文章目录
- 返回传播计算方法
- 神经网络整体架构(暂时留存,等后面补)
- 神经元个数对结果的影响
- 正则化与激活函数
- 神经网络过拟合解决方法
返回传播计算方法
实际上计算L(损失值)的时候并不是只是拿一组w来进行计算,而是由多组w进行相对应的计算,而每一组关注的重心是不一样的,举个例子,比如猫这个组,它可以由三组w进行相对应的计算再相加,第一组关注猫的胡子,第二组关注的是猫,而非背景板,第三组关注猫的眼睛,对于其的w更大。
梯度是一步步进行传播的。
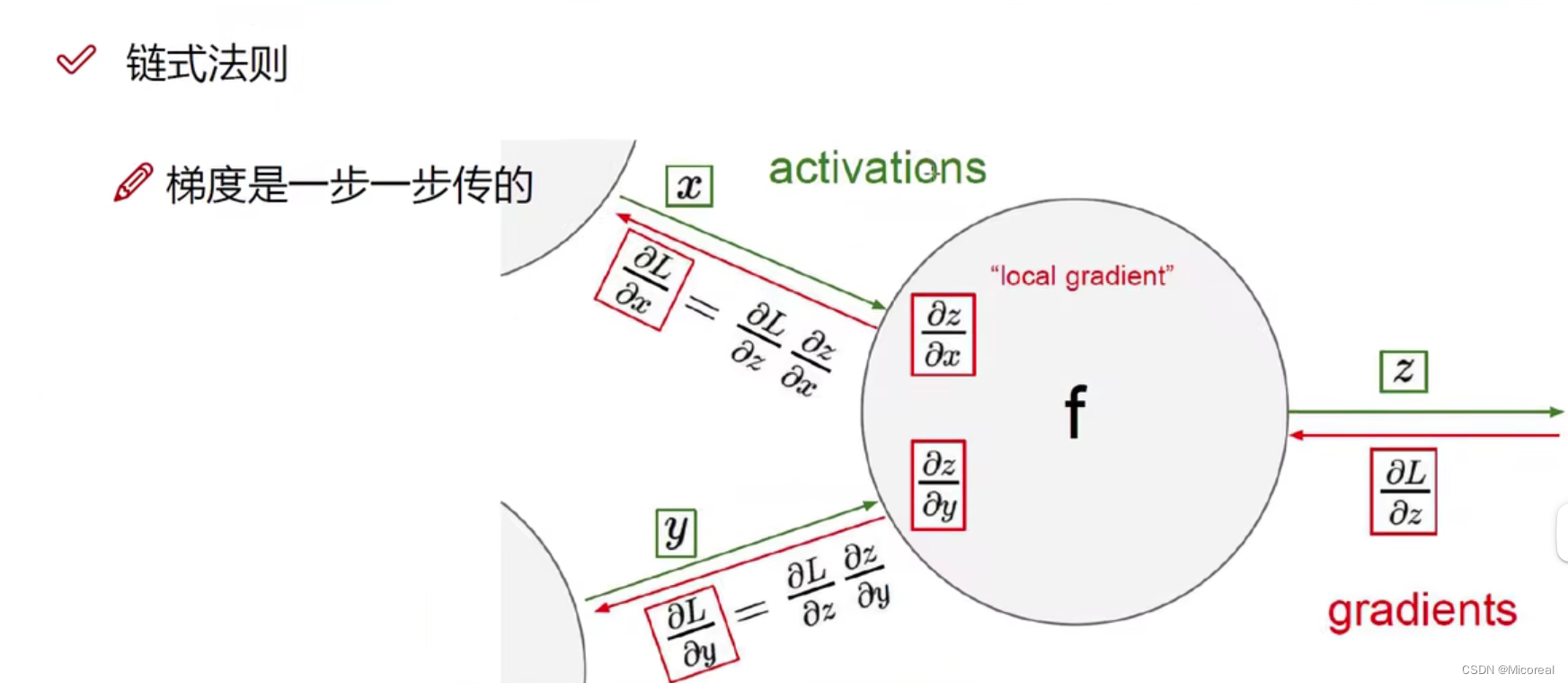
神经网络整体架构(暂时留存,等后面补)
