文章目录
- 一、BeautifulSoup介绍
- 二、安装
- 三、bs4数据解析的原理
- 四、bs4 常用的方法和属性
- 1、BeautifulSoup构建
- 1.1 通过字符串构建
- 1.2 从文件加载
- 2、BeautifulSoup四种对象
- 2.1 Tag对象
- 2.2 NavigableString对象
- 2.3 BeautifulSoup对象
- 2.4 Comment对象
- 五、contents、children与descendants
- 六、parent、parents
- 七、next_sibling、previous_sibling
- 八、 next_element、previous_element
- 九、find()和find_all()
- 9.1 方法
- 9.2 tag名称
- 9.3 属性
- 9.4 正则表达式
- 9.5 函数
- 9.6 文本
- 十、select()和select_one()
- 10.1 通过tag选择
- 10.2 id和class选择器
- 10.3 属性选择器
- 10.4 其他选择器
- 十一、结合实战
- 十二、CSS选择器
- 12.1 常用选择器
- 12.2 位置选择器
- 12.3 其他选择器
- 十三、使用总结
一、BeautifulSoup介绍
BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python库。Beautiful Soup 已成为和 lxml、html5lib 一样出色的Python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
BeautifulSoup官方文档:BeautifulSoup
二、安装
pip install bs4 # 下载BeautifulSoup包
pip install lxml # 下载lxml包
解析器的使用方法和优缺点比较
#标准库的使用方法
BeautifulSoup(html,'html.parser')
#优势:内置标准库,速度适中,文档容错能力强
#劣势:Python3.2版本前的文档容错能力差
#lxml HTML的使用方法
BeautifulSoup(html,'lxml')
#优势:速度快,文档容错能力强
#劣势:需要安装C语言库
#lxml XML的使用方法
BeautifulSoup(html,'xml')
#优势:速度快,唯一支持XML
#劣势:需要安装C语言库
#html5lib的使用方法
BeautifulSoup(html,'html5lib')
#优势:容错性最强,可生成HTML5
#劣势:运行慢,不依赖外部扩展
爬虫解析器汇总
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(html, “html.parser”) | 内置标准库,速度适中,文档容错能力强 | Python3.2版本前的文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(html,‘lxml’) | 速度快,文档容错能力强 | 需要安装C语言库 |
| lxml XML解析器 | BeautifulSoup(markup, “xml”) | 速度快、唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(html,‘html5lib’) | 容错性最强,可生成HTML5格式文档 | 运行慢,不依赖外部扩展 |
三、bs4数据解析的原理
- 实例化一个BeautifulSoup对象,并且将页面源码数据加载到该对象中。
- 通过调用BeautifulSoup对象中相关的属性或者方法进行标签定位和数据提取。
四、bs4 常用的方法和属性
1、BeautifulSoup构建
1.1 通过字符串构建
from bs4 import BeautifulSoup
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div id="container">
