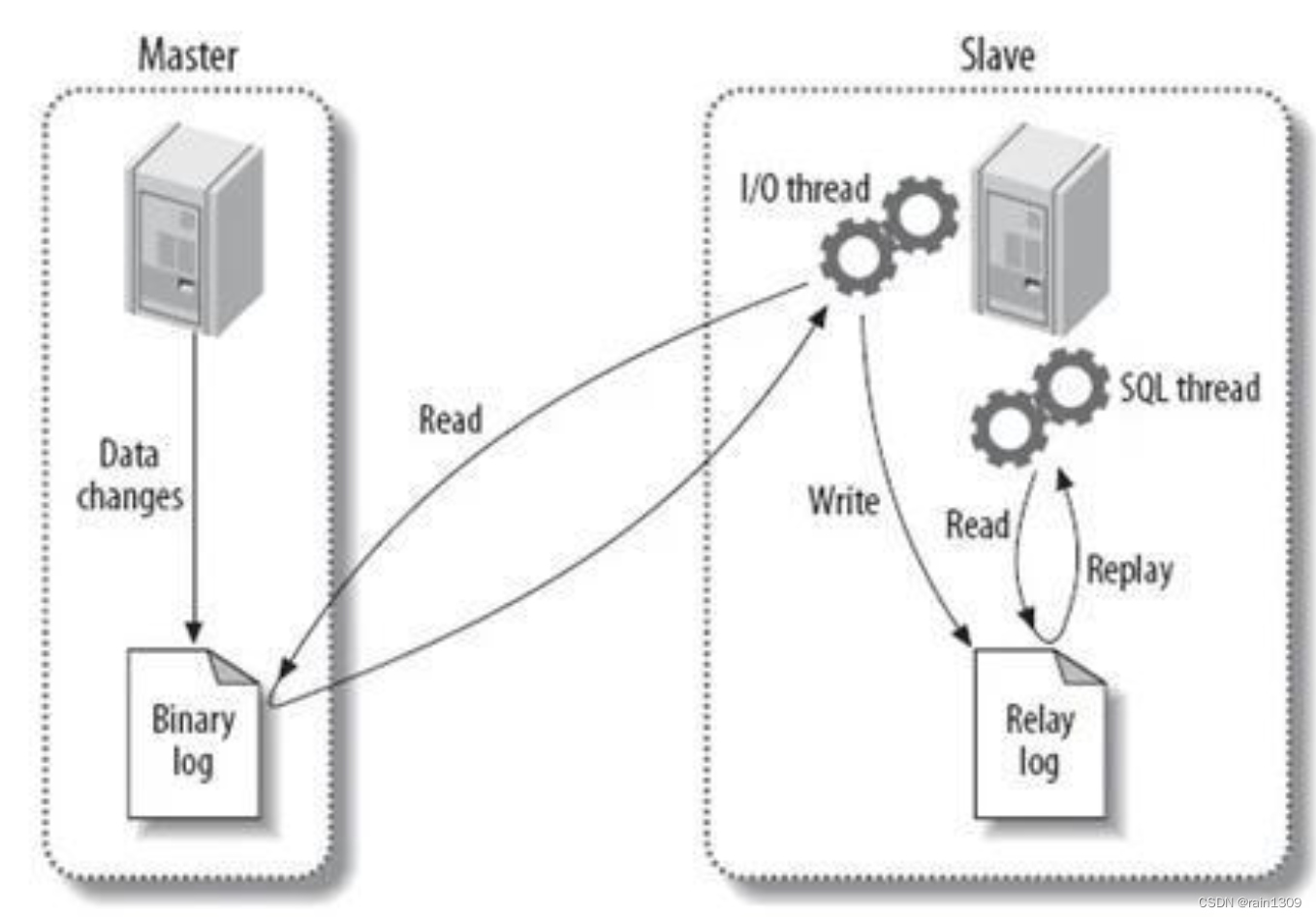
一、前言
项目中有使用到CUDA计算的相关内容。但是在早期CUDA计算环境搭建的过程中,并不是非常顺利,编写此篇文章记录下。对于刚刚开始研究的你可能会有一定的帮助。
二、环境搭建
搭建 CUDA 计算环境涉及到几个关键步骤,包括安装适当的 CUDA 驱动程序和工具包、设置开发环境和编译器,以及编写和运行 CUDA 程序。感谢Davis lee详细的介绍 CUDA安装及环境配置——最新详细版以下是一个基本的搭建过程:
步骤 1:检查硬件兼容性
首先,确保的计算机上的 GPU 支持 CUDA。可以在 NVIDIA 的官方网站上查找 GPU 的型号以确定其是否支持 CUDA。
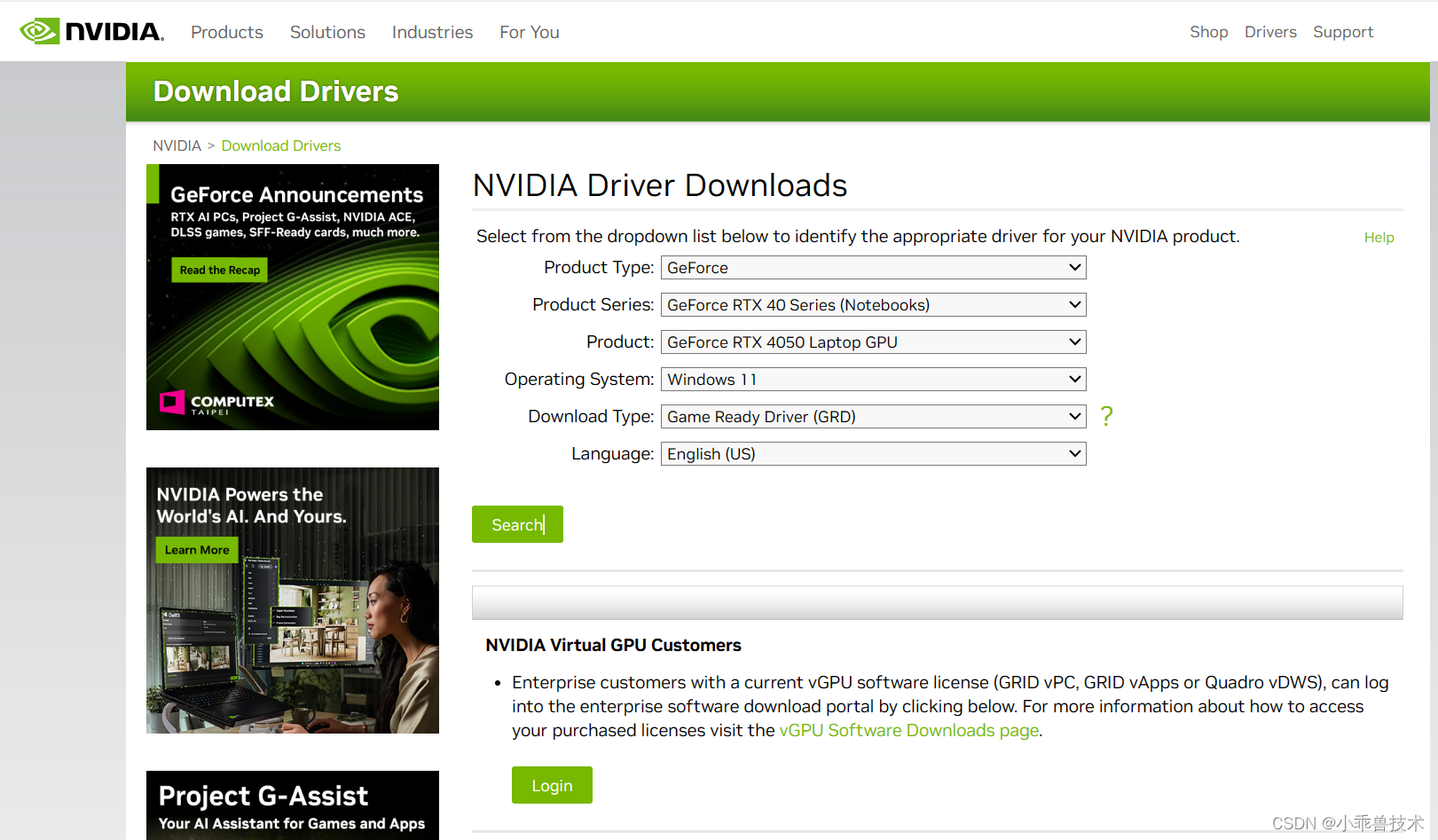
步骤 2:安装 CUDA 驱动程序
访问 NVIDIA 的官方网站,下载并安装与你的 GPU 兼容的最新 CUDA 驱动程序。安装过程中,根据向导提示进行操作。
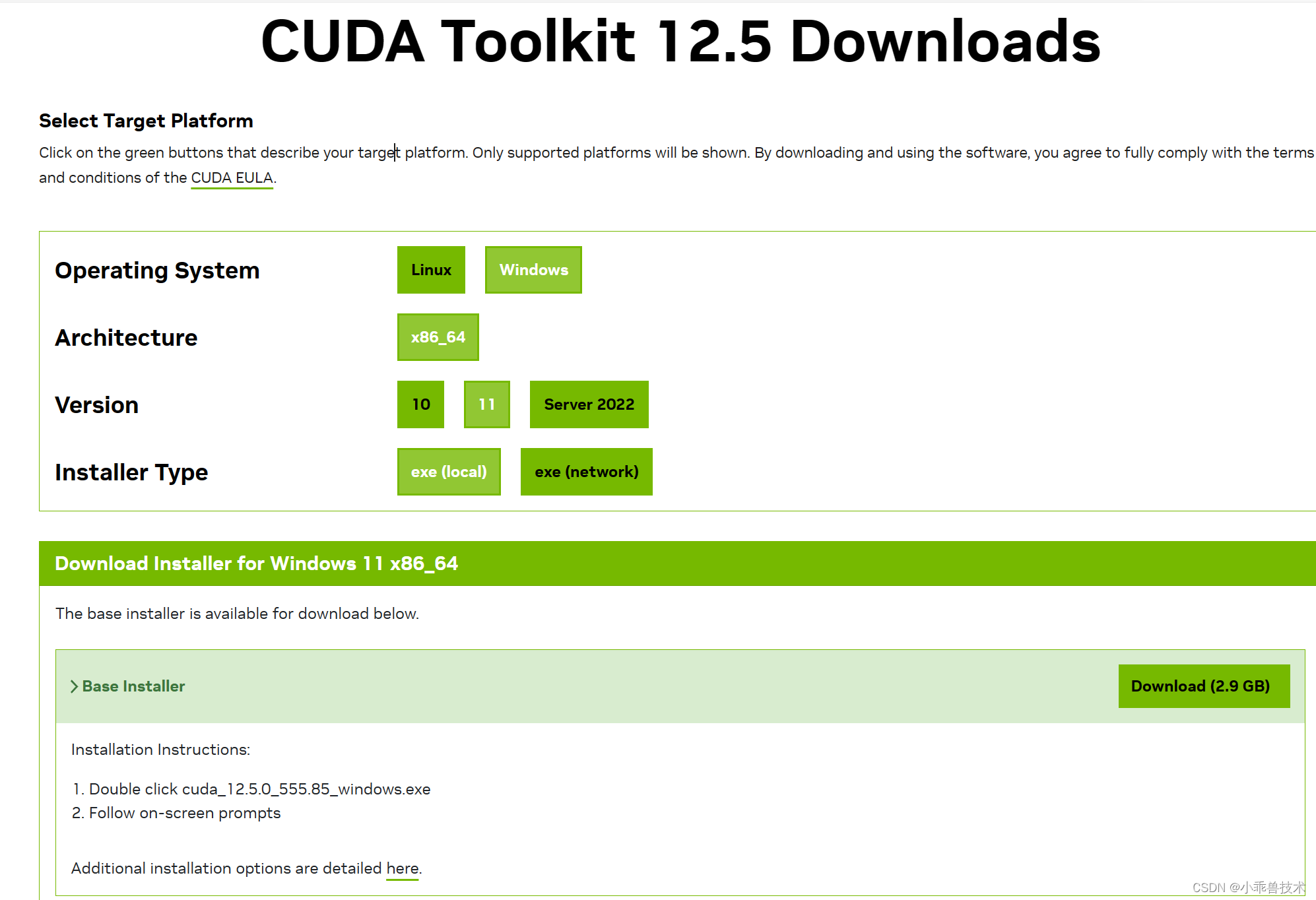
步骤 3:安装 CUDA 工具包
下载并安装与你的 CUDA 驱动程序版本相匹配的 CUDA 工具包。CUDA 工具包中包含了编译器、库和工具,用于开发和运行 CUDA 程序。
https://developer.nvidia.com/cuda-downloads
步骤 4:安装适当的开发环境
你可以使用多种开发环境来编写 CUDA 程序,如 NVIDIA 提供的 CUDA Toolkit 中自带的 nvcc 编译器,或者集成了 CUDA 开发支持的 IDE,如 Visual Studio(需要安装适当的 CUDA 插件)或 JetBrains 的 CLion 等。