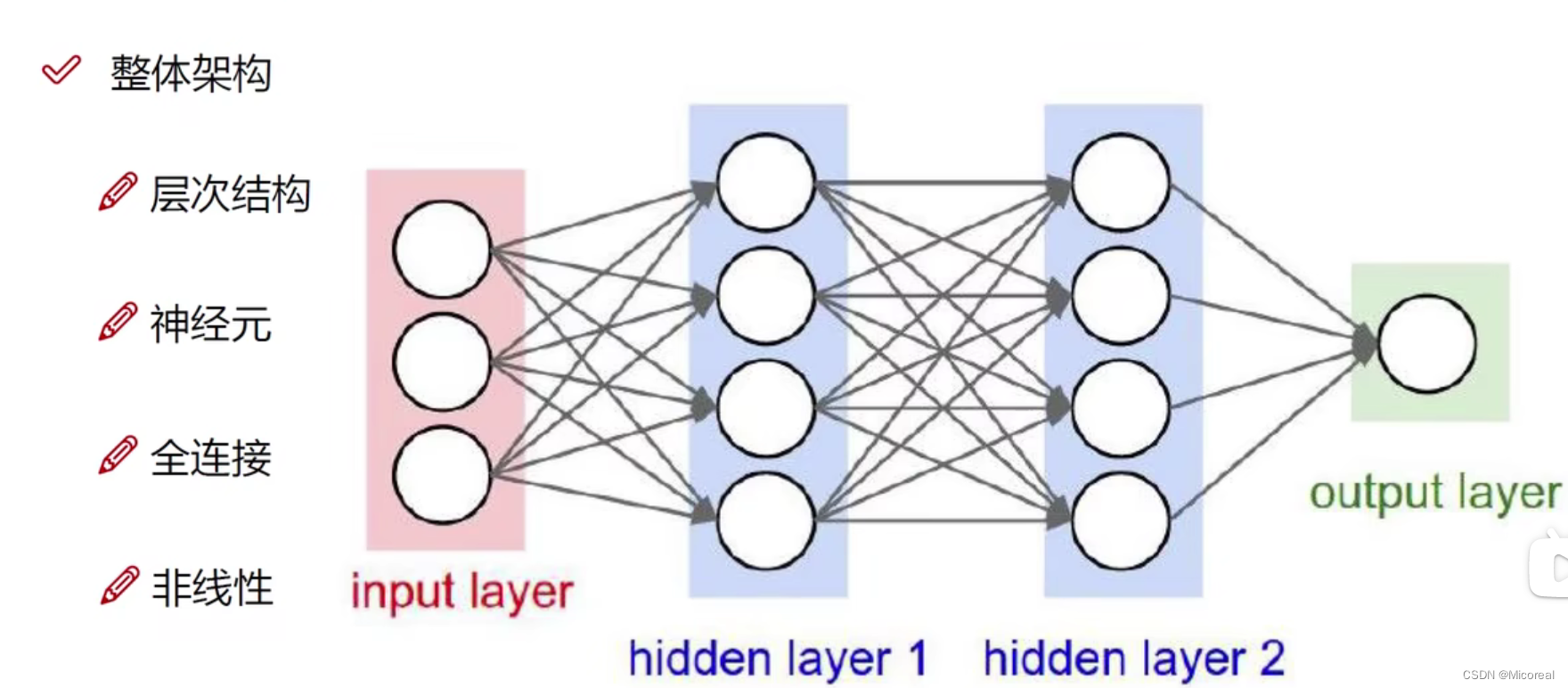
理解此图,正确说明此图
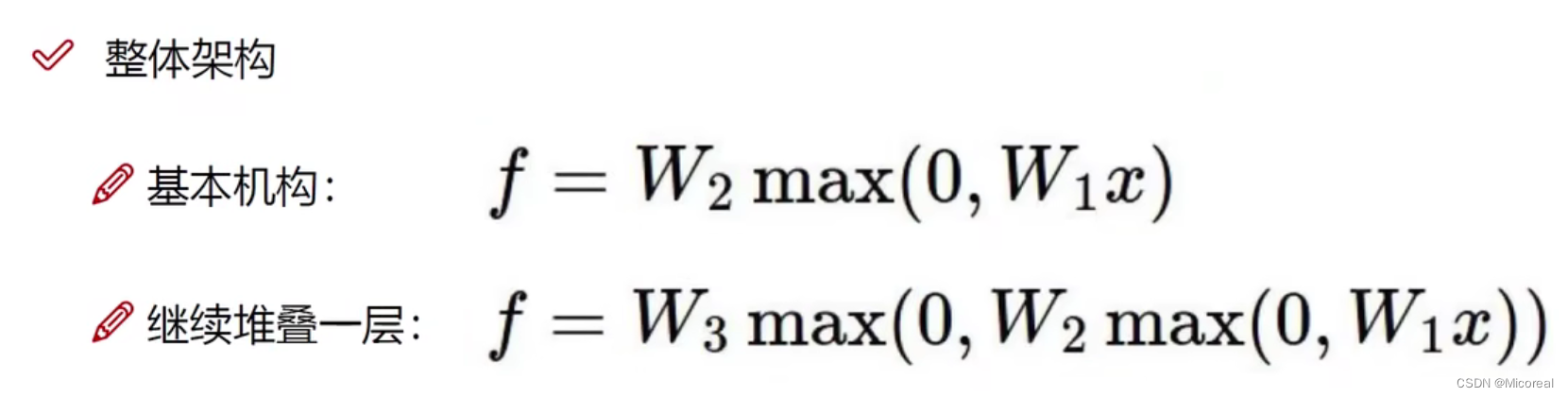
神经元个数对结果的影响
神经元个数越多,对于其结果的拟合程度越好。但是有时候却需要关注的是不需要那么高的拟合程度。
正则化与激活函数
惩罚力度越小越拟合。但容易出现极端数据。

而参数数量实际上也可以近似当作神经元个数,即参数数量越大,拟合程度越好。
激活函数(神经网络经过一些权重参数计算之后,需要的非线性计算变化):

