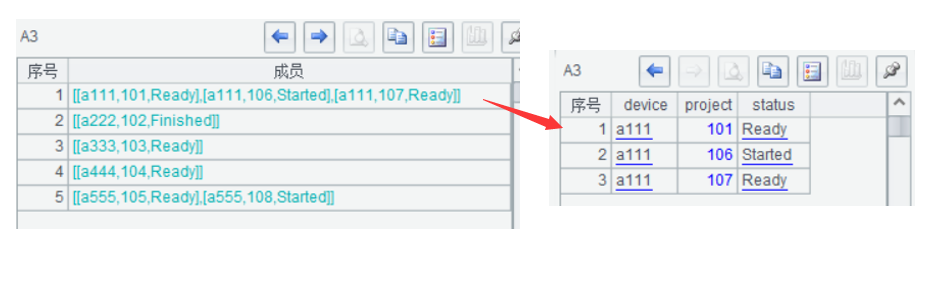
SolrCloud是基于Solr和Zookeeper的分布式搜索方案,它的主要思想是使用Zookeeper作为集群的配置信息中心。SolrCloud是Solr的一种分布式部署方式 ,当索引越来越大时,一个单一的系统无法满足空间和查询效率上的要求,这个时候往往需要考虑引入solr的分布式索引了。而zookeeper常与中间件搭配作为注册中心使用,具有集中式的配置信息、自动容错、近实时搜索、查询时自动负载均衡的功能。
现在需要三个zookeeper节点组成的集群:
上传并解压zookeeper文件
新建solr-cloud文件夹
mkdir /usr/local/solr-cloud
将zookeeper复制三份

进入zookeeper01创建名为myid的文件内容是1作为zookeeper01节点的编号
编辑zoo_sample.cfg文件,设置数据存储目录和对外暴露服务的端口号
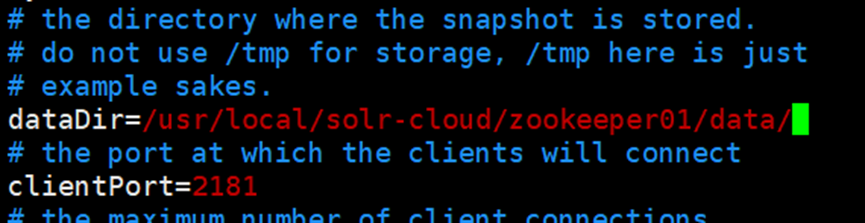
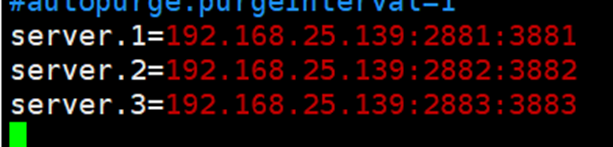
配置zookeeper节点之间通信和投票的端口
server.1=192.168.25.139:2881:3881
server.2=192.168.25.139:2882:3882
server.3=192.168.25.139:2883:3883

进入zookeeper02创建名为myid的文件内容是2作为zookeeper02节点的编号
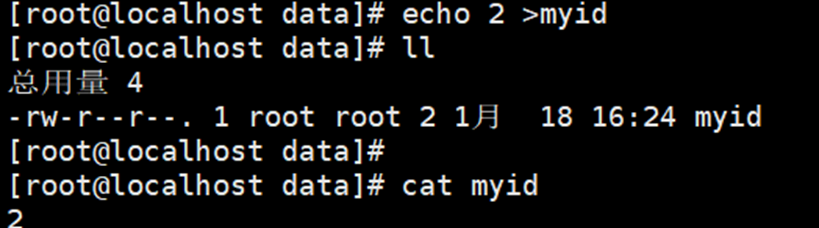
编辑02节点的zoo_sample.cfg文件,设置数据存储目录和对外暴露服务的端口号

配置zookeeper02节点之间通信和投票的端口
Zookeeper03节点的修改配置同上
编写批处理文件给批处理文件授权,启动三个节点:
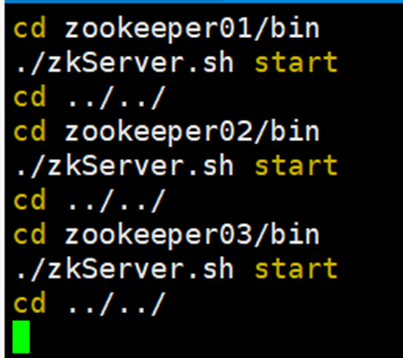
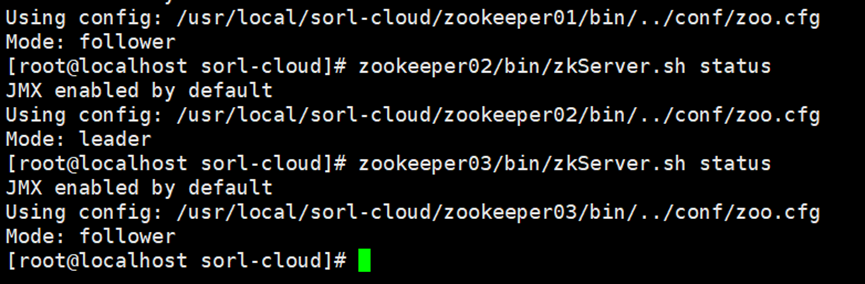
全部启动成功:

查看节点状态