小谈:一直想整理机器学习的相关笔记,但是一直在推脱,今天发现知识快忘却了(虽然学的也不是那么深),但还是浅浅整理一下吧,便于以后重新学习。
最近换到新版编辑器写文章了,有的操作挺方便的,但是😭我目前还没有找到在哪里插入目录。
1.机器学习的定义
机器学习专门研究计算机怎样模拟或实现人类的学习行为,以获取新知识或技能,重新组织已有的知识结构使之不断改善自己的性能。
机器学习是人工智能的一个分支。我们使用计算机设计一个系统,使它能够根据提供的训练数据按照一定的方式来学习;随着训练次数的增加,该系统可以在性能上不断学习和改进,通过参数优化的学习模型,能够用于预测相关问题的输出。
2.机器学习的发展历程
推理期→知识期→学科形成→繁荣期
推理期:认为只要给机器赋予逻辑推理能力,机器就能具有智能
知识期:认为要使机器具有智能,就必须设法使机器拥有知识
学科形成:20世纪80年代,机器学习成为一个独立学科领域并开始迅速发展、各种机器学习技术百花齐放
繁荣期:20世纪90年代后,统计学习方法占主导
3.监督学习、半监督学习和无监督学习的特点
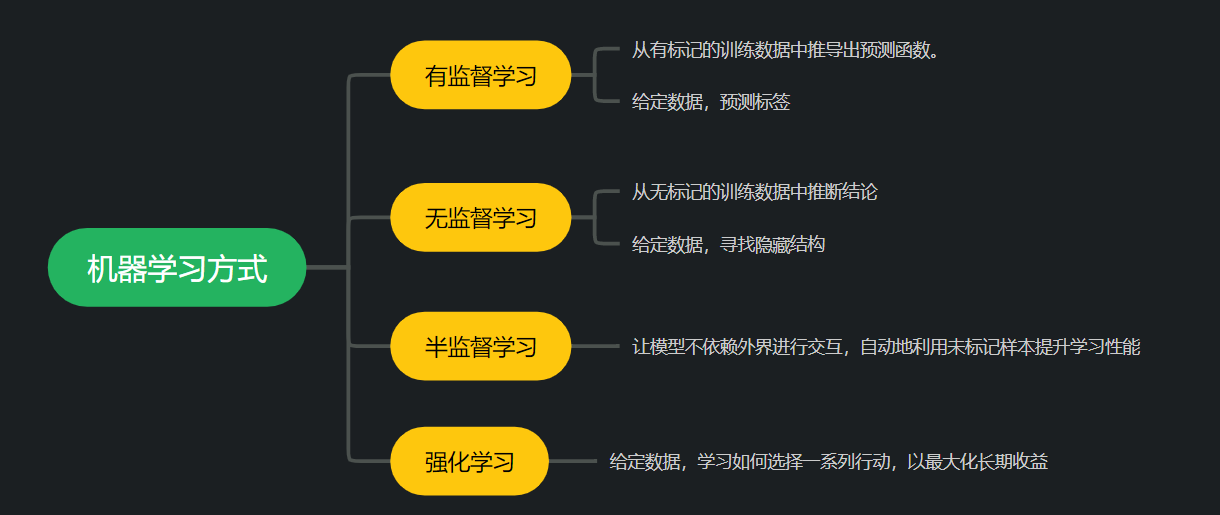
3.1 监督学习
从给定的有标注的训练数据集中学习出一个函数(模型参数),当新的数据到来时,可以根据这个函数预测结果。
常见任务:包括分类与回归。
3.2 无监督学习
没有标注的训练数据集,需要根据样本间的统计规律对样本集进行分析
常见任务:聚类
3.3 半监督学习
结合(少量的)标注训练数据和(大量的)未标注数据来进行数据的分类学习。
半监督学习可进一步分为纯半监督学习和直推学习,前者假定训练数据中的未标记样本并非待测的数据,而后者则假定学习过程中所考虑的未标记样本恰是待预测数据,学习的目的就是在这些未标记样本上获得最优泛化性能。
3.4 强化学习
基于环境的反馈而行动,通过不断与环境交互、试错,使整体行动收益最大化,强化学习不需要训练数据的Label,但是它需要每一步行动环境给予的反馈,是奖励还是惩罚,基于反馈不断调整训练对象的行为。
(强化学习接触的很少,以后遇到会补充)
4.机器学习的一般流程
数据预处理→特征工程→数据建模→结果评估

4.1 数据预处理
数据预处理:数据清洗、数据集成、数据采样
4.1.1 数据清洗
数据清洗:对各种脏数据进行对应方式的处理,得到标准、干净、连续的数据,提供给数据统计,数据挖掘等使用。
确保数据的五个性质:完整性、合法性、一致性、唯一性、权威性!
数据清洗要保证:数据的完整性、数据的合法性、数据的一致性、数据的唯一性、数据的权威性
(这个期末考试考到了,没有写上一致性😶)
解析一下数据的一致性吧:
不同来源的不同指标,实际内涵是一样的,或是同一指标内涵不一致。
解决方法:建立数据体系,包含但不限于指标体系、维度、单位等
4.1.2数据采样
(1)数据不平衡
数据不平衡,指数据集的类别分布不均。
(2)解决方法
解决方法:过采样(Over-Sampling)、欠采样(Under-Sampling)
过采样:通过随机复制少数类来增加其中的实例数量,从而可增加样本中少数类的代表性。
欠采样:通过随机地消除占多数的类的样本来平衡类分布,直到多数类和少数类的实例实现平衡。
4.1.3 数据集拆分
(1)常将数据划分为3份
训练数据集,train dataset:用来构建机器学习模型
验证数据集,validation dataset:辅助构建模型,用于在构建过程中评估模型,提供无偏估计,进而调整模型参数
测试数据集,test dataset:用来评估训练好的最终模型的性能
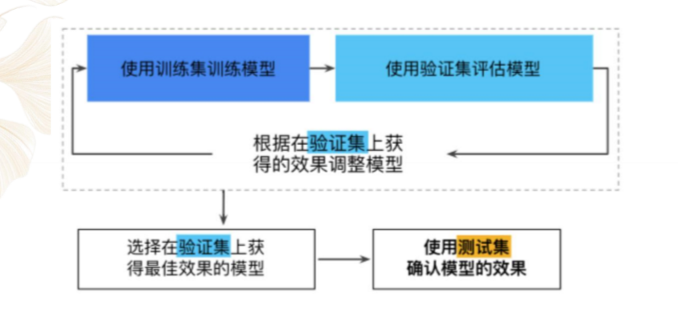
(2)常用拆分方法

5.2 特征工程
特征工程:特征编码、特征选择、特征降维、规范化
5.3 数据建模
数据建模:回归问题、分类问题、聚类问题、其他问题
5.4 结果评估
结果评估:拟合度量、查准率、查全率、F1值、PR曲线、ROC曲线
![[创业之路-48] :动态股权机制 -3- 静态股权分配 VS 动态股权分配](https://img-blog.csdnimg.cn/img_convert/f25e6264d8204bcd4951ef85692c204f.jpeg)