文章目录
- 概述
- 一 语法层面变化
- 1_JEP 409:密封类
- 2_JEP 406:switch模式匹配(预览)
- 二 API层面变化
- 1_JEP 414:Vector API(第二个孵化器)
- 2_JEP 415:特定于上下文的反序列化过滤器
- 三 其他变化
- 1_JEP 306:恢复始终严格的浮点语义
- 2_JEP 356:增强型伪随机数生成器
- 3_JEP 382:新的 macOS 渲染管线
- 4_JEP 391:macOS/AArch64 端口
- 5_JEP 398:弃用 Applet API 以进行删除
- 6_JEP 403:强封装 JDK 内部
- 7_JEP 407:删除 RMI 激活
- 8_JEP 410:删除实验性 AOT 和 JIT 编译器
- 9_JEP 411:弃用安全管理器以进行删除
- 10_JEP 412:外部函数和内存 API(孵化器)
概述
JDK 16 刚发布半年(2021/03/16),JDK 17 又如期而至(2021/09/14),这个时间点特殊,蹭苹果发布会的热度?记得当年 JDK 15 的发布也是同天
Oracle 宣布,从 JDK 17 开始,后面的 JDK 都全部免费提供!!!

Java 17+ 可以免费使用了,包括商用,更详细的条款可以阅读:
https://www.oracle.com/downloads/licenses/no-fee-license.html
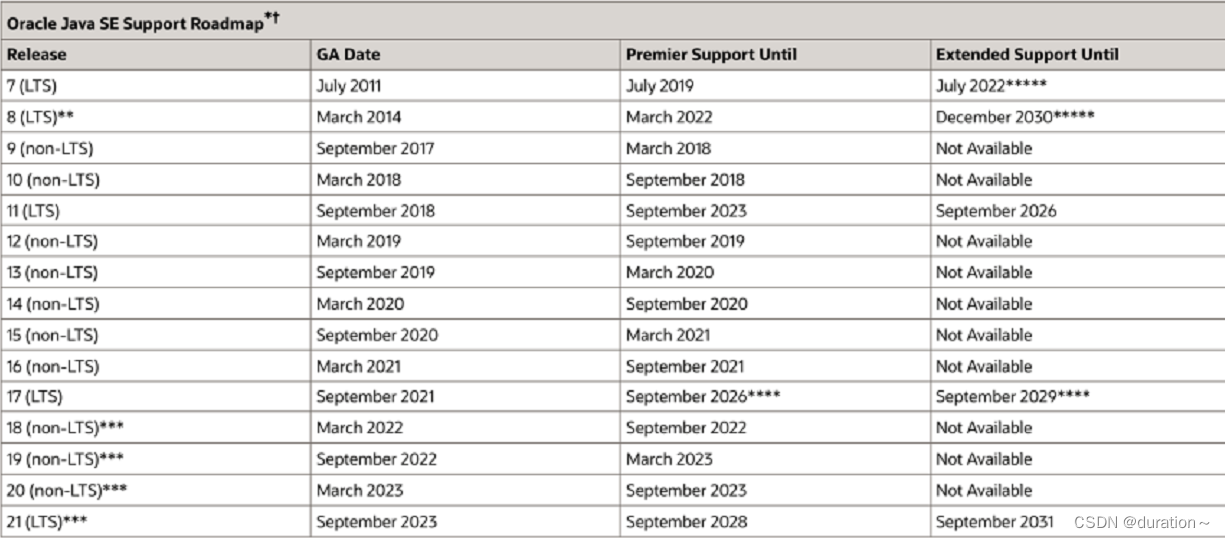
JDK 17 是自 2018 年 JDK 11 后的第二个长期支持版本,支持到 2029 年 9 月,支持时间长达 8 年,这下可以不用死守 JDK 8 了,JDK 17+ 也可以是一种新的选择了。下一个第三个长期支持版本是 JDK 21,时间为 2023 年 9 月,这次长期支持版本发布计划改了,不再是原来的 3 年一次,而是改成了 2 年一次!非长期支持版本还是半年发一次不变,下一个非长期支持版本计划在 2022/03 发布

OpenJDK文档
https://openjdk.java.net/projects/jdk/17/

JDK 17 这个版本提供了 14 个增强功能,另外在性能、稳定性和安全性上面也得到了大量的提升,以及还有一些孵化和预览特性,有了这些新变化,Java 会进一步提高开发人员的生产力。
一 语法层面变化
1_JEP 409:密封类
概述
密封类,这个特性在 JDK 15 中首次成为预览特性,在 JDK 16 中进行二次预览,在 JDK 17 这个版本中终于正式转正了。
历史
密封类是由JEP 360提出的,并在JDK 15 中作为 预览功能提供。它们由JEP 397再次提出并进行了改进,并作为预览功能在 JDK 16中提供。该 JEP 建议在 JDK 17 中完成密封类,与 JDK 16 没有任何变化。
目标
- 允许类或接口的作者控制负责实现它的代码。
- 提供比访问修饰符更具声明性的方式来限制超类的使用。
- 通过为模式的详尽分析提供基础,支持模式匹配的未来方向。
原因
类和接口的继承层次结构的面向对象数据模型已被证明在对现代应用程序处理的现实世界数据进行建模方面非常有效。这种表现力是 Java 语言的一个重要方面。
