前言
系列专栏:【深度学习:算法项目实战】✨︎
涉及医疗健康、财经金融、商业零售、食品饮料、运动健身、交通运输、环境科学、社交媒体以及文本和图像处理等诸多领域,讨论了各种复杂的深度神经网络思想,如卷积神经网络、循环神经网络、生成对抗网络、门控循环单元、长短期记忆、自然语言处理、深度强化学习、大型语言模型和迁移学习。
情感分析是指利用自然语言处理、文本分析、计算语言学和生物统计学,系统地识别、提取、量化和研究情感状态和主观信息。
语言模型通过学习来预测单词序列的概率。但为什么我们需要学习单词的概率呢?让我们通过一个例子来理解。我相信你一定用过谷歌翻译。出于不同的原因,我们都会用它将一种语言翻译成另一种语言。这是一个流行的 NLP 应用的例子,叫做机器翻译。在 “机器翻译 ”中,你需要从一种语言中输入一堆单词,然后将这些单词转换成另一种语言。现在,系统可能会给出许多潜在的翻译,您需要计算每种翻译的概率,以了解哪种翻译最准确。
目录
- 1. 根据预训练模型训练文本分类器
- 1.1 使用高级应用程序接口
- 1.2 使用数据块应用程序接口
- 2. ULMFiT 方法
- 2.1 微调 IMDb 上的语言模型
- 2.2 训练文本分类器
我们将使用《学习词向量进行情感分析》一文中的 IMDb 数据集,该数据集包含数千条电影评论。
1. 根据预训练模型训练文本分类器
我们将尝试使用预训练模型来训练分类器,为了准备好数据,我们将首先使用高级 API:
1.1 使用高级应用程序接口
我们可以使用以下命令下载数据并解压:
from fastai.text.all import *
path = untar_data(URLs.IMDB)
path.ls()
(#5) [Path('/home/sgugger/.fastai/data/imdb/unsup'),Path('/home/sgugger/.fastai/data/imdb/models'),Path('/home/sgugger/.fastai/data/imdb/train'),Path('/home/sgugger/.fastai/data/imdb/test'),Path('/home/sgugger/.fastai/data/imdb/README')]
(path/'train').ls()
(#4) [Path('/home/sgugger/.fastai/data/imdb/train/pos'),Path('/home/sgugger/.fastai/data/imdb/train/unsupBow.feat'),Path('/home/sgugger/.fastai/data/imdb/train/labeledBow.feat'),Path('/home/sgugger/.fastai/data/imdb/train/neg')]
数据按照 ImageNet 风格组织,在 train 文件夹中,我们有两个子文件夹:pos 和 neg(分别用于正面评论和负面评论)。我们可以使用 TextDataLoaders.from_folder 方法收集数据。我们唯一需要指定的是验证文件夹的名称,即 “test”(而不是默认的 “valid”)。
dls = TextDataLoaders.from_folder(untar_data(URLs.IMDB), valid='test')
然后,我们可以使用 show_batch 方法查看数据:
dls.show_batch()