现在已经不太使用sigmoid激活函数了,主要是因为在趋近于一的情况下,会导致其梯度为零,也即导致后续的求偏导的时候的计算也出现全部都是0的情况,与实际不一致。
现在百分之95以上都是使用relu激活函数。
神经网络过拟合解决方法
数据预处理:
不同的数据预处理会使得模型效果发生很大的差异。

参数初始化:
通常我们使用随机策略来进行参数初始化(0-1之间的数据)。
过拟合解决方法:
- 正则化
- DROP-OUT
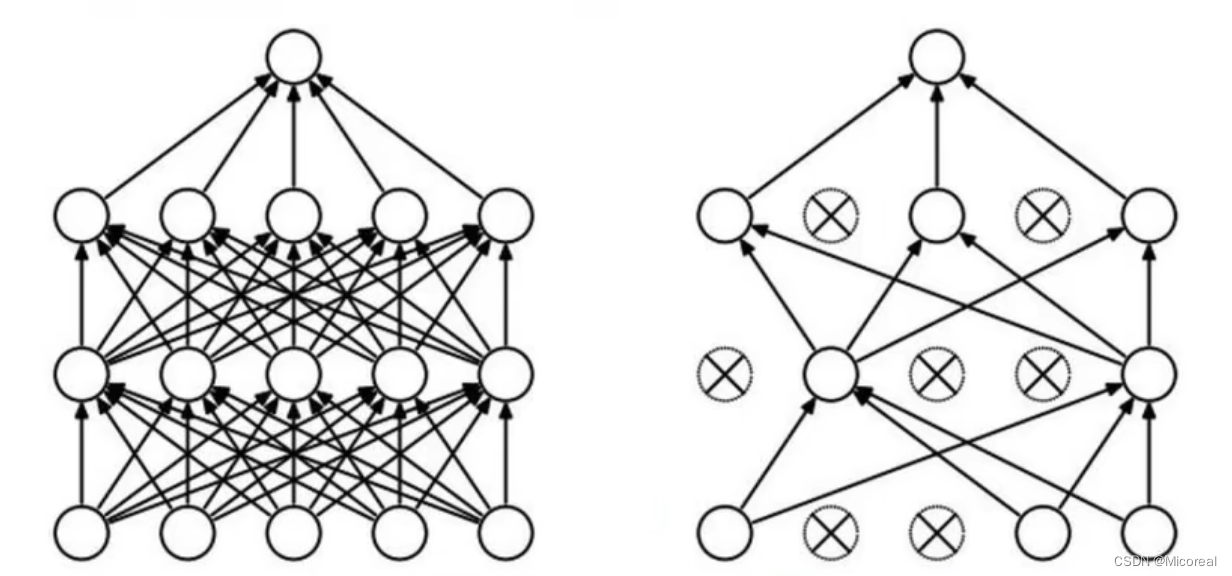
什么意思呢:就是在训练的过程中,随机杀死几个神经元点,不去使用它进行训练。然后在上万次的训练过程中,可以做到参数接近,而且减少过拟合现象。