然而,在某些情况下,可以有效地控制这种表现力。例如,Java 支持枚举类来模拟给定类只有固定数量实例的情况。在以下代码中,枚举类列出了一组固定的行星。它们是该类的唯一值,因此您可以彻底切换它们——无需编写default子句:
enum Planet { MERCURY, VENUS, EARTH }
Planet p = ...
switch (p) {
case MERCURY: ...
case VENUS: ...
case EARTH: ...
}
使用枚举类值的模型固定集通常是有帮助的,但有时我们想一套固定的模型种价值。我们可以通过使用类层次结构来做到这一点,而不是作为代码继承和重用的机制,而是作为列出各种值的一种方式。以我们的行星示例为基础,我们可以对天文领域中的各种值进行建模,如下所示:
interface Celestial { ... }
final class Planet implements Celestial { ... }
final class Star implements Celestial { ... }
final class Comet implements Celestial { ... }
然而,这种层次结构并没有反映重要的领域知识,即我们的模型中只有三种天体。在这些情况下,限制子类或子接口的集合可以简化建模。
考虑另一个例子:在一个图形库中,一个类的作者Shape 可能希望只有特定的类可以扩展Shape,因为该库的大部分工作涉及以适当的方式处理每种形状。作者对处理 的已知子类的代码的清晰度感兴趣 Shape,而对编写代码来防御 的未知子类不感兴趣Shape。允许任意类扩展Shape,从而继承其代码以供重用,在这种情况下不是目标。不幸的是,Java 假定代码重用始终是一个目标:如果Shape可以扩展,那么它可以扩展任意数量的类。放宽这个假设是有帮助的,这样作者就可以声明一个类层次结构,该层次结构不能被任意类扩展。在这样一个封闭的类层次结构中,代码重用仍然是可能的,但不能超出。
Java 开发人员熟悉限制子类集的想法,因为它经常出现在 API 设计中。该语言在这方面提供了有限的工具:要么创建一个类final,使其具有零个子类,要么使该类或其构造函数成为包私有的,因此它只能在同一个包中具有子类。包私有超类的示例 出现在 JDK 中:
package java.lang;
abstract class AbstractStringBuilder { ... }
public final class StringBuffer extends AbstractStringBuilder { ... }
public final class StringBuilder extends AbstractStringBuilder { ... }
当目标是代码重用时,包私有方法很有用,例如AbstractStringBuilder让append. 然而,当目标是对替代方案进行建模时,这种方法是无用的,因为用户代码无法访问关键抽象——超类——以 switch覆盖它。允许用户访问超类而不允许他们扩展它是无法指定的,除非诉诸涉及非public构造函数的脆弱技巧——这些技巧不适用于接口。在声明Shape及其子类的图形库中,如果只有一个包可以访问Shape.