<span class="title">
<h3>Python爬虫网页解析神器BeautifulSoup详细讲解</h3>
</span>
</div>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
# 打印soup对象的内容,格式化输出
print(soup.prettify())
格式化打印html对象的内容,这个函数以后会经常用到。
1.2 从文件加载
from bs4 import BeautifulSoup
with open(r"D:\index.html") as fp:
soup = BeautifulSoup(fp, "lxml")
print(soup.prettify())
2、BeautifulSoup四种对象
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:Tag、NavigableString、BeautifulSoup、Comment
2.1 Tag对象
Tag对象又包括string、strings、stripped_strings
若一个节点只包含文本,可通过string直接访问该节点的文本,例如:
from bs4 import BeautifulSoup
html = """
<title>The Kevin's story house</title>
<span>这里是王菜鸟的Python系列文章</span>
<a href="https://token.blog.csdn.net/">王菜鸟的博客</a
"""
soup = BeautifulSoup(html, 'html.parser')
print(soup.title.text)
print(soup.span.text)
print(soup.a['href'])
# 输出结果
The Kevin's story house
这里是王菜鸟的Python系列文章
https://token.blog.csdn.net/
以上这种方式查找的是所有内容中第一个符合要求的标签,而对于Tag,它有两个重要的属性,name和attrs
print(soup.p.attrs) # 此处获取的是p标签的所有属性,得到的类型是一个字典
print(soup.p['class']) # 单独获取某个属性
print(soup.p.get('class')) # 同上,单独获取某个属性
# 输出结果
{'class': ['link']}
['link']
['link']
对于这些属性和内容进行修改:
soup.p['class'] = "newClass"
print(soup)
# 输出结果
<title>The Kevin's story house</title>
<span>这里是王菜鸟的Python系列文章</span>
<p class="newClass">
<a href="https://token.blog.csdn.net/">王菜鸟的博客</a>
</p>
此外,还可以删除某个属性:
del soup.p['class']
print(soup)
# 输出结果
<title>The Kevin's story house</title>
<span>这里是王菜鸟的Python系列文章</span>
<p>
<a href="https://token.blog.csdn.net/">王菜鸟的博客</a>
</p>
tag.attrs是一个字典类型,可以通过tag.get('id')或者tag.get('class')两种方式,如果id或class属性不存在,则返回None。下标访问的方式可能会抛出异常KeyError。
其次可以使用get_text()获取文本节点
# 获取所有文本内容
soup.get_text()
# 可以指定不同节点之间的文本使用|分割。
soup.get_text("|")
# 可以指定去除空格
soup.get_text("|", strip=True)
2.2 NavigableString对象
若想获取标签里的内容,可以使用.string来获取
print(soup.a.string)