我们可以看到,该程序库自动处理了所有文本,然后将其拆分成标记符,并添加了一些特殊标记符,如
xxbos表示文本开始xxmaj表示下一个词被大写
这样,我们就可以在一行中定义一个适合文本分类的学习器:
learn = text_classifier_learner(dls, AWD_LSTM, drop_mult=0.5, metrics=accuracy)
我们使用 AWD LSTM 架构,drop_mult 是一个参数,用于控制该模型中所有 dropout 的大小,我们使用准确率来跟踪我们模型效果。然后,我们就可以对预训练模型进行微调:
learn.fine_tune(4, 1e-2)
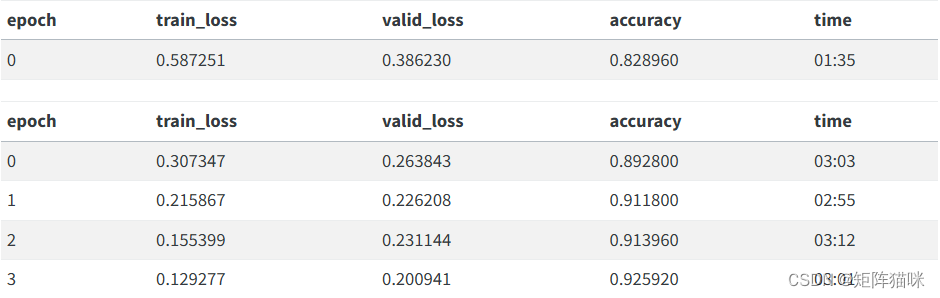
learn.fine_tune(4, 1e-2)
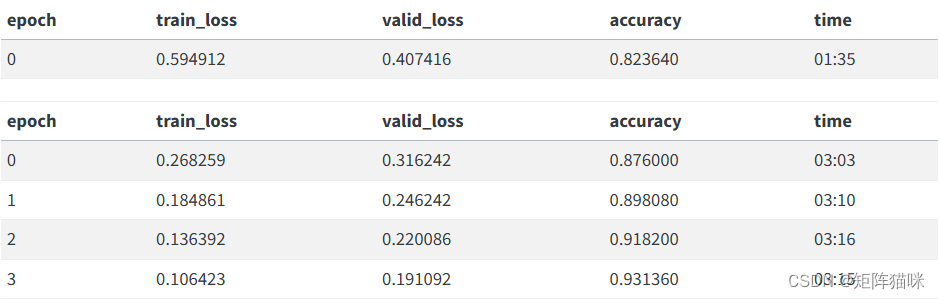
还不错!我们可以使用 show_results 方法来查看模型的运行情况:
learn.show_results()