总之,超类应该可以被广泛访问 (因为它代表用户的重要抽象)但不能广泛 扩展(因为它的子类应该仅限于作者已知的那些)。这样一个超类的作者应该能够表达它是与一组给定的子类共同开发的,既为读者记录意图,又允许 Java 编译器强制执行。同时,超类不应过度约束其子类,例如,强迫它们成为final或阻止它们定义自己的状态。
2_JEP 406:switch模式匹配(预览)
概述
使用switch 表达式和语句的模式匹配以及对模式语言的扩展来增强 Java 编程语言。扩展模式匹配以switch允许针对多个模式测试表达式,每个模式都有特定的操作,以便可以简洁安全地表达复杂的面向数据的查询。
instanceof 模式匹配是JAVA14 非常赞的一个新特性! 这次在 JDK 17 中为 switch 语句支持模式匹配
目标
switch通过允许模式出现在case标签中来扩展表达式和语句的表现力和适用性。- 允许在
switch需要时放松对历史的零敌意。 - 引入两种新的模式:保护模式,允许使用任意布尔表达式细化模式匹配逻辑,以及带 括号的模式,以解决一些解析歧义。
- 确保所有现有的
switch表达式和语句继续编译而不做任何更改并以相同的语义执行。 - 不要引入
switch与传统switch构造分离的具有模式匹配语义的新式表达式或语句。 switch当 case 标签是模式与 case 标签是传统常量时,不要使表达式或语句的行为不同。
老式的写法
static String formatter(Object o) {
String formatted = "unknown";
if (o instanceof Integer i) {
formatted = String.format("int %d", i);
} else if (o instanceof Long l) {
formatted = String.format("long %d", l);
} else if (o instanceof Double d) {
formatted = String.format("double %f", d);
} else if (o instanceof String s) {
formatted = String.format("String %s", s);
}
return formatted;
}
支持模式匹配的switch
static String formatterPatternSwitch(Object o) {
return switch (o) {
case Integer i -> String.format("int %d", i);
case Long l -> String.format("long %d", l);
case Double d -> String.format("double %f", d);
case String s -> String.format("String %s", s);
default -> o.toString();
};
}
直接在 switch 上支持 Object 类型,这就等于同时支持多种类型,使用模式匹配得到具体类型,大大简化了语法量,这个功能还是挺实用的, 目前看转正只是一个时间上的问题而已.
二 API层面变化
1_JEP 414:Vector API(第二个孵化器)
概括
引入一个 API 来表达向量计算,这些计算在运行时可靠地编译为支持的 CPU 架构上的最佳向量指令,从而实现优于等效标量计算的性能。
历史
Vector API 由JEP 338提出并作为孵化 API集成到 Java 16 中。我们在此建议结合改进以响应反馈以及性能改进和其他重要的实施改进。我们包括以下显着变化:
- 增强 API 以支持字符操作,例如 UTF-8 字符解码。具体来说,我们添加了在
short向量和char数组之间复制字符的方法,以及用于与整数向量进行无符号比较的新向量比较运算符。 - 用于将
byte向量与boolean数组相互转换的 API 的增强功能。 - 使用英特尔的短向量数学库 (SVML)对 x64 上的超越和三角泳道运算的内在支持。
- Intel x64 和 ARM NEON 实现的一般性能增强。
目标
-
清晰简洁的 API ——API 应该能够清晰简洁地表达广泛的向量计算,这些向量计算由循环内组成的向量操作序列组成,可能还有控制流。应该可以表达与向量大小或每个向量的车道数相关的通用计算,从而使此类计算能够跨支持不同向量大小的硬件进行移植。
-
平台不可知——API应该是 CPU 架构不可知的,支持在支持向量指令的多种架构上实现。就像在 Java API 中一样,平台优化和可移植性发生冲突,那么偏向于使 API 可移植,即使这会导致某些特定于平台的习语无法在可移植代码中表达。
-
在 x64 和 AArch64 架构上可靠的运行时编译和性能——在强大的 x64 架构上,Java 运行时,特别是 HotSpot C2 编译器,应该将向量操作编译为相应的高效和高性能向量指令,例如那些由Streaming SIMD Extensions (SSE) 和Advanced支持的 指令矢量扩展 (AVX)。开发人员应该相信他们表达的向量操作将可靠地映射到相关的向量指令。在功能强大的 ARM AArch64 架构上,C2 将类似地将向量操作编译为NEON支持的向量指令。
-