步骤 5:设置环境变量
在你的操作系统中设置 CUDA 相关的环境变量,包括 PATH、CUDA_PATH 等,以便系统可以找到 CUDA 工具和库。
步骤 6:编写和编译 CUDA 程序
使用你选择的开发环境编写 CUDA 程序,并使用 CUDA 编译器(如 nvcc)编译程序。确保您的程序正确地链接了 CUDA 库,并且编译选项正确设置。
步骤 7:运行 CUDA 程序
将编译生成的可执行文件部署到你的计算机上,并在 CUDA 支持的环境中运行程序。你可能需要在程序运行时指定相应的 GPU 设备。
总之就是,在搭建时适配自己的电脑配置要求。做到最新即可。
三、实践编码过程
新增一个空的解决方案,我们命名为VectorProject.sln。
3.1 使用CUDA编写动态库
1、新增动态链接库 ,命名为VectorLibrary;
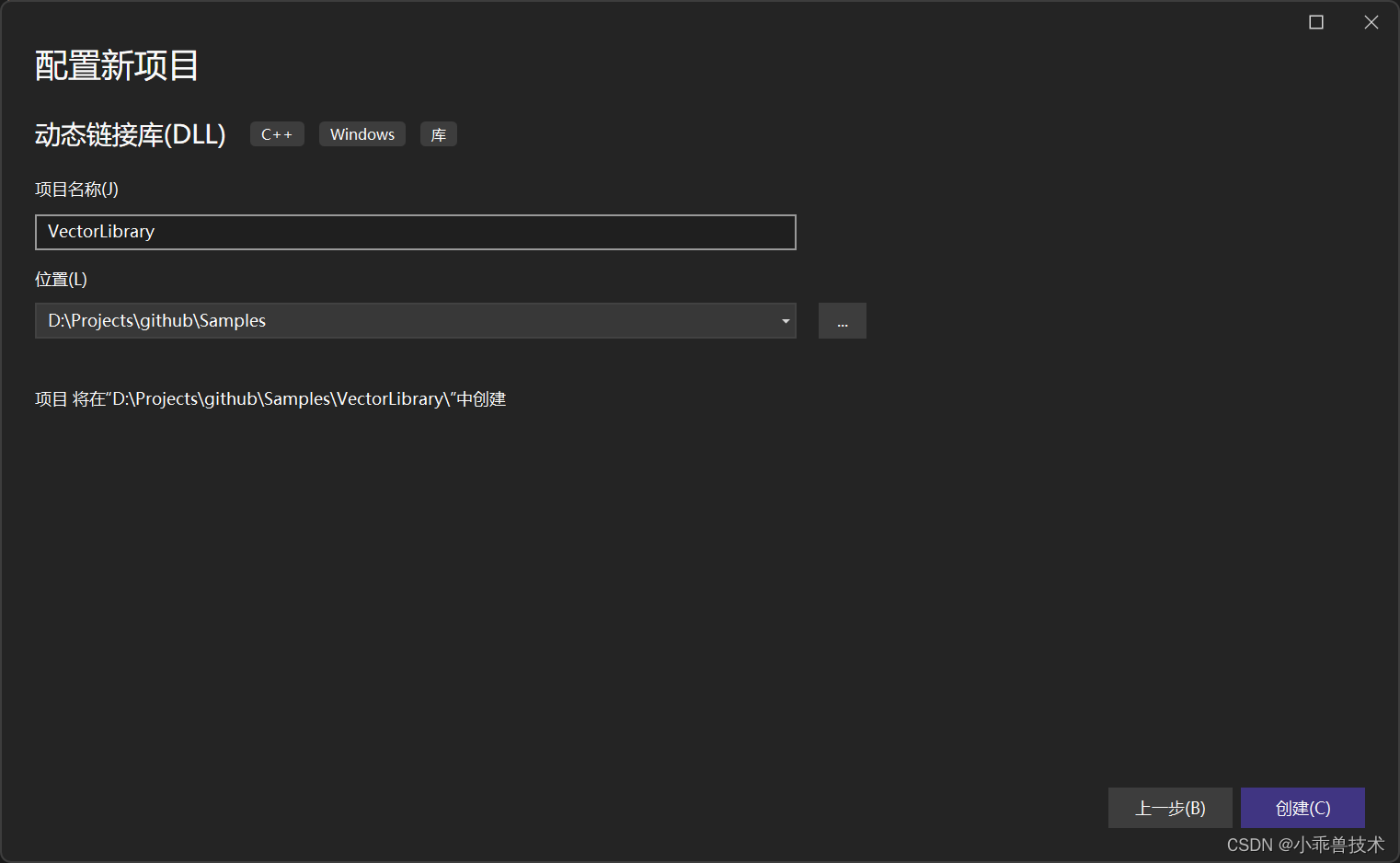
2、配置CUDA编译环境:
生成依赖项–>生成自定义
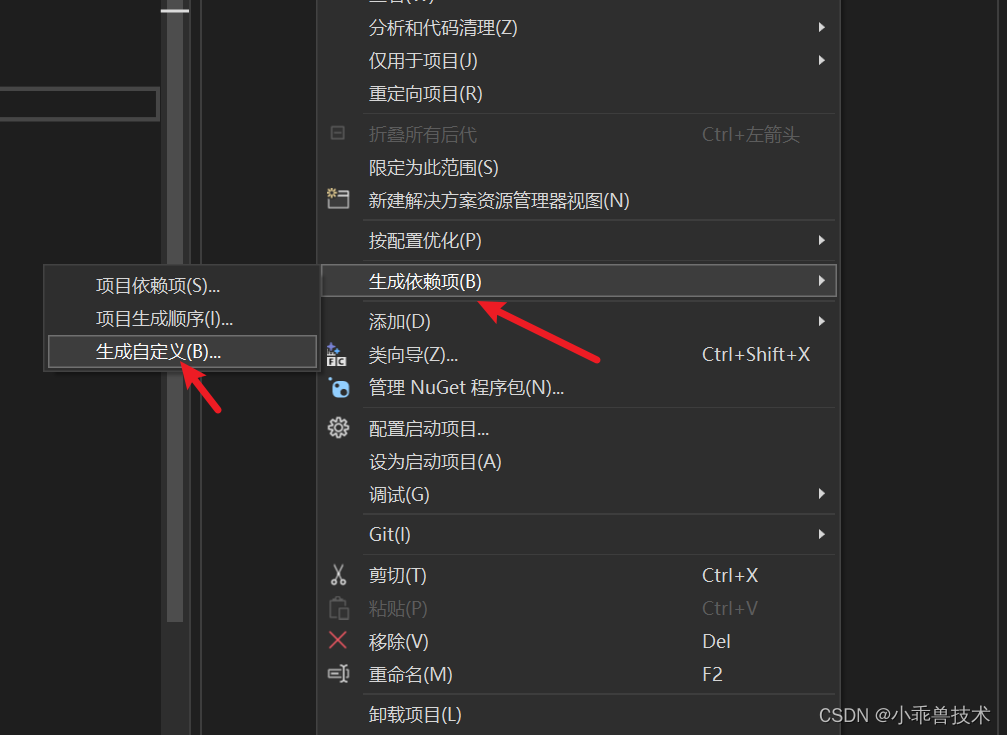
选择CUDA 12.3(targets,props)
这里如果不配置CUDA编译环境,会报错,无法正常编译通过的。配置完成后,可以查看项目的属性页。能看到CUDA C/C++配置部分
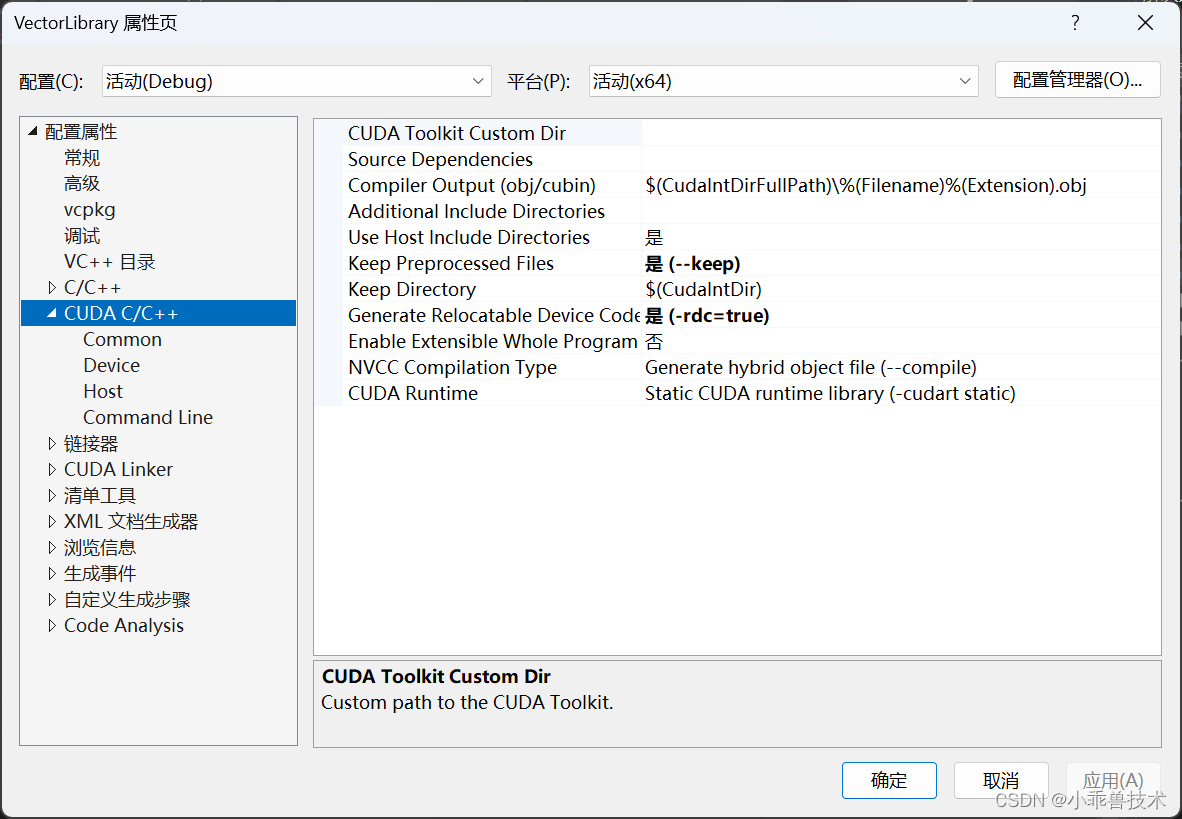
3、编写接口代码
这里主要定义两个向量的加法运算。
#pragma once
#include "pch.h"
#include <Windows.h>
#ifdef VECTOR_LIBRARY_EXPORTS
#define VECTOR_LIBRARY_API __declspec(dllexport)