print(type(soup.a.string))
# 输出结果
王菜鸟的博客
<class 'bs4.element.NavigableString'>
2.3 BeautifulSoup对象
BeautifulSoup对象表示是一个文档的全部内容,大部分的时候可以把它当作一个Tag标签来使用,是一个特殊的Tag,可以分别来获取它的类型名称:
print(soup.name)
print(type(soup.name))
print(soup.attrs)
# 输出结果
[document]
<class 'str'>
{}
2.4 Comment对象
Comment对象是一个特殊类型的NavigableString对象,输出的内容仍然不包括注释符号。
五、contents、children与descendants
contents、children与descendants都是节点的子节点,不过
- contents是列表
- children是生成器
注意:contents、children只包含直接子节点,descendants也是一个生成器,不过包含节点的子孙节点。
子节点的举例:
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html, 'lxml')
print(soup.p.contents)
print(type(soup.p.contents))
# 输出结果
['\n Once upon a time there were three little sisters; and their names were\n ', <a class="sister" href="http://example.com/elsie" id="link1">
<span>Elsie</span>
</a>, '\n', <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, ' \n and\n ', <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>, '\n and they lived at the bottom of a well.\n ']
<class 'list'>
子孙节点的举例:
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html, 'lxml')
print(soup.p.descendants)
for i, child in enumerate(soup.p.descendants):
print(i, child)
六、parent、parents
- parent:父节点
- parents:递归父节点
父节点举例:
from bs4 import BeautifulSoup
html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html, 'lxml')
print(soup.span.parent)
递归父节点举例
html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(list(enumerate(soup.a.parents)))
七、next_sibling、previous_sibling
- next_sibling:后一个兄弟节点
- previous_sibling:前一个兄弟节点
兄弟节点举例
html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(list(enumerate(soup.a.next_siblings)))
print(list(enumerate(soup.a.previous_siblings)))
八、 next_element、previous_element
next_element:后一个节点
previous_element:前一个节点
next_element与next_sibling的区别是:
- next_sibling从当前tag的结束标签开始解析