优雅降级——有时向量计算无法在运行时完全表达为向量指令序列,这可能是因为架构不支持某些所需的指令。在这种情况下,Vector API 实现应该优雅地降级并仍然起作用。如果无法将向量计算有效地编译为向量指令,则这可能涉及发出警告。在没有向量的平台上,优雅降级将产生与手动展开循环竞争的代码,其中展开因子是所选向量中的通道数。
原因
向量计算由对向量的一系列操作组成。向量包含(通常)固定的标量值序列,其中标量值对应于硬件定义的向量通道的数量。应用于具有相同通道数的两个向量的二元运算,对于每个通道,将对来自每个向量的相应两个标量值应用等效的标量运算。这通常称为单指令多数据(SIMD)。
向量运算表达了一定程度的并行性,可以在单个 CPU 周期内执行更多工作,从而显着提高性能。例如,给定两个向量,每个向量包含八个整数的序列(即八个通道),可以使用单个硬件指令将这两个向量相加。向量加法指令对十六个整数进行运算,执行八次整数加法,而通常对两个整数进行运算,执行一次整数加法所需的时间。
HotSpot 已经支持自动向量化,它将标量操作转换为超字操作,然后映射到向量指令。可转换的标量操作集是有限的,并且在代码形状的变化方面也很脆弱。此外,可能仅使用可用向量指令的子集,从而限制了生成代码的性能。
今天,希望编写可靠地转换为超字操作的标量操作的开发人员需要了解 HotSpot 的自动矢量化算法及其局限性,以实现可靠和可持续的性能。在某些情况下,可能无法编写可转换的标量操作。例如,HotSpot 不会转换用于计算数组散列码的简单标量操作(因此是 Arrays::hashCode方法),也不能自动矢量化代码以按字典顺序比较两个数组(因此我们添加了用于字典比较的内在函数)。
Vector API 旨在通过提供一种在 Java 中编写复杂矢量算法的方法来改善这种情况,使用现有的 HotSpot 自动矢量化器,但使用用户模型使矢量化更加可预测和健壮。手工编码的向量循环可以表达高性能算法,例如向量化hashCode或专门的数组比较,自动向量化器可能永远不会优化这些算法。许多领域都可以从这个显式向量 API 中受益,包括机器学习、线性代数、密码学、金融和 JDK 本身的代码。
2_JEP 415:特定于上下文的反序列化过滤器
概括
允许应用程序通过 JVM 范围的过滤器工厂配置特定于上下文和动态选择的反序列化过滤器,该工厂被调用以为每个单独的反序列化操作选择一个过滤器
原因
反序列化不受信任的数据是一种固有的危险活动,因为传入数据流的内容决定了创建的对象、其字段的值以及它们之间的引用。在许多典型用途中,流中的字节是从未知、不受信任或未经身份验证的客户端接收的。通过仔细构建流,攻击者可以导致恶意执行任意类中的代码。如果对象构造具有改变状态或调用其他操作的副作用,那么这些操作可能会损害应用程序对象、库对象甚至 Java 运行时的完整性。禁用反序列化攻击的关键是防止任意类的实例被反序列化,从而防止直接或间接执行它们的方法。
我们在 Java 9 中引入了反序列化过滤器 (JEP 290),使应用程序和库代码能够在反序列化之前验证传入的数据流。此类代码java.io.ObjectInputFilter在创建反序列化流(即 a java.io.ObjectInputStream)时提供验证逻辑作为 a 。
依赖流的创建者来明确请求验证有几个限制。这种方法不能扩展,并且很难在代码发布后更新过滤器。它也不能对应用程序中第三方库执行的反序列化操作进行过滤。
为了解决这些限制,JEP 290 还引入了一个 JVM 范围的反序列化过滤器,可以通过 API、系统属性或安全属性进行设置。此过滤器是*静态的,*因为它在启动时只指定一次。使用静态 JVM 范围过滤器的经验表明,它也有局限性,尤其是在具有库层和多个执行上下文的复杂应用程序中。对每个使用 JVM 范围的过滤器 ObjectInputStream要求过滤器覆盖应用程序中的每个执行上下文,因此过滤器通常会变得过于包容或过于严格。
更好的方法是以不需要每个流创建者参与的方式配置每个流过滤器。
为了保护 JVM 免受反序列化漏洞的影响,应用程序开发人员需要清楚地描述每个组件或库可以序列化或反序列化的对象。对于每个上下文和用例,开发人员应该构建并应用适当的过滤器。例如,如果应用程序使用特定库来反序列化特定对象群组,则可以在调用库时应用相关类的过滤器。创建类的允许列表并拒绝其他所有内容,可以防止流中未知或意外的对象。封装或其他自然应用程序或库分区边界可用于缩小允许或绝对不允许的对象集。
应用程序的开发人员处于了解应用程序组件的结构和操作的最佳位置。此增强功能使应用程序开发人员能够构建过滤器并将其应用于每个反序列化操作。
具体操作
如上所述,JEP 290 引入了 per-stream 反序列化过滤器和静态 JVM-wide 过滤器。每当ObjectInputStream创建一个时,它的每个流过滤器都会被初始化为静态 JVM 范围的过滤器。如果需要,可以稍后将每个流过滤器更改为不同的过滤器。
这里我们介绍一个可配置的 JVM 范围的过滤器工厂。每当ObjectInputStream创建an 时 ,它的每个流过滤器都会初始化为通过调用静态 JVM 范围过滤器工厂返回的值。因此,这些过滤器是动态的和特定于上下文的,与单个静态 JVM 范围的反序列化过滤器不同。为了向后兼容,如果未设置过滤器工厂,则内置工厂将返回静态 JVM 范围的过滤器(如果已配置)。
