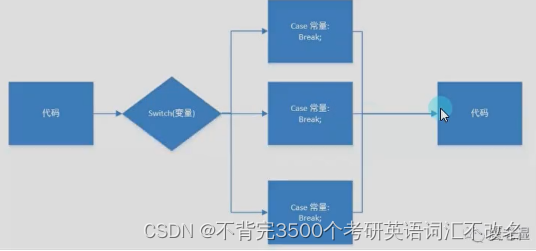
首先展示数据处理后的类型:

第一列为文本,第二类为标注的标签,数据保存在xlsx的表格中,分为训练集和验证集。
textCNN
直接上整个工程代码:
import pandas as pd
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from transformers import BertTokenizer, BertModel
import random
from sklearn.metrics import classification_report
# 设置随机种子以确保结果可复现
def set_seed(seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
set_seed(42)
# 使用预训练的 BERT 模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
bert_model = BertModel.from_pretrained('bert-base-chinese')
# 定义一个函数来处理文本数据
def preprocess(text):
encoding = tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=150,
padding='max_length',
return_attention_mask=True,
return_tensors='pt',
truncation=True
)
return encoding['input_ids'].squeeze(), encoding['attention_mask'].squeeze()
# 读取训练和验证数据
train_df = pd.read_excel('../train.xlsx')
val_df = pd.read_excel('../val.xlsx')
# 处理训练数据
train_texts = train_df['comment'].apply(preprocess)
train_labels = torch.tensor(train_df['label'].values)
train_input_ids = torch.stack([x[0] for x in train_texts])
train_attention_masks = torch.stack([x[1] for x in train_texts])
# 处理验证数据
val_texts = val_df['comment'].apply(preprocess)
val_labels = torch.tensor(val_df['label'].values)
val_input_ids = torch.stack([x[0] for x in val_texts])
val_attention_masks = torch.stack([x[1] for x in val_texts])
# 创建数据集和数据加载器
class TextDataset(Dataset):
def __init__(self, input_ids, attention_masks, labels):
self.input_ids = input_ids
self.attention_masks = attention_masks
self.labels = labels
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
return {
'input_ids': self.input_ids[idx],
'attention_mask': self.attention_masks[idx],
'labels': self.labels[idx]
}
train_dataset = TextDataset(train_input_ids, train_attention_masks, train_labels)
val_dataset = TextDataset(val_input_ids, val_attention_masks, val_labels)
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=32, shuffle=False)
# 检查是否有可用的 GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device: {device}')
# 定义模型
class TextCNN(nn.Module):
def __init__(self, bert_model, num_classes):
super(TextCNN, self).__init__()
self.bert_model = bert_model
self.conv1 = nn.Conv2d(1, 100, (3, 768))
self.conv2 = nn.Conv2d(1, 100, (4, 768))
self.conv3 = nn.Conv2d(1, 100, (5, 768))
self.dropout = nn.Dropout(0.5)
self.fc = nn.Linear(300, num_classes)
def forward(self, input_ids, attention_mask):
with torch.no_grad():
embedded = self.bert_model(input_ids, attention_mask).last_hidden_state
embedded = embedded.unsqueeze(1)
conv1 = F.relu(self.conv1(embedded)).squeeze(3)
conv2 = F.relu(self.conv2(embedded)).squeeze(3)
conv3 = F.relu(self.conv3(embedded)).squeeze(3)
pooled1 = F.max_pool1d(conv1, conv1.size(2)).squeeze(2)
pooled2 = F.max_pool1d(conv2, conv2.size(2)).squeeze(2)
pooled3 = F.max_pool1d(conv3, conv3.size(2)).squeeze(2)
out = torch.cat((pooled1, pooled2, pooled3), 1)
out = self.dropout(out)
return self.fc(out)
# 初始化模型、损失函数和优化器
model = TextCNN(bert_model, num_classes=2).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练和验证模型,并保存最好的模型和最后一轮的模型
def train_and_evaluate(model, train_dataloader, val_dataloader, criterion, optimizer, device, epochs=10):
best_val_accuracy = 0.0
best_model_path = "best_model.pth"
last_model_path = "last_model.pth"
for epoch in range(epochs):
model.train()
train_loss = 0
for batch in train_dataloader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
train_loss /= len(train_dataloader)
print(f"Epoch {epoch + 1}, Training Loss: {train_loss}")
model.eval()
val_loss = 0
correct = 0
total = 0
all_preds = []
all_labels = []
with torch.no_grad():
for batch in val_dataloader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
all_preds.extend(predicted.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
val_loss /= len(val_dataloader)
accuracy = 100 * correct / total
print(f"Validation Loss: {val_loss}, Validation Accuracy: {accuracy}%")
# 打印分类报告
print("Classification Report:")
print(classification_report(all_labels, all_preds, digits=3))
# 保存验证集上表现最好的模型
if accuracy > best_val_accuracy:
best_val_accuracy = accuracy
torch.save(model.state_dict(), best_model_path)
print(f"Best model saved with accuracy: {best_val_accuracy}%")
# 保存最后一轮的模型
torch.save(model.state_dict(), last_model_path)
print(f"Last model saved.")
train_and_evaluate(model, train_dataloader, val_dataloader, criterion, optimizer, device)
可以根据自己爬取的文本的长度来自定义preprocess()函数里面的max_length值,若文本长度超过定义的最大值将进行截断,若不足则padding。最好包括大部分文本的长度,模型效果会比较好。
运行起来可能会报以下错误:
OSError: Can't load tokenizer for 'bert-base-chinese'. If you were trying to load it from 'https://huggingface.co/models', make sure you don't have a local directory with the same name. Otherwise, make sure 'bert-base-chinese' is the correct path to a directory containing all relevant files for a BertTokenizer tokenizer.
说明自动下载可能出现问题我们可以手动下载。
访问给出的网站https://huggingface.co/models,然后搜索bert-base-chinese,如图选择第一个。

