BLIP
数据预处理
CapFilt:标题和过滤
由于多模态模型需要大量数据集,因此通常必须使用图像和替代文本 (alt-text) 对从互联网上抓取这些数据集。然而,替代文本通常不能准确描述图像的视觉内容,使其成为噪声信号,对于学习视觉语言对齐而言并非最佳选择。因此,BLIP 论文引入了一种标题和过滤机制 (CapFilt)。它由一个深度学习模型(可过滤掉噪声对)和另一个为图像创建标题的模型组成。这两个模型都首先使用人工注释的数据集进行微调。他们发现,使用 CapFit 清理数据集比仅使用网络数据集可产生更好的性能。
BLIP 架构
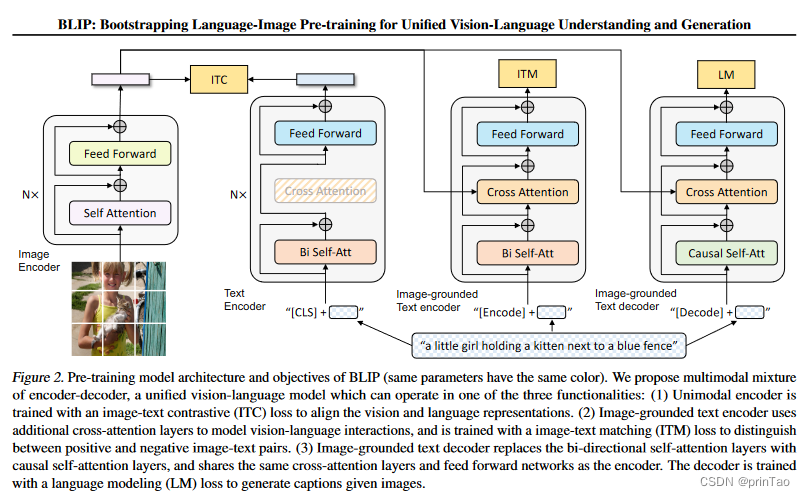
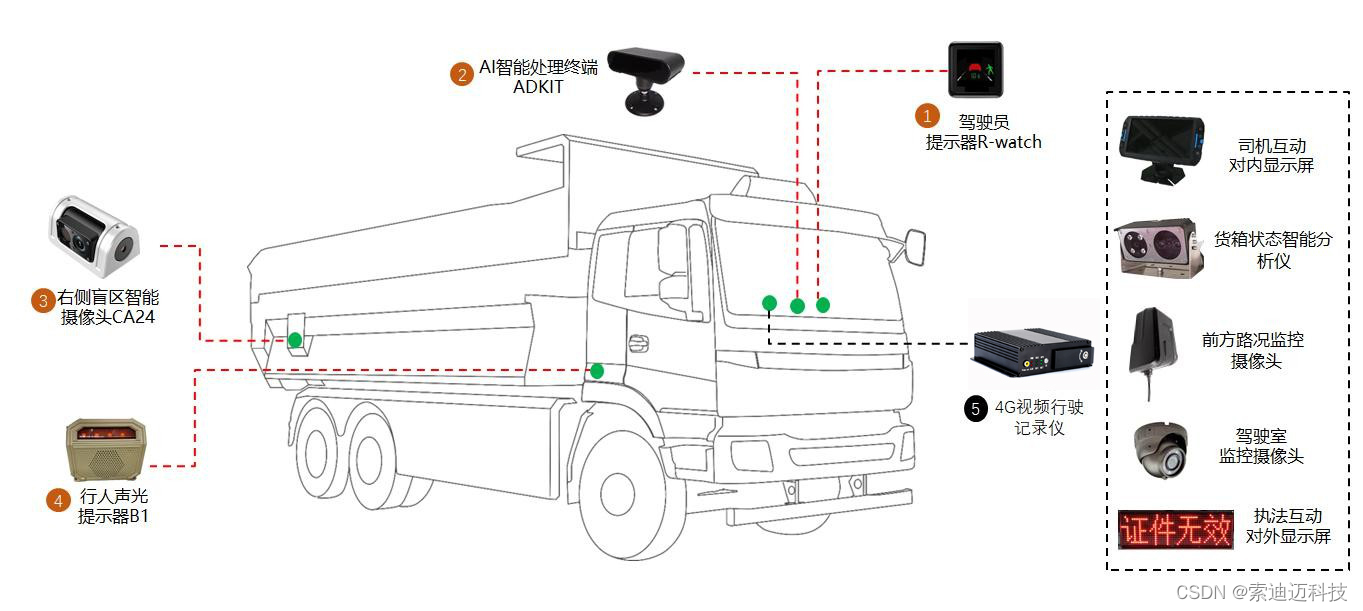
BLIP 架构结合了视觉编码器和多模态编码器-解码器混合 (MED),可实现对视觉和文本数据的多功能处理。其结构如下图所示,其特点是(具有相同颜色的块共享参数):
视觉变换器 (ViT):这是一个普通视觉变换器,具有自注意力、前馈块和用于嵌入表示的 [CLS] 标记。
单峰文本编码器:类似于 BERT 的架构,它使用 [CLS] 标记进行嵌入,并采用类似 CLIP 的对比损失来对齐图像和文本表示。
基于图像的文本编码器:这将 [CLS] 标记替换为 [Encode] 标记。交叉注意层可以集成图像和文本嵌入,从而创建多模态表示。它采用线性层来评估图像-文本对的一致性。
基于图像的文本解码器:用因果自注意力取代双向自注意力,该解码器通过交叉熵损失以自回归的方式进行训练,以完成诸如字幕生成或回答视觉问题之类的任务。
BLIP 的架构将视觉编码器与多模编码器-解码器组件组合在一起,实现了高级文本和图像处理。这种设计使其能够熟练地处理各种任务,从对齐图像-文本对到生成字幕和回答视觉问题。
OWL-ViT
物体检测是计算机视觉中的一项关键任务,借助 YOLO(原始论文,最新代码版本)等模型,该任务取得了重大进展。然而,像 YOLO 这样的传统模型在检测训练数据集之外的物体方面存在局限性。为了解决这个问题,人工智能社区已转向开发能够识别更广泛物体的模型,从而创建了类似于 CLIP 的模型,但用于物体检测。
OWL-ViT:增强功能和功能
OWL-ViT 代表了开放词汇对象检测的一次飞跃。它从类似于 CLIP 的训练阶段开始,重点关注使用对比损失的视觉和语言编码器。这个基础阶段使模型能够学习视觉和文本数据的共享表示空间。
针对物体检测进行微调
OWL-ViT 的创新之处在于其用于对象检测的微调阶段。在这里,OWL-VIT 不使用 CLIP 中使用的标记池和最终投影层,而是采用每个输出标记的线性投影来获得每个对象的图像嵌入。然后使用这些嵌入进行分类,而框坐标则通过小型 MLP 从标记表示中得出。这种方法使 OWL-ViT 能够检测图像中的对象及其空间位置,这比传统的对象检测模型有了显著的进步。
import requests
from PIL import Image, ImageDraw
import torch
from transformers import OwlViTProcessor, OwlViTForObjectDetection
processor = OwlViTProcessor.from_pretrained("google/owlvit-base-patch32")
model = OwlViTForObjectDetection.from_pretrained("google/owlvit-base-patch32")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = [["a photo of a cat", "a photo of a dog", "remote control", "cat tail"]]
inputs = processor(text=texts, images=image, return_tensors="pt")
outputs = model(**inputs)
target_sizes = torch.Tensor([image.size[::-1]])
results = processor.post_process_object_detection(
outputs=outputs, target_sizes=target_sizes, threshold=0.1
)
i = 0 # Retrieve predictions for the first image for the corresponding text queries
text = texts[i]
boxes, scores, labels = results[i]["boxes"], results[i]["scores"], results[i]["labels"]
# Create a draw object
draw = ImageDraw.Draw(image)
# Draw each bounding box
for box, score, label in zip(boxes, scores, labels):
box = [round(i, 2) for i in box.tolist()]
print(
f"Detected {text[label]} with confidence {round(score.item(), 3)} at location {box}"
)
# Draw the bounding box on the image
draw.rectangle(box, outline="red")
# Display the image
image