过滤器工厂用于 Java 运行时中的每个反序列化操作,无论是在应用程序代码、库代码中,还是在 JDK 本身的代码中。该工厂特定于应用程序,应考虑应用程序中的每个反序列化执行上下文。过滤器工厂从ObjectInputStream构造函数调用,也从 ObjectInputStream.setObjectInputFilter. 参数是当前过滤器和新过滤器。从构造函数调用时,当前过滤器是null,新过滤器是静态 JVM 范围的过滤器。工厂确定并返回流的初始过滤器。工厂可以使用其他特定于上下文的控件创建复合过滤器,或者只返回静态 JVM 范围的过滤器。如果ObjectInputStream.setObjectInputFilter被调用,工厂被第二次调用,并使用第一次调用返回的过滤器和请求的新过滤器。工厂决定如何组合两个过滤器并返回过滤器,替换流上的过滤器。
对于简单的情况,过滤器工厂可以为整个应用程序返回一个固定的过滤器。例如,这里有一个过滤器,它允许示例类,允许java.base模块中的类,并拒绝所有其他类:
var filter = ObjectInputFilter.Config.createFilter("example.*;java.base/*;!*")
在具有多个执行上下文的应用程序中,过滤器工厂可以通过为每个上下文提供自定义过滤器来更好地保护各个上下文。构建流时,过滤器工厂可以根据当前线程本地状态、调用者的层次结构、库、模块和类加载器来识别执行上下文。此时,用于创建或选择过滤器的策略可以根据上下文选择特定过滤器或过滤器组合。
如果存在多个过滤器,则可以合并它们的结果。组合过滤器的一种有用方法是,如果任何过滤器拒绝反序列化,则拒绝反序列化,如果任何过滤器允许,则允许反序列化,否则保持未定状态。
命令行使用
属性jdk.serialFilter和jdk.serialFilterFactory可以
在命令行上设置过滤器和过滤器工厂。现有jdk.serialFilter属性设置基于模式的过滤器。
该jdk.serialFilterFactory属性是在第一次反序列化之前要设置的过滤器工厂的类名。该类必须是公共的,并且可由应用程序类加载器访问。
为了与 JEP 290 兼容,如果jdk.serialFilterFactory未设置属性,则过滤器工厂将设置为提供与早期版本兼容的内置函数。
应用程序接口
我们在ObjectInputFilter.Config类中定义了两个方法来设置和获取 JVM 范围的过滤器工厂。过滤器工厂是一个有两个参数的函数,一个当前过滤器和一个下一个过滤器,它返回一个过滤器。
/**
* Return the JVM-wide deserialization filter factory.
*
* @return the JVM-wide serialization filter factory; non-null
*/
public static BinaryOperator<ObjectInputFilter> getSerialFilterFactory();
/**
* Set the JVM-wide deserialization filter factory.
*
* The filter factory is a function of two parameters, the current filter
* and the next filter, that returns the filter to be used for the stream.
*
* @param filterFactory the serialization filter factory to set as the
* JVM-wide filter factory; not null
*/
public static void setSerialFilterFactory(BinaryOperator<ObjectInputFilter> filterFactory);
示例
这个类展示了如何过滤到当前线程中发生的每个反序列化操作。它定义了一个线程局部变量来保存每个线程的过滤器,定义一个过滤器工厂来返回该过滤器,将工厂配置为 JVM 范围的过滤器工厂,并提供一个实用函数来Runnable在特定的 per 上下文中运行-线程过滤器。
public class FilterInThread implements BinaryOperator<ObjectInputFilter> {
// ThreadLocal to hold the serial filter to be applied
private final ThreadLocal<ObjectInputFilter> filterThreadLocal = new ThreadLocal<>();
// Construct a FilterInThread deserialization filter factory.
public FilterInThread() {}
/**
* The filter factory, which is invoked every time a new ObjectInputStream
* is created. If a per-stream filter is already set then it returns a
* filter that combines the results of invoking each filter.