我们可以很容易地预测新文本:
learn.predict("I really liked that movie!")
('pos', tensor(1), tensor([0.0092, 0.9908]))
在这里,我们可以看到模型认为该评论是正面的。结果的第二部分是 “pos ”在我们的数据词汇表中的索引,最后一部分是每个类别的概率(“pos ”为 99.1%,“neg ”为 0.9%)。
1.2 使用数据块应用程序接口
我们还可以使用数据块 API 在 DataLoaders 中获取数据。这部分比较高深,如果你还不习惯学习新的 API,可以跳过这部分。
数据库块是通过向 fastai 库提供大量信息而建立的:
通过一个名为 “块”(block)的参数来确定所使用的类型:这里我们有文本和类别,因此我们传递 TextBlock 和 CategoryBlock。为了通知库我们的文本是文件夹中的文件,我们使用了 from_folder 类方法。
- 如何获取原始项目,这里使用函数
get_text_files。 - 如何标注这些项目,这里使用父文件夹。
- 如何分割这些项目,此处使用祖文件夹。
imdb = DataBlock(blocks=(TextBlock.from_folder(path), CategoryBlock),
get_items=get_text_files,
get_y=parent_label,
splitter=GrandparentSplitter(valid_name='test'))
这只是提供了一个如何组合数据的蓝图。要实际创建数据,我们需要使用 dataloaders 方法:
dls = imdb.dataloaders(path)
2. ULMFiT 方法
我们在上一节中使用的预训练模型被称为语言模型。它是在维基百科上进行预训练的,任务是在阅读了前面所有单词后猜测下一个单词。我们将这个语言模型直接微调为电影评论分类器,取得了很好的效果,但只要多做一步,我们就能做得更好:维基百科的英语与 IMDb 的英语略有不同。因此,我们可以根据 IMDb 语料库微调预训练的语言模型,然后以此为基础建立分类器,而不是直接跳转到分类器。
当然,其中一个原因是,了解你正在使用的模型的基础是很有帮助的。但还有一个非常实用的原因,那就是如果在微调分类模型之前微调(基于序列的)语言模型,就能获得更好的结果。例如,在 IMDb 情感分析任务中,数据集包含了 50,000 条额外的电影评论,这些评论在 unsup 文件夹中没有附加任何正面或负面标签。我们可以使用所有这些影评来微调预训练的语言模型–这将产生一个特别擅长预测影评下一个单词的语言模型。相比之下,预训练模型只在维基百科文章中进行训练。
这幅图概括了整个过程: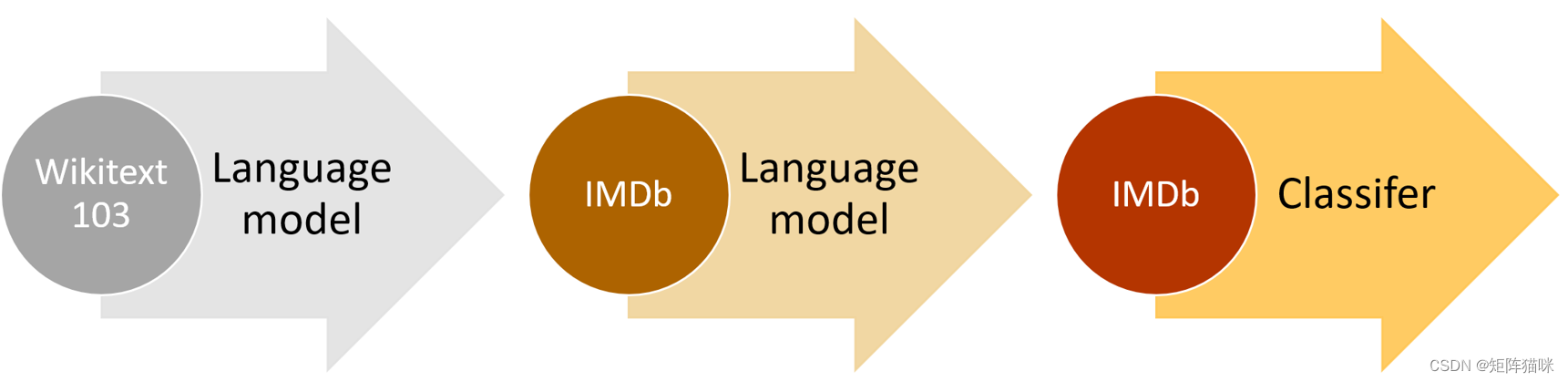
2.1 微调 IMDb 上的语言模型
我们可以很容易地将文本放入适合语言建模的 DataLoaders 中:
dls_lm = TextDataLoaders.from_folder(path, is_lm=True, valid_pct=0.1)
我们需要为 valid_pct 传递一些信息,否则该方法将尝试使用祖文件夹名称来分割数据。通过传递 valid_pct=0.1,我们可以告诉它随机获取其中 10%的评论作为验证集。
我们可以使用 show_batch 查看数据。这里的任务是猜测下一个单词,因此我们可以看到目标都向右移动了一个单词。
dls_lm.show_batch(max_n=5)

然后,我们有一个方便的方法,可以像以前一样使用 AWD_LSTM 架构直接从中抓取一个学习器。我们使用准确率和困惑度作为衡量指标(困惑度是损失的指数),并将默认权重衰减设为 0.1。
learn = language_model_learner(dls_lm, AWD_LSTM, metrics=[accuracy, Perplexity()], path=path, wd=0.1).to_fp16()
默认情况下,预训练的学习器处于冻结状态,这意味着只有模型的头部会进行训练,而主体则保持冻结。在这里,我们将向你展示 fine_tune 方法背后的内容,并使用 fit_one_cycle 方法来拟合模型:
learn.fit_one_cycle(1, 1e-2)