- next_element从当前tag的开始标签开始解析
九、find()和find_all()
9.1 方法
find_parent:查找父节点
find_parents:递归查找父节点
find_next_siblings:查找后面的兄弟节点
find_next_sibling:查找后面满足条件的第一个兄弟节点
find_all_next:查找后面所有节点
find_next:查找后面第一个满足条件的节点
find_all_previous:查找前面所有满足条件的节点
find_previous:查找前面第一个满足条件的节点
9.2 tag名称
# 查找所有p节点
soup.find_all('p')
# 查找title节点,不递归
soup.find_all("title", recursive=False)
# 查找p节点和span节点
soup.find_all(["p", "span"])
# 查找第一个a节点,和下面一个find等价
soup.find_all("a", limit=1)
soup.find('a')
9.3 属性
# 查找id为id1的节点
soup.find_all(id='id1')
# 查找name属性为tim的节点
soup.find_all(name="tim")
soup.find_all(attrs={"name": "tim"})
#查找class为clazz的p节点
soup.find_all("p", "clazz")
soup.find_all("p", class_="clazz")
soup.find_all("p", class_="body strikeout")
9.4 正则表达式
import re
# 查找与p开头的节点
soup.find_all(class_=re.compile("^p"))
9.5 函数
# 查找有class属性并且没有id属性的节点
soup.find_all(hasClassNoId)
def hasClassNoId(tag):
return tag.has_attr('class') and not tag.has_attr('id')
9.6 文本
# 查找有class属性并且没有id属性的节点
soup.find_all(hasClassNoId)
def hasClassNoId(tag):
return tag.has_attr('class') and not tag.has_attr('id')
十、select()和select_one()
select()是选择满足所有条件的元素,select_one()只选择满足条件的第一个元素。
select()的重点在于选择器上,CSS的选择器又分为id选择器和class选择器,标签名不加任何修饰,类名前加点,id名前加#。在此使用类似的方法来筛选元素。
10.1 通过tag选择
通过tag选择非常简单,就是按层级,通过tag的名称使用空格分割就可以了。
# 选择title节点
soup.select("title")
# 选择body节点下的所有a节点
soup.select("body a")
# 选择html节点下的head节点下的title节点
soup.select("html head title")
10.2 id和class选择器
id和类选择器也比较简单,类选择器使用.开头,id选择器使用#开头。
# 选择类名为article的节点
soup.select(".article")
# 选择id为id1的a节点
soup.select("a#id1")
# 选择id为id1的节点
soup.select("#id1")
# 选择id为id1、id2的节点
soup.select("#id1,#id2")
10.3 属性选择器
# 选择有href属性的a节点
soup.select('a[href]')
# 选择href属性为http://mycollege.vip/tim的a节点
soup.select('a[href="http://mycollege.vip/tim"]')