*
* @param curr the current filter on the stream
* @param next a per stream filter
* @return the selected filter
*/
public ObjectInputFilter apply(ObjectInputFilter curr, ObjectInputFilter next) {
if (curr == null) {
// Called from the OIS constructor or perhaps OIS.setObjectInputFilter with no current filter
var filter = filterThreadLocal.get();
if (filter != null) {
// Prepend a filter to assert that all classes have been Allowed or Rejected
filter = ObjectInputFilter.Config.rejectUndecidedClass(filter);
}
if (next != null) {
// Prepend the next filter to the thread filter, if any
// Initially this is the static JVM-wide filter passed from the OIS constructor
// Append the filter to reject all UNDECIDED results
filter = ObjectInputFilter.Config.merge(next, filter);
filter = ObjectInputFilter.Config.rejectUndecidedClass(filter);
}
return filter;
} else {
// Called from OIS.setObjectInputFilter with a current filter and a stream-specific filter.
// The curr filter already incorporates the thread filter and static JVM-wide filter
// and rejection of undecided classes
// If there is a stream-specific filter prepend it and a filter to recheck for undecided
if (next != null) {
next = ObjectInputFilter.Config.merge(next, curr);
next = ObjectInputFilter.Config.rejectUndecidedClass(next);
return next;
}
return curr;
}
}
/**
* Apply the filter and invoke the runnable.
*
* @param filter the serial filter to apply to every deserialization in the thread
* @param runnable a Runnable to invoke
*/
public void doWithSerialFilter(ObjectInputFilter filter, Runnable runnable) {
var prevFilter = filterThreadLocal.get();
try {
filterThreadLocal.set(filter);
runnable.run();
} finally {
filterThreadLocal.set(prevFilter);
}
}
}
如果已经设置了特定于流的过滤器, ObjectInputStream::setObjectFilter则过滤器工厂将该过滤器与下一个过滤器组合。如果任一过滤器拒绝一个类,则该类将被拒绝。如果任一过滤器允许该类,则该类被允许。否则,结果未定。
这是使用FilterInThread该类的一个简单示例:
// Create a FilterInThread filter factory and set
var filterInThread = new FilterInThread();
ObjectInputFilter.Config.setSerialFilterFactory(filterInThread);
// Create a filter to allow example.* classes and reject all others
var filter = ObjectInputFilter.Config.createFilter("example.*;java.base/*;!*");
filterInThread.doWithSerialFilter(filter, () -> {
byte[] bytes = ...;
var o = deserializeObject(bytes);
});
三 其他变化
1_JEP 306:恢复始终严格的浮点语义
概括
使浮点运算始终严格,而不是同时具有严格的浮点语义 ( strictfp) 和略有不同的默认浮点语义。这将恢复语言和 VM 的原始浮点语义,匹配 Java SE 1.2 中引入严格和默认浮点模式之前的语义。
