问题
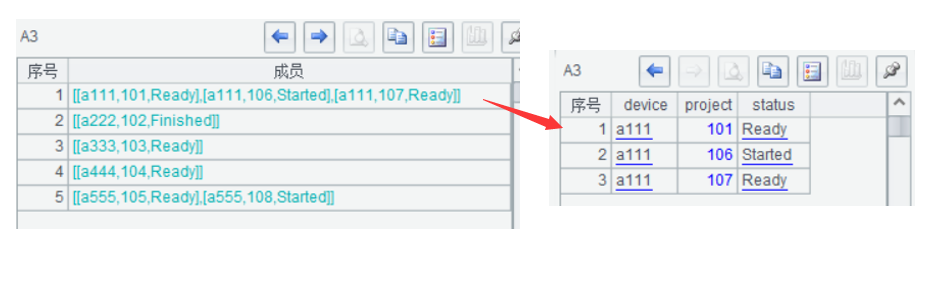
在 stackoverflow 网站上看到这样一个 SQL 分组条件的需求,需求看似挺简单,但能把 SQL 写正确对于新手来说也不容易,我们拿过来深入剖析一下,数据如下:

需求是查找只有Ready 状态的设备。
解答
自然思路:按设备分组,选出Ready状态个数等于所有状态个数的设备组
拆解思路:
1、 按设备分组
2、 计算出每个设备组下Ready状态个数c1
3、 计算出每个设备组下所有状态个数c2
4、 选出状态个数c1等于c2的设备;
思路图:

试写SQL一:
select t1.device
from
(select device, count(status) as c1
from t
where status='Ready'
group by device) t1
join
(select device, count(status) as c2
from t
group by device) t2
on t1.device=t2.device
where t1.c1=t2.c2
这个实际的思路变成了:
1、 按设备分组,找到每个设备下Ready的个数c1;
2、 按设备分组,找到每个设备下所有状态的个数c2;
3、 把两个分组结果通过设备连接到一起;
4、 在连接到一起结果里,查找c1等于c2的设备。
试写SQL二:
select device
from t
group by device
having sum(case when status = 'Ready' then 1 else 0 end) = count(device);
这个实际思路,倒是和期望的自然思维更近了些,但计算设备中Ready状态个数c1时,没有找到太简单的表述方式,采用了一个变通的复杂思路:
1、隐含着增加一个计算字段,状态为Ready时,这个计算字段为1,否则为0;
2、然后对这个计算字段求和,这个和是Ready状态的个数。
上面我试了两种SQL,虽然结果都对,但竟然难以找到和自然思路一致的写法。面对这种局面,我们不能只是满足于SQL老手对新手的炫技;要更深入的思考SQL语言体系到底缺失了什么根本概念?才导致自然而然的解题思路,能说的出,想得明白,但就是写不出相应的计算机语言。
先直接看一下集算器SPL语言的解法:
A | |
1 | =connect("mysqlDB") |
2 | =A1.query(“select * from t”) |
3 | =A2.group(device) |
4 | =A3.select(~.select(status=="Ready").len()==~.len()) |
5 | =A1.close() |
A2从数据库把数据取出来
A3按设备分组,观察一下结果,就只是把数据分成了5组,第一组点进去,能看到有3条符合条件的记录,这一步仅仅做单纯分组,没有其它任何操作:
A4外层select函数里的~符号代表的就是当前设备的组;~.select(status=="Ready").len()就是当前设备下Ready状态个数c1;~.len()是当前设备所有状态的个数 c2;这时最外层 select 变成 A3.select(c1==c2), 也就是自然思路里的第四步:选出状态个数c1等于c2的设备。
完全符合人的自然思维!编码过程顺畅自然,两点之间,直线最短,不用再通过各种“高级技巧”的等价思路绕弯了。
追根溯源,上面 SQL 反映出来的问题,它缺少单纯的分组动作,不能显式的表达每个小分组,进而对每个小分组的更细致操作就无法直观表达。
SQL不提倡分步解决问题、对集合操作支持不彻底、多余的生造出 HAVING 人为的导致概念复杂化;这一系列设计上的缺陷,造成了 SQL 的编写、维护、性能调优都成倍的增加工作量。
集算器的 SPL 语言从根源上弃用了 SQL 背后的关系代数理论,发明新的离散数据集理论解决程序员描述计算的困难。这里有更多 SQL 难点的分析文章:
乾学院 -SPL-SQL 难点
快速上手试试:
下载集算器
如何免费使用润乾集算器