#else
#define VECTOR_LIBRARY_API __declspec(dllimport)
#endif
BOOL VECTOR_LIBRARY_API vectorAddCPU(const float* A, const float* B, float* C, int N);
BOOL VECTOR_LIBRARY_API vectorAddGPU(const float* A, const float* B, float* C, int N);
4、编写CPU方法实现过程
// 封装CUDA函数的C++代码
#include "pch.h"
#include "vectorAdd.h"
// CPU上的向量加法函数
BOOL vectorAddCPU(const float* A, const float* B, float* C, int N)
{
for (int i = 0; i < N; ++i) {
C[i] = A[i] + B[i];
}
return true;
}
5、编写GPU方法实现过程
新增一个核函数声明文件 kernelVectorAdd.cuh
#include <iostream>
void kernelVectorAdd(const float* A, const float* B, float* C, int N);
编写核函数实现
#include <cuda_runtime.h>
#include <iostream>
#include <vector>
#include <device_launch_parameters.h>
#include "kernelVectorAdd.cuh"
// CUDA核函数:在GPU上执行的向量加法
__global__ void kernelVectorAddImp(const float* A, const float* B, float* C, int N) {
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < N) {
C[i] = A[i] + B[i];
}
}
void kernelVectorAdd(const float* A, const float* B, float* C, int N) {
float* d_A, * d_B, * d_C;
size_t size = N * sizeof(float);
// 分配设备内存
cudaMalloc(&d_A, size);
cudaMalloc(&d_B, size);
cudaMalloc(&d_C, size);
// 将数据从主机内存复制到设备内存
cudaMemcpy(d_A, A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, B, size, cudaMemcpyHostToDevice);
// 执行CUDA核函数
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
kernelVectorAddImp <<<blocksPerGrid, threadsPerBlock >>> (d_A, d_B, d_C, N);
// 等待所有CUDA核函数执行完毕
cudaDeviceSynchronize();
// 将结果从设备内存复制回主机内存
cudaMemcpy(C, d_C, size, cudaMemcpyDeviceToHost);
// 释放设备内存