# 选择href以http://mycollege.vip/开头的a节点
soup.select('a[href^="http://mycollege.vip/"]')
# 选择href以png结尾的a节点
soup.select('a[href$="png"]')
# 选择href属性包含china的a节点
soup.select('a[href*="china"]')
# 选择href属性包含china的a节点
soup.select("a[href~=china]")
10.4 其他选择器
# 父节点为div节点的p节点
soup.select("div > p")
# 节点之前有div节点的p节点
soup.select("div + p")
# p节点之后的ul节点(p和ul有共同父节点)
soup.select("p~ul")
# 父节点中的第3个p节点
soup.select("p:nth-of-type(3)")
十一、结合实战
通过一个案例,来学习find()、find_all()、select()、select_one()的用法。
from bs4 import BeautifulSoup
text = '''
<li class="subject-item">
<div class="pic">
<a class="nbg" href="https://mycollege.vip/subject/25862578/">
<img class="" src="https://mycollege.vip/s27264181.jpg" width="90">
</a>
</div>
<div class="info">
<h2 class=""><a href="https://mycollege.vip/subject/25862578/" title="解忧杂货店">解忧杂货店</a></h2>
<div class="pub">[日] 东野圭吾 / 李盈春 / 南海出版公司 / 2014-5 / 39.50元</div>
<div class="star clearfix">
<span class="allstar45"></span>
<span class="rating_nums">8.5</span>
<span class="pl">
(537322人评价)
</span>
</div>
<p>现代人内心流失的东西,这家杂货店能帮你找回——僻静的街道旁有一家杂货店,只要写下烦恼投进卷帘门的投信口,
第二天就会在店后的牛奶箱里得到回答。因男友身患绝... </p>
</div>
</li>
'''
soup = BeautifulSoup(text, 'lxml')
print(soup.select_one("a.nbg").get("href"))
print(soup.find("img").get("src"))
title = soup.select_one("h2 a")
print(title.get("href"))
print(title.get("title"))
print(soup.find("div", class_="pub").string)
print(soup.find("span", class_="rating_nums").string)
print(soup.find("span", class_="pl").string.strip())
print(soup.find("p").string)
十二、CSS选择器
12.1 常用选择器
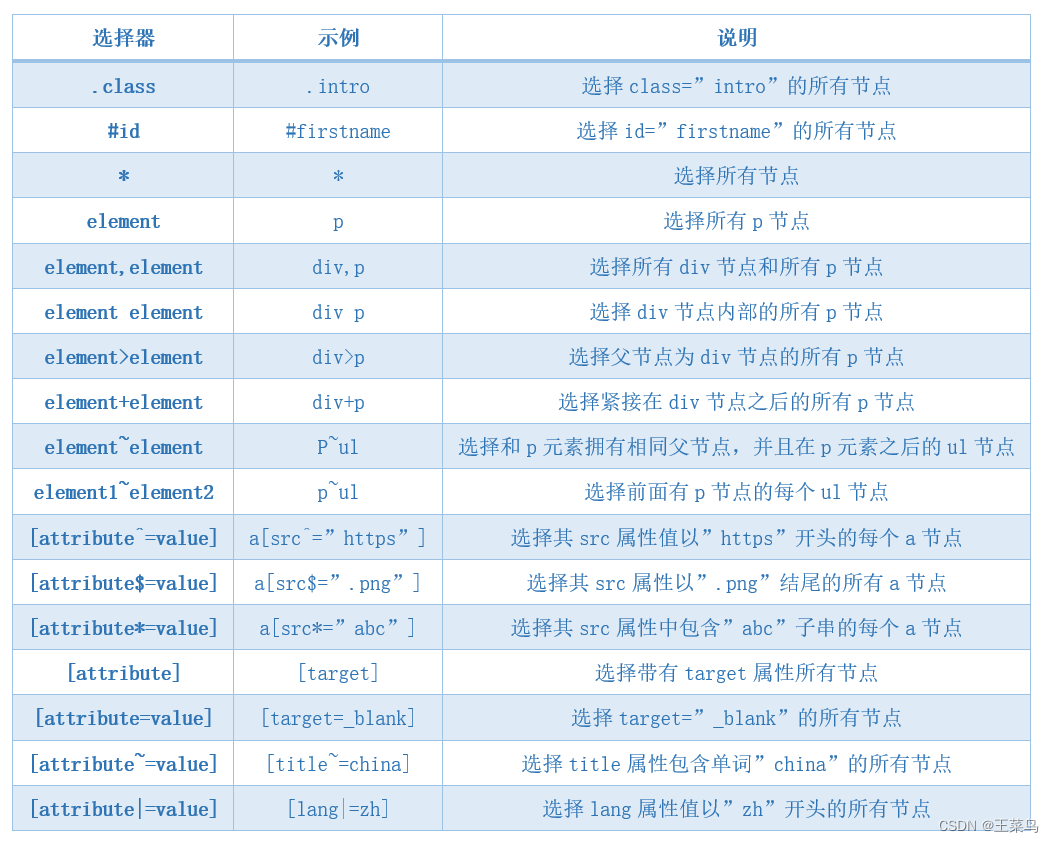
12.2 位置选择器
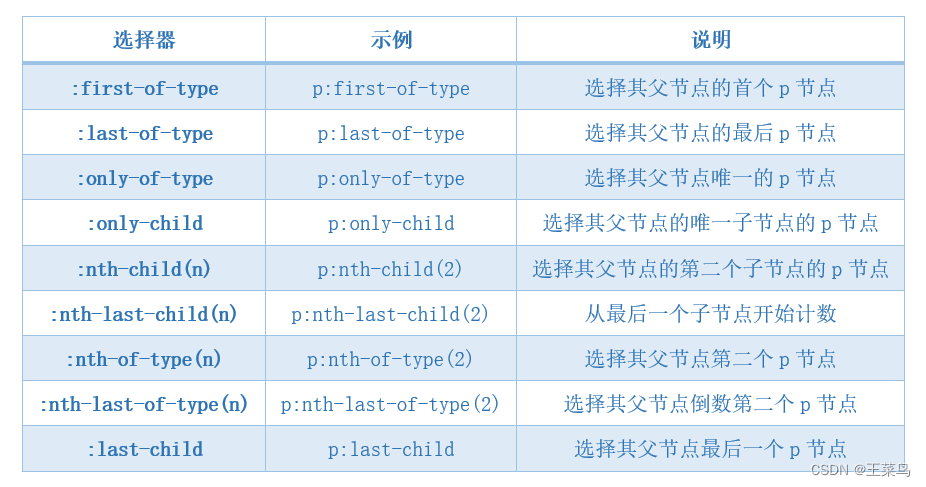
12.3 其他选择器
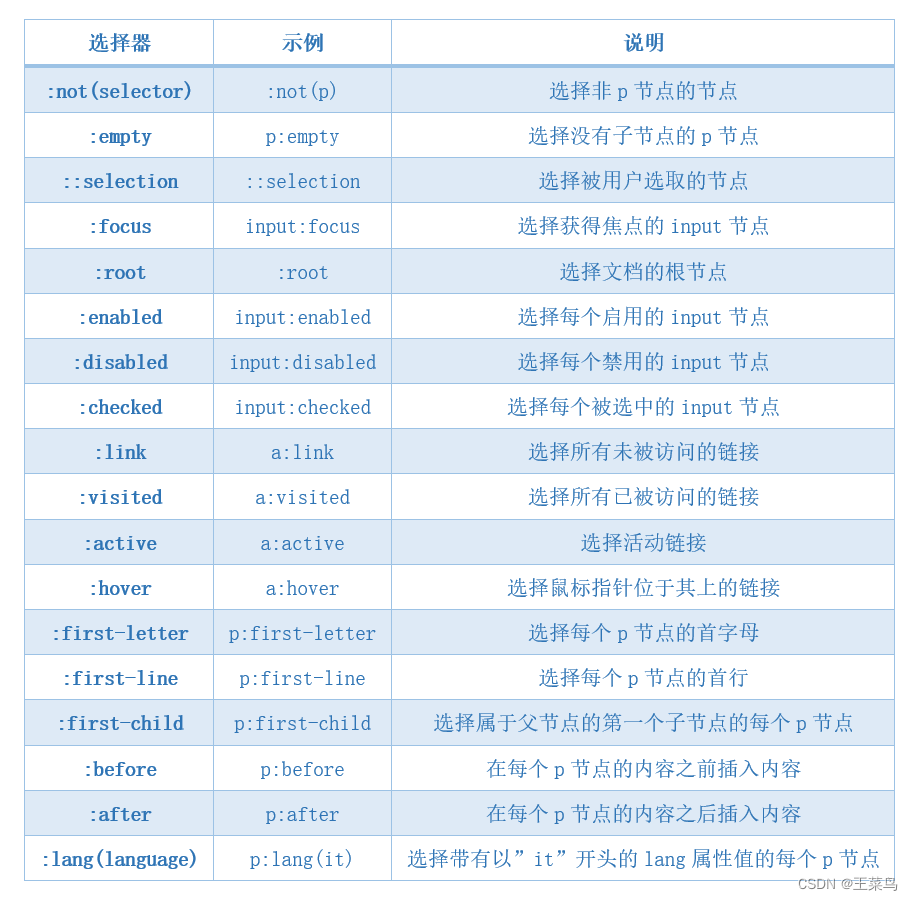
十三、使用总结
- 推荐使用
lxml解析库,必要时使用html.parser - 标签选择筛选功能弱但是速度快
- 建议使用
find()、find_all()查询匹配单个结果或者多个结果 - 如果对CSS选择器熟悉建议使用
select()、select_one() - 记住常用的获取属性和文本值的方法