目标
- 简化数字敏感库的开发,包括
java.lang.Math和java.lang.StrictMath. - 在平台的一个棘手方面提供更多的规律性。
原因
1990 年代后期改变平台默认浮点语义的动力源于原始 Java 语言和 JVM 语义之间的不良交互以及流行的 x86 架构的 x87 浮点协处理器指令集的一些不幸特性. 在所有情况下匹配精确的浮点语义,包括非正规操作数和结果,需要大量额外指令的开销。在没有上溢或下溢的情况下匹配结果可以用更少的开销来实现,这大致是 Java SE 1.2 中引入的修改后的默认浮点语义所允许的。
但是,从 2001 年左右开始在奔腾 4 和更高版本的处理器中提供的 SSE2(流式 SIMD 扩展 2)扩展可以以直接的方式支持严格的 JVM 浮点运算,而不会产生过多的开销。
由于英特尔和 AMD 长期以来都支持 SSE2 和更高版本的扩展,这些扩展允许自然支持严格的浮点语义,因此不再存在具有不同于严格的默认浮点语义的技术动机。
具体细节描述
此 JEP 将修改的接口包括浮点表达式覆盖范围内的 Java 语言规范(请参阅JLS部分 4.2.3浮点类型、格式和值、5.1.13 值集转换、15.4 FP-strict Expressions、对第 15 章后面其他部分的许多小更新)和 Java 虚拟机规范的类似部分(JVMS 2.3.2浮点类型、值集和值*,第 2.8.2 节浮点模式,2.8.3值集)转换,以及对个别浮点指令的许多小更新)。值集和值集转换的概念将从 JLS 和 JVMS 中删除。JDK 中的实现更改将包括更新 HotSpot 虚拟机,使其永远不会在允许扩展指数值集的浮点模式下运行(这种模式必须存在于strictfp操作中)并更新javac以发出新的 lint 警告以防止不必要的使用的strictfp修饰符。
2_JEP 356:增强型伪随机数生成器
概括
为伪随机数生成器 (PRNG) 提供新的接口类型和实现,包括可跳转的 PRNG 和额外的一类可拆分 PRNG 算法 (LXM)。
目标
- 使在应用程序中交替使用各种 PRNG 算法变得更容易。
- 通过提供 PRNG 对象流更好地支持基于流的编程。
- 消除现有 PRNG 类中的代码重复。
- 小心地保留 class 的现有行为
java.util.Random。
原因
- 使用遗留的 PRNG 类
Random、ThreadLocalRandom和SplittableRandom,很难用其他算法替换应用程序中的任何一个,尽管它们都支持几乎相同的方法集。例如,如果一个应用程序使用 class 的实例Random,它必然会声明 type 的变量Random,它不能保存 class 的实例SplittableRandom;更改要使用的应用程序SplittableRandom需要更改用于保存 PRNG 对象的每个变量(包括方法参数)的类型。一个例外是它ThreadLocalRandom是 的子类Random,纯粹是为了允许 类型的变量Random保存 的实例ThreadLocalRandom,但ThreadLocalRandom几乎覆盖了 的所有方法Random。接口可以轻松解决这个问题。 - 传统类
Random,ThreadLocalRandom以及SplittableRandom所有支持等方法,nextDouble()和nextBoolean()以及流产生方法,如ints()和longs(),但他们拥有完全独立的,几乎复制和粘贴的方式工作。重构此代码将使其更易于维护,此外,文档将使第三方更容易创建新的 PRNG 类,这些类也支持相同的完整方法套件。 - 2016 年,测试揭示了 class 使用的算法中的两个新弱点
SplittableRandom。一方面,相对较小的修订可以避免这些弱点。另一方面,还发现了一类新的可拆分 PRNG 算法 (LXM),其速度几乎一样快,甚至更容易实现,并且似乎完全避免了容易出现的三类弱点SplittableRandom。 - 能够从 PRNG 获取 PRNG 对象流使得使用流方法表达某些类型的代码变得更加容易。
- 文献中有许多 PRNG 算法不是可拆分的,而是可跳跃的(也许也是可跳跃的,即能够进行非常长的跳跃和普通跳跃),这一特性与拆分完全不同,但也有助于支持流PRNG 对象。过去,很难在 Java 中利用这一特性。可跳转 PRNG 算法的示例是 Xoshiro256** 和 Xoroshiro128+。
- Xoshiro256** 和 Xoroshiro128+:http 😕/xoshiro.di.unimi.it
具体描述
我们提供了一个新接口,RandomGenerator为所有现有的和新的 PRNG 提供统一的 API。RandomGenerators提供命名方法ints,longs,doubles,nextBoolean,nextInt,nextLong, nextDouble,和nextFloat,与他们所有的当前参数的变化。
我们提供了四个新的专门的 RandomGenerator 接口:
SplittableRandomGenerator扩展RandomGenerator并提供
名为splitand 的方法splits。可拆分性允许用户从现有的 RandomGenerator 生成一个新的 RandomGenerator,这通常会产生统计上独立的结果。JumpableRandomGenerator扩展RandomGenerator并提供
名为jumpand 的方法jumps。可跳跃性允许用户跳过中等数量的平局。LeapableRandomGenerator扩展RandomGenerator并提供
名为leapand 的方法leaps。Leapability 允许用户跳过大量的抽奖。ArbitrarilyJumpableRandomGenerator扩展LeapableRandomGenerator并且还提供了jump和 的其他变体jumps,允许指定任意跳跃距离。
我们提供了一个新类RandomGeneratorFactory,用于定位和构造RandomGenerator实现的实例。在 RandomGeneratorFactory使用ServiceLoader.Provider注册API RandomGenerator的实现。
我们重构了Random, ThreadLocalRandom,SplittableRandom以便共享它们的大部分实现代码,此外,还使这些代码也可以被其他算法重用。这个重构创建底层非公抽象类AbstractRandomGenerator,AbstractSplittableRandomGenerator, AbstractJumpableRandomGenerator,AbstractLeapableRandomGenerator,和 AbstractArbitrarilyJumpableRandomGenerator,为每个方法提供仅实现nextInt(),nextLong()和(如果相关的话)任一split(),或jump(),或jump()和 leap(),或jump(distance)。经过这次重构,Random, ThreadLocalRandom, 和SplittableRandom继承了 RandomGenerator接口。注意,因为SecureRandom是 的子类 Random,所有的实例SecureRandom也自动支持该 RandomGenerator接口,无需重新编码SecureRandom 类或其任何相关的实现引擎。
我们还添加了底层非公共类,这些类扩展AbstractSplittableRandomGenerator (并因此实现SplittableRandomGenerator和RandomGenerator)以支持 LXM 系列 PRNG 算法的六个特定成员:
L32X64MixRandomL32X64StarStarRandomL64X128MixRandomL64X128StarStarRandomL64X256MixRandomL64X1024MixRandomL128X128MixRandomL128X256MixRandomL128X1024MixRandom
LXM 算法的中心 nextLong(或 nextInt)方法的结构遵循 Sebastiano Vigna 在 2017 年 12 月提出的建议,即使用一个 LCG 子生成器和一个基于异或的子生成器(而不是两个 LCG 子生成器)将提供更长的周期、优越的等分布、可扩展性和更好的质量。这里的每个具体实现都结合了目前最著名的基于异或的生成器之一(xoroshiro 或 xoshiro,由 Blackman 和 Vigna 在“Scrambled Linear Pseudorandom Number Generators”,ACM Trans. Math. Softw.,2021 中描述)与一个 LCG使用目前最著名的乘数之一(通过 Steele 和 Vigna 在 2019 年搜索更好的乘数找到),然后应用 Doug Lea 确定的混合函数。
我们还提供了这些广泛使用的 PRNG 算法的实现:
Xoshiro256PlusPlusXoroshiro128PlusPlus
上面提到的非公共抽象实现将来可能会作为随机数实现器 SPI 的一部分提供。
这套算法为 Java 程序员提供了空间、时间、质量和与其他语言兼容性之间的合理范围的权衡。
3_JEP 382:新的 macOS 渲染管线
概括
使用 Apple Metal API 为 macOS 实现 Java 2D 内部渲染管道,作为现有管道的替代方案,现有管道使用已弃用的 Apple OpenGL API。
目标
- 为使用 macOS Metal 框架的 Java 2D API 提供功能齐全的渲染管道。
- 如果 Apple 从未来版本的 macOS 中删除已弃用的 OpenGL API,请做好准备。
- 确保新管道到 Java 应用程序的透明度。
- 确保实现与现有 OpenGL 管道的功能奇偶校验。
- 在选定的实际应用程序和基准测试中提供与 OpenGL 管道一样好或更好的性能。
- 创建适合现有 Java 2D 管道模型的干净架构。
- 与 OpenGL 管道共存,直到它过时。
原因
两个主要因素促使在 macOS 上引入新的基于 Metal 的渲染管道:
- Apple于 2018 年 9 月在 macOS 10.14 中弃用了 OpenGL 渲染库。 macOS 上的Java 2D 完全依赖 OpenGL 进行其内部渲染管道,因此需要新的管道实现。
- Apple 声称Metal 框架(它们替代 OpenGL)具有卓越的性能。对于 Java 2D API,通常是这种情况,但有一些例外。
具体描述
大多数图形 Java 应用程序是使用 Swing UI 工具包编写的,该工具包通过 Java 2D API 呈现。在内部,Java 2D 可以使用软件渲染和屏幕上的 blit,也可以使用特定于平台的 API,例如 Linux 上的 X11