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
}
在编写核函数调用的C++代码
// 封装CUDA函数的C++代码
#include "pch.h"
#include "kernelVectorAdd.cuh"
#include "vectorAdd.h"
BOOL vectorAddGPU(const float* A, const float* B, float* C, int N) {
kernelVectorAdd(A, B, C, N);
return true;
}
这里需要把核函数进行封装,否则会报错,相关解决办法可见 关于CUDA C 项目中“ error C2059: 语法错误:“<” ”问题的解决方法.
6、现在我们编译下项目
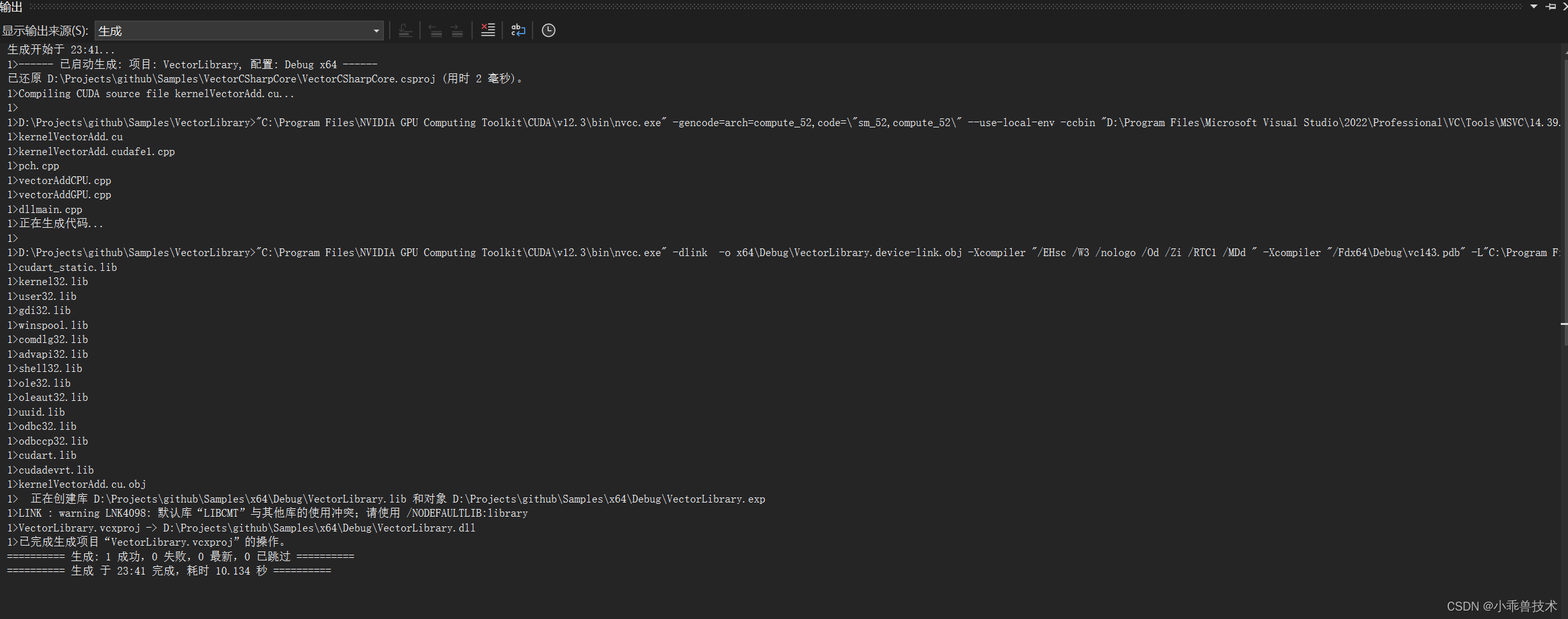
3.2 编写C++控制台程序
1、新增C++控制台程序,VectorCpp
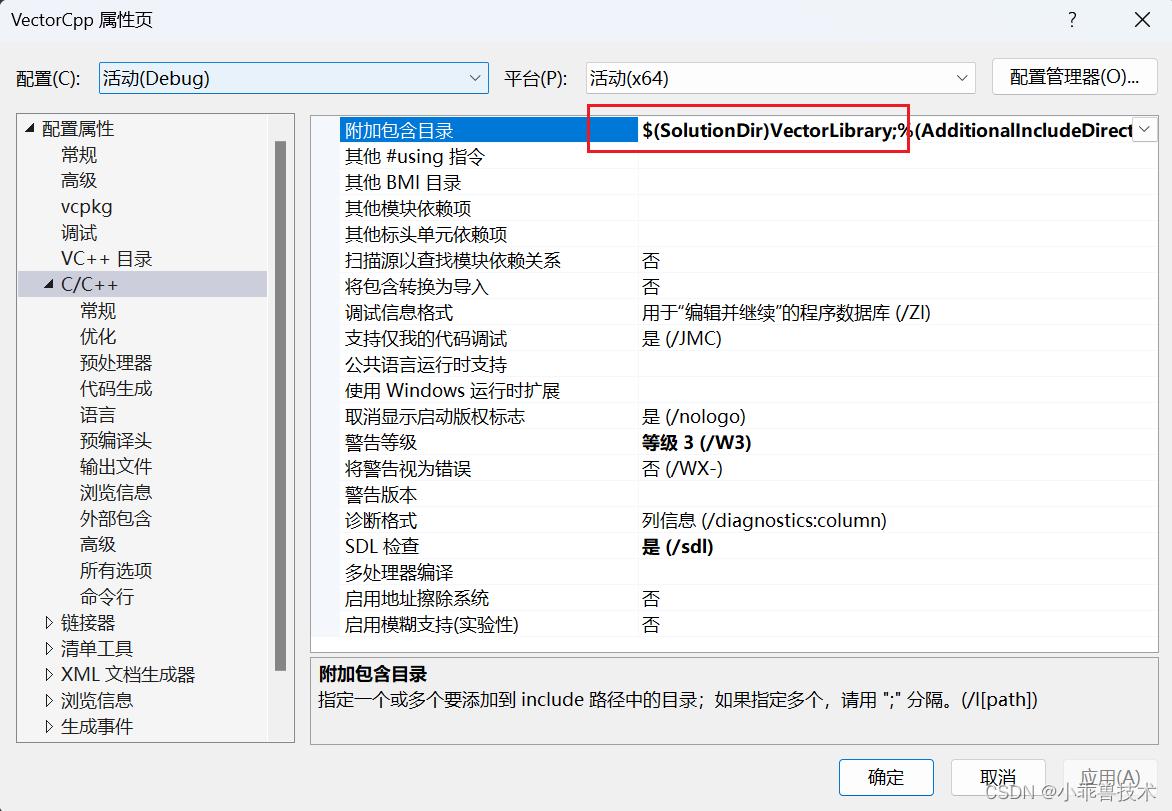
2、配置VectorLibrary.dll的引用
打开属性页,找到C/C++目录,附加包含目录添加配置
$(SolutionDir)VectorLibrary;
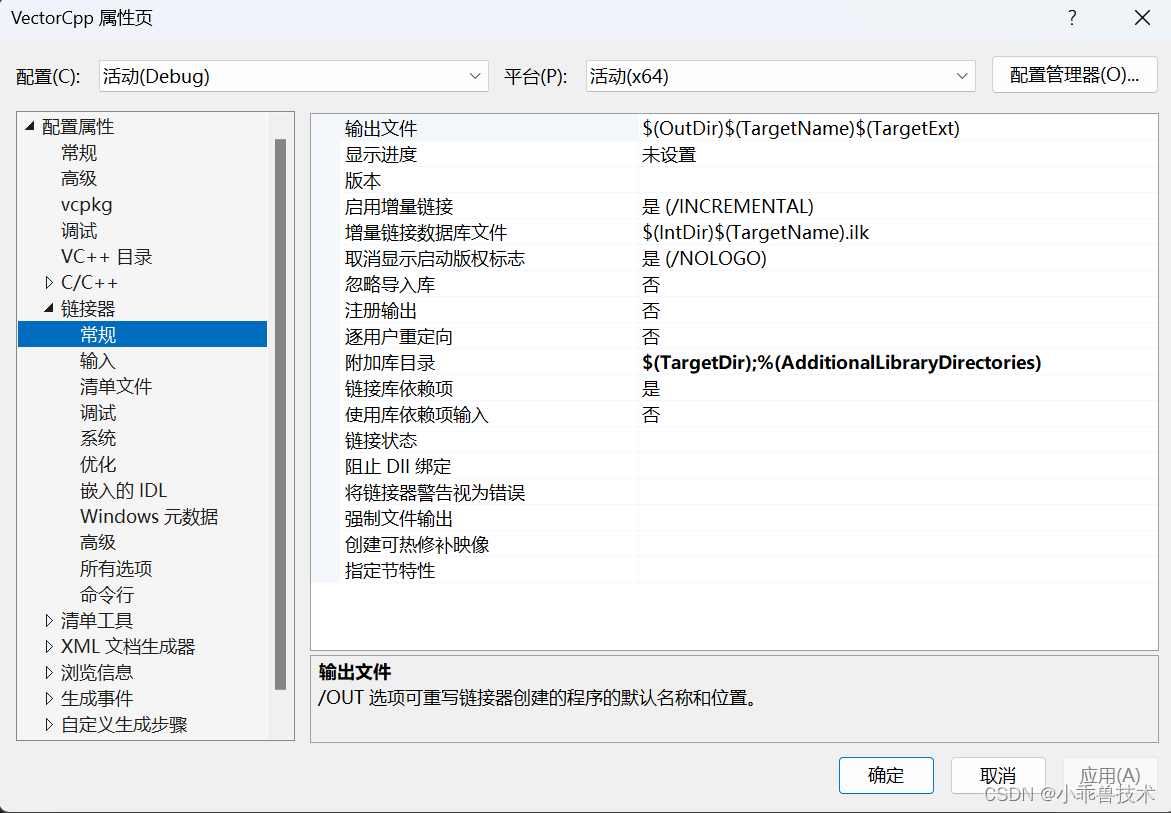
链接器–>常规–>附加库目录
$(TargetDir);%(AdditionalLibraryDirectories)
链接器–>输入–>附加依赖项
VectorLibrary.lib;%(AdditionalDependencies)
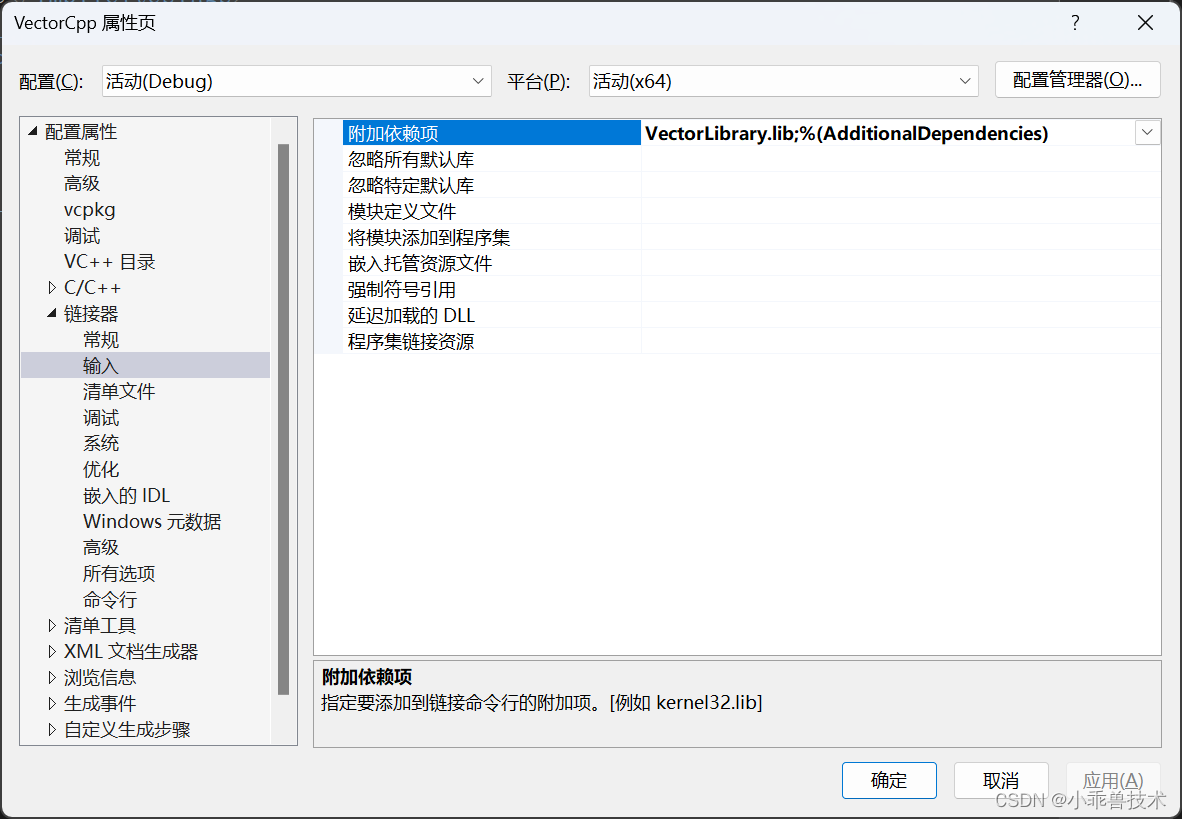
配置完成这些,就可以对VectorLibrary.dll正常引用了。
2、编写调用代码
// CudaWrapper.cpp
#include "pch.h"
#include <iostream>
#include <random>
#include <chrono>
#include "vectorAdd.h"
// 生成随机数并填充到数组
void generateRandomNumbers(float* array, int N) {
unsigned seed = std::chrono::system_clock::now().time_since_epoch().count();
std::default_random_engine generator(seed);
std::uniform_real_distribution<float> distribution(0.0, 1.0); // 范围从0到1之间
for (int i = 0; i < N; ++i) {
array[i] = distribution(generator);
}
}
int main()
{
int N = 1000000;
float* pA = new float[N];
float* pB = new float[N];
float* pC_GPU = new float[N];
float* pC_CPU = new float[N];
// 为pA和pB生成随机数
generateRandomNumbers(pA, N);
generateRandomNumbers(pB, N);
// 测量 CPU 端向量加法函数的执行时间
auto start_cpu = std::chrono::high_resolution_clock::now();
vectorAddCPU(pA, pB, pC_CPU, N);
auto end_cpu = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> elapsed_cpu = end_cpu - start_cpu;
std::cout << "CPU 端向量加法函数的执行时间: " << elapsed_cpu.count() << " 秒" << std::endl;
// 测量 GPU 端向量加法函数的执行时间
auto start_gpu = std::chrono::high_resolution_clock::now();
vectorAddGPU(pA, pB, pC_GPU, N);
auto end_gpu = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> elapsed_gpu = end_gpu - start_gpu;
std::cout << "GPU 端向量加法函数的执行时间: " << elapsed_gpu.count() << " 秒" << std::endl;
// 验证结果
for (int i = 0; i < N; ++i)
{
if ((pC_CPU[i] - pC_GPU[i]) > 1e-5)
{
std::cout << "结果不匹配" << std::endl;
break;
}
}
std::cout << "结果匹配" << std::endl;
// 记得释放内存
delete[] pA;
delete[] pB;
delete[] pC_CPU;
delete[] pC_GPU;
return 0;
}
3、运行程序
完整的项目结构
运行结果