这个模型的训练需要一段时间,所以这是一个很好的机会来讨论保存中间结果的问题。
您可以像这样轻松保存模型的状态:
learn.save('1epoch')
它会在 learn.path/models/ 中创建一个名为 “1epoch.pth ”的文件。如果您想在以同样方式创建学习器后在另一台机器上加载模型,或稍后继续训练,您可以通过以下方式加载该文件的内容:
learn = learn.load('1epoch')
我们可以在解冻后对模型进行微调:
learn.unfreeze()
learn.fit_one_cycle(10, 1e-3)
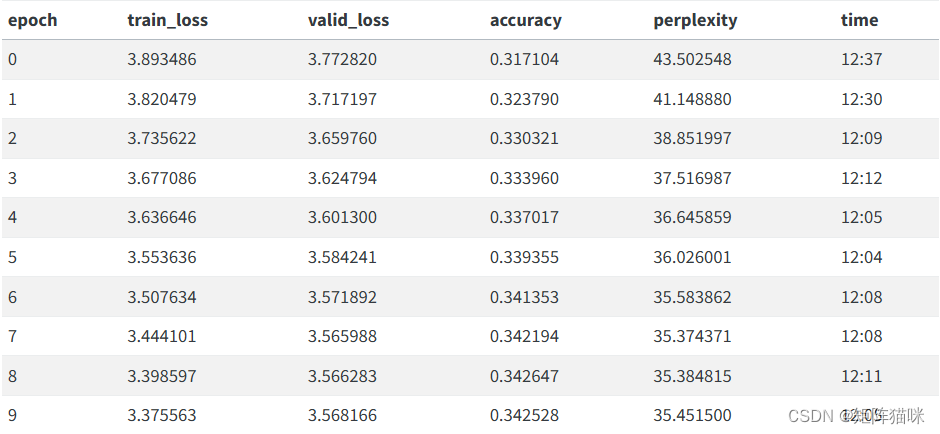
完成后,我们就可以保存模型的全部内容,但最后一层除外,该层将激活度转换为选取词汇表中每个标记的概率。不包括最后一层的模型称为编码器。我们可以用 save_encoder 保存它:
learn.save_encoder('finetuned')
术语:Encoder(编码器): 不包括特定任务最终层的模型。在应用于视觉 CNN 时,其含义与 body 大致相同,但更多用于 NLP 和生成模型。
在利用这一点对评论分类器进行微调之前,我们可以使用我们的模型来生成随机评论:因为它经过训练可以猜测句子的下一个单词是什么,所以我们可以用它来编写新的评论:
TEXT = "I liked this movie because"
N_WORDS = 40
N_SENTENCES = 2
preds = [learn.predict(TEXT, N_WORDS, temperature=0.75)
for _ in range(N_SENTENCES)]
print("\n".join(preds))
i liked this movie because of its story and characters . The story line was very strong , very good for a sci - fi film . The main character , Alucard , was very well developed and brought the whole story
i liked this movie because i like the idea of the premise of the movie , the ( very ) convenient virus ( which , when you have to kill a few people , the " evil " machine has to be used to protect
2.2 训练文本分类器
我们几乎可以像以前一样收集数据进行文本分类:
dls_clas = TextDataLoaders.from_folder(untar_data(URLs.IMDB), valid='test', text_vocab=dls_lm.vocab)
主要区别在于,我们必须使用与微调语言模型时完全相同的词汇,否则学习到的权重将毫无意义。我们用 text_vocab 传递这个词汇。
然后,我们就可以像之前一样定义文本分类器了:
learn = text_classifier_learner(dls_clas, AWD_LSTM, drop_mult=0.5, metrics=accuracy)
所不同的是,在训练之前,我们先加载之前的编码器:
learn = learn.load_encoder('finetuned')
最后一步是使用辨别学习率和渐进解冻进行训练。在计算机视觉中,我们通常会一次性解冻模型,但对于 NLP 分类器,我们发现每次解冻几层会带来真正的不同。
learn.fit_one_cycle(1, 2e-2)

只用了一个历元,我们就得到了与第一节中的训练相同的结果,不算太差!我们可以向 freeze_to 传递 -2 以冻结除最后两个参数组之外的所有参数:
learn.freeze_to(-2)
learn.fit_one_cycle(1, slice(1e-2/(2.6**4),1e-2))

然后我们可以再解冻一些,继续训练:
learn.freeze_to(-3)
learn.fit_one_cycle(1, slice(5e-3/(2.6**4),5e-3))

最后是整个模型!
learn.unfreeze()
learn.fit_one_cycle(2, slice(1e-3/(2.6**4),1e-3))