。θ* 表示迁移学习的目标参数。
然而,在遥感领域,我们观察到表现不佳的模型有时表现出同模态嵌入聚集在一起的现象,如图 1 所示。Wang & Isola (2020) 强调了来自同一分布的模态对齐的低均匀性可能会限制嵌入的可迁移性。为确保来自同一模态的嵌入均匀对齐而不过度聚集,应用于遥感下游任务的多模态学习统一目标可以定义为:
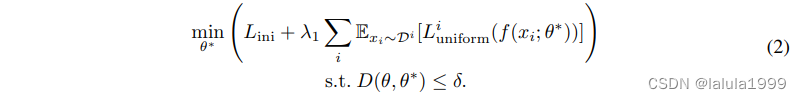
在这个方程中, L i n i L_{ini} Lini 表示初始优化目标(方程 1),由任务损失和对齐损失组成。 L u n i f o r m i L^i_{uniform} Luniformi 表示第 i 个模态的单模态均匀性损失, D ( θ , θ ∗ ) D(θ, θ*) D(θ,θ∗) 是原始和更新模型参数之间的成本度量,被限制为小于 δ。δ 是理想状态下的最小参数更新成本。
我们观察到现有的工作通常只探索一个或两个目标,大多数要么关注如何有效地微调参数以适应下游任务 (Jiang et al., 2022b; Jie & Deng, 2022; Yuan et al., 2023),要么关注模态对齐 (Chen et al., 2020; Ma et al., 2023; Pan et al., 2023a)。很少有工作能够同时满足上述公式中概述的三个要求。我们通过引入模仿人脑的适配器来满足高效迁移学习的需求。这促使我们提出问题:我们如何实现后两个目标——在不同模态之间实现高对齐的嵌入,同时防止同一模态内嵌入的过度聚集?
我们提出了一种自适应三元损失,它自动挖掘并优化硬样本:
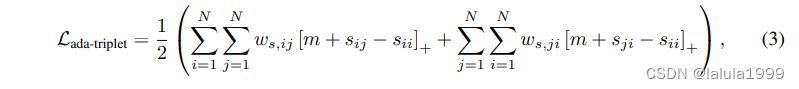
其中
s
i
j
s_{ij}
sij 是图像特征 i 和文本特征 j 之间的点积,
w
i
w_i
wi 和
w
j
w_j
wj 是样本 i 和 j 的权重,由不同样本的损失大小决定。
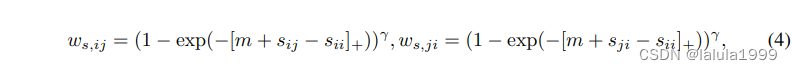
其中 γ 是一个超参数,用于调整权重的大小。这个损失函数的目标是将正样本的特征更紧密地聚集在一起,同时将正样本和负样本之间的特征分开。通过动态调整在硬样本和简单样本之间的关注点,我们的方法有效地满足了上述提出的另外两个目标。它不仅在细粒度层面上对齐了不同模态样本,还防止了同一模态样本之间的过度聚合,从而增强了模型的匹配能力。此外,按照 (Radford et al., 2021b) 的方法,我们使用对比学习目标来对齐图像和文本的语义特征。因此,总目标定义为:
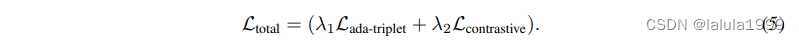
实验
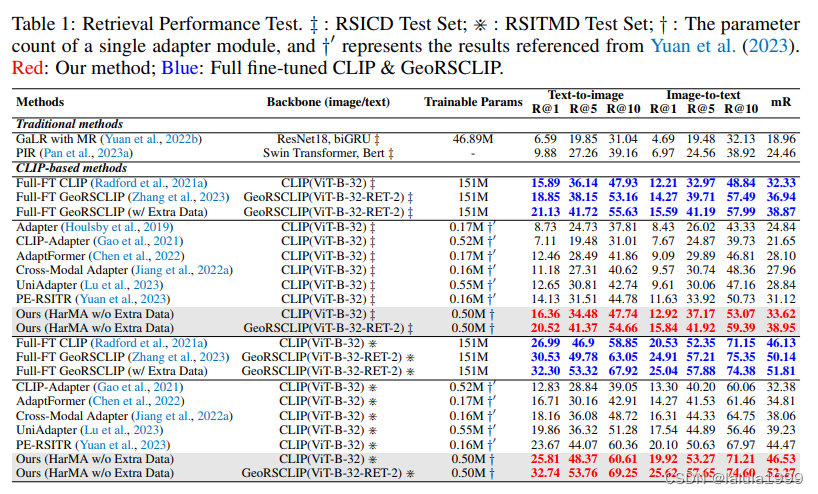
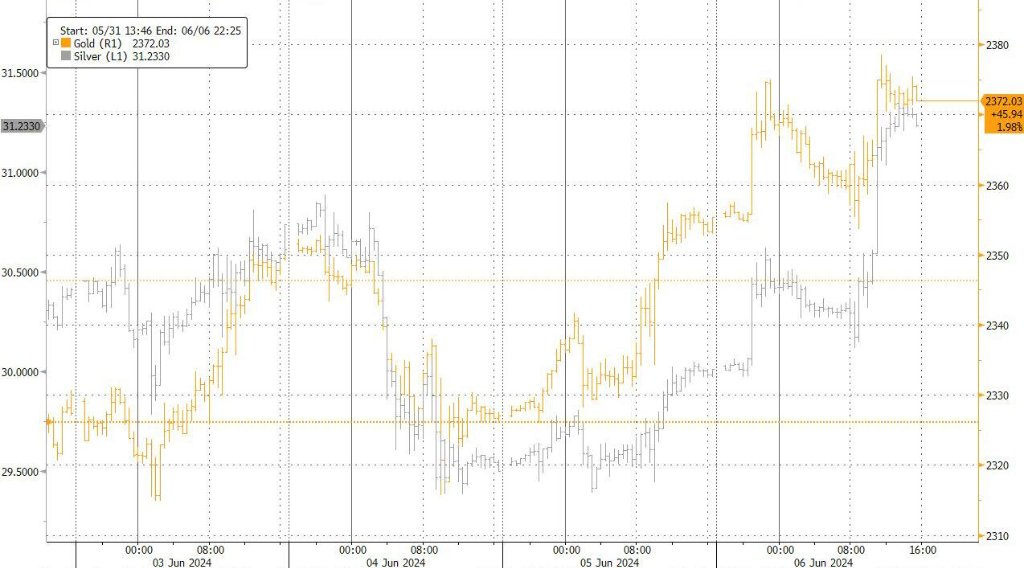
首先,如第一列所示,我们的方法在需要显著较少调整参数的情况下,超越了传统的最先进方法。其次,当使用CLIP(ViT-B-32)(Radford等人,2021a)作为主干时,我们的方法与完全微调方法相比具有竞争力甚至更优越的性能。具体来说,当与具有相似数量可调参数的方法匹配时,我们方法的平均召回率(MR)比CLIP-Adapter(Gao等人,2021)在RSICD上提高了约50%,在RSITMD上比UniAdapter(Lu等人,2023)提高了12.7%,并且在RSITMD上比UniAdapter提高了18.6%。值得注意的是,通过利用GeoRSCLIP的预训练权重,HarMA为遥感领域的两个流行的多模态检索任务建立了新的基准。它只修改了不到4%的总模型参数,超越了所有当前的参数高效微调方法,甚至在RSICD和RSITMD上超过了完全微调的GeoRSCLIP的图像-文本检索性能。