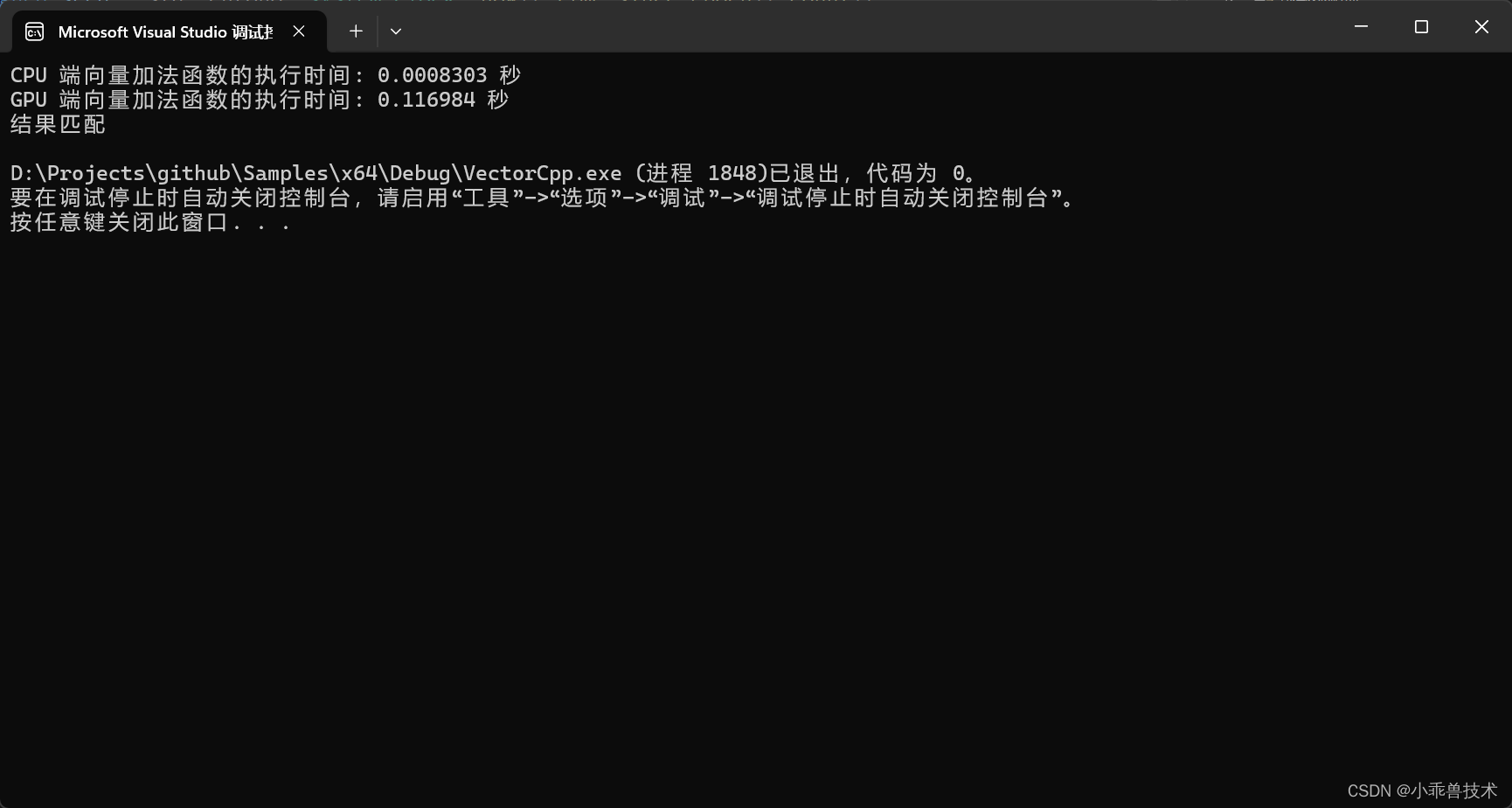
在这个示例中,成功运行得出结果。这个时候,你会发现为什么CPU的计算结果远远高于GPU。那是因为:
- 数据传输开销:在CUDA中,数据必须在主机(CPU)和设备(GPU)之间进行传输。在每次调用CUDA函数之前和之后,都需要将数据从主机内存复制到设备内存,然后将结果从设备内存复制回主机内存。这些数据传输的开销会降低CUDA的性能,特别是当数据量较大时。
- Kernel调用开销:在CUDA中,每次调用核函数都需要一定的开销,包括启动核函数、将数据传递给核函数、核函数在GPU上执行等。如果向量大小较小,核函数的启动开销可能会占据相当大的比例,从而降低CUDA的性能。
- 并行化效率不佳:在某些情况下,CUDA核函数可能无法充分利用GPU的并行计算能力。这可能是因为向量大小太小,无法充分填充GPU的计算单元,或者核函数的计算密度不够高,无法实现最大的并行化效率。
- 内存访问模式:CUDA核函数的性能受到内存访问模式的影响。如果核函数中的内存访问模式不利于GPU的缓存和内存访问优化,性能可能会受到影响。
究其根本原因就是,这个算法太简单了,CPU就可以搞定,用不上GPU。
四、总结
在这个项目中,我们主要体会框架的用法,以及CUDA计算环境搭建的。通过编码实践,构建项目成功实验了CUDA计算环境搭建,为接下来的工作准备好环境。
五、参考文档
错误 MSB4062 未能从程序集加载任务
VS加载CUDA项目出错:未找到导入的项目
整理:warning LNK4098: 默认库“LIBCMT”与其他库的使用冲突;请使用 /NODEFAULTLIB:library
Win10下在VS2019中配置使用CUDA进行加速的C++项目 (配置.h文件,.dll以及.lib文件等)