点进去后下载config.json、pytorch_model.bin 和 vocab.txt三个文件,在工程的同一路径下创建“bert-base-chinese”的文件夹,将三个文件放入其中。

将使用预训练的 BERT 模型和分词器的两行代码该文调用本地:
tokenizer = BertTokenizer.from_pretrained('./bert-base-chinese')
bert_model = BertModel.from_pretrained('./bert-base-chinese')
运行结果:

BERT
跟textCNN一样用相同的BERT 模型和分词器:
import pandas as pd
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
import torch.optim as optim
from transformers import BertTokenizer, BertModel, BertConfig
import random
from sklearn.metrics import classification_report
# 设置随机种子以确保结果可复现
def set_seed(seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
set_seed(42)
# 使用预训练的 BERT 模型和分词器
tokenizer = BertTokenizer.from_pretrained('./bert-base-chinese')
bert_model = BertModel.from_pretrained('./bert-base-chinese')
# 定义一个函数来处理文本数据
def preprocess(text):
encoding = tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=150,
padding='max_length',
return_attention_mask=True,
return_tensors='pt',
truncation=True
)
return encoding['input_ids'].squeeze(), encoding['attention_mask'].squeeze()
# 读取训练和验证数据
train_df = pd.read_excel('../train.xlsx')
val_df = pd.read_excel('../val.xlsx')
# 处理训练数据
train_texts = train_df['comment'].apply(preprocess)
train_labels = torch.tensor(train_df['label'].values)
train_input_ids = torch.stack([x[0] for x in train_texts])
train_attention_masks = torch.stack([x[1] for x in train_texts])
# 处理验证数据
val_texts = val_df['comment'].apply(preprocess)
val_labels = torch.tensor(val_df['label'].values)
val_input_ids = torch.stack([x[0] for x in val_texts])
val_attention_masks = torch.stack([x[1] for x in val_texts])
# 创建数据集和数据加载器
class TextDataset(Dataset):
def __init__(self, input_ids, attention_masks, labels):
self.input_ids = input_ids
self.attention_masks = attention_masks
self.labels = labels
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
return {
'input_ids': self.input_ids[idx],
'attention_mask': self.attention_masks[idx],
'labels': self.labels[idx]
}
train_dataset = TextDataset(train_input_ids, train_attention_masks, train_labels)
val_dataset = TextDataset(val_input_ids, val_attention_masks, val_labels)
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=32, shuffle=False)
# 检查是否有可用的 GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device: {device}')
# 定义模型
class BertForTextClassification(nn.Module):
def __init__(self, bert_model, num_classes):
super(BertForTextClassification, self).__init__()
self.bert = bert_model
self.dropout = nn.Dropout(0.5)
self.classifier = nn.Linear(bert_model.config.hidden_size, num_classes)
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
pooled_output = outputs.pooler_output
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
return logits
# 初始化模型、损失函数和优化器
model = BertForTextClassification(bert_model, num_classes=2).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.00001)
# 训练和验证模型,并保存最好的模型和最后一轮的模型
def train_and_evaluate(model, train_dataloader, val_dataloader, criterion, optimizer, device, epochs=10):
best_val_accuracy = 0.0
best_model_path = "best_model.pth"
last_model_path = "last_model.pth"
for epoch in range(epochs):
model.train()
train_loss = 0
for batch in train_dataloader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
train_loss /= len(train_dataloader)
print(f"Epoch {epoch + 1}, Training Loss: {train_loss}")
model.eval()
val_loss = 0
correct = 0
total = 0
all_preds = []
all_labels = []
with torch.no_grad():
for batch in val_dataloader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
all_preds.extend(predicted.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
val_loss /= len(val_dataloader)
accuracy = 100 * correct / total
print(f"Validation Loss: {val_loss}, Validation Accuracy: {accuracy}%")
# 打印分类报告
print("Classification Report:")
print(classification_report(all_labels, all_preds, digits=3))
# 保存验证集上表现最好的模型
if accuracy > best_val_accuracy:
best_val_accuracy = accuracy
torch.save(model.state_dict(), best_model_path)
print(f"Best model saved with accuracy: {best_val_accuracy}%")
# 保存最后一轮的模型
torch.save(model.state_dict(), last_model_path)
print(f"Last model saved.")
train_and_evaluate(model, train_dataloader, val_dataloader, criterion, optimizer, device)
运行结果:

transformer
transformer使用的是自己的预训练模型和分词器,如果需要提前手动下载的话访问Hugging Face的官网还是下载config.json、pytorch_model.bin 和 vocab.txt三个文件,保存在hfl/chinese-roberta-wwm-ext目录中。
import pandas as pd
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
import torch.optim as optim
from transformers import AutoTokenizer, AutoModel
import random
from sklearn.metrics import classification_report
# 设置随机种子以确保结果可复现
def set_seed(seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
set_seed(42)
# 使用预训练的 Transformer 模型和分词器
model_name = './hfl/chinese-roberta-wwm-ext'
tokenizer = AutoTokenizer.from_pretrained(model_name)
transformer_model = AutoModel.from_pretrained(model_name)
# 定义一个函数来处理文本数据
def preprocess(text):
encoding = tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=150,
padding='max_length',
return_attention_mask=True,
return_tensors='pt',
truncation=True
)
return encoding['input_ids'].squeeze(), encoding['attention_mask'].squeeze()
# 读取训练和验证数据
train_df = pd.read_excel('../train.xlsx')
val_df = pd.read_excel('../val.xlsx')
# 处理训练数据
train_texts = train_df['comment'].apply(preprocess)
train_labels = torch.tensor(train_df['label'].values)
train_input_ids = torch.stack([x[0] for x in train_texts])
train_attention_masks = torch.stack([x[1] for x in train_texts])
# 处理验证数据
val_texts = val_df['comment'].apply(preprocess)
val_labels = torch.tensor(val_df['label'].values)
val_input_ids = torch.stack([x[0] for x in val_texts])
val_attention_masks = torch.stack([x[1] for x in val_texts])
# 创建数据集和数据加载器
class TextDataset(Dataset):
def __init__(self, input_ids, attention_masks, labels):
self.input_ids = input_ids
self.attention_masks = attention_masks
self.labels = labels
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
return {
'input_ids': self.input_ids[idx],
'attention_mask': self.attention_masks[idx],
'labels': self.labels[idx]
}
train_dataset = TextDataset(train_input_ids, train_attention_masks, train_labels)
val_dataset = TextDataset(val_input_ids, val_attention_masks, val_labels)
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=32, shuffle=False)
# 检查是否有可用的 GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device: {device}')
# 定义模型
class TransformerForTextClassification(nn.Module):
def __init__(self, transformer_model, num_classes):
super(TransformerForTextClassification, self).__init__()
self.transformer = transformer_model
self.dropout = nn.Dropout(0.5)
self.classifier = nn.Linear(transformer_model.config.hidden_size, num_classes)
def forward(self, input_ids, attention_mask):
outputs = self.transformer(input_ids=input_ids, attention_mask=attention_mask)
pooled_output = outputs.pooler_output if 'pooler_output' in outputs else outputs.last_hidden_state[:, 0]
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
return logits
# 初始化模型、损失函数和优化器
model = TransformerForTextClassification(transformer_model, num_classes=2).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.00001)
# 训练和验证模型,并保存最好的模型和最后一轮的模型
def train_and_evaluate(model, train_dataloader, val_dataloader, criterion, optimizer, device, epochs=10):
best_val_accuracy = 0.0
best_model_path = "best_model.pth"
last_model_path = "last_model.pth"
for epoch in range(epochs):
model.train()
train_loss = 0
for batch in train_dataloader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
train_loss /= len(train_dataloader)
print(f"Epoch {epoch + 1}, Training Loss: {train_loss}")
model.eval()
val_loss = 0
correct = 0
total = 0
all_preds = []
all_labels = []
with torch.no_grad():
for batch in val_dataloader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
all_preds.extend(predicted.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
val_loss /= len(val_dataloader)
accuracy = 100 * correct / total
print(f"Validation Loss: {val_loss}, Validation Accuracy: {accuracy}%")
# 打印分类报告
print("Classification Report:")
print(classification_report(all_labels, all_preds, digits=3))
# 保存验证集上表现最好的模型
if accuracy > best_val_accuracy:
best_val_accuracy = accuracy
torch.save(model.state_dict(), best_model_path)
print(f"Best model saved with accuracy: {best_val_accuracy}%")
# 保存最后一轮的模型
torch.save(model.state_dict(), last_model_path)
print(f"Last model saved.")
train_and_evaluate(model, train_dataloader, val_dataloader, criterion, optimizer, device)
运行结果:





![[Algorithm][动态规划][子序列问题][最长递增子序列的个数][最长数对链]详细讲解](https://img-blog.csdnimg.cn/direct/3f72388e276f46ffbccf4e1daf8b31fc.png)


![[Linux]vsftp配置大全---超完整版](https://img-blog.csdnimg.cn/direct/75d0f2df713f4bc68278859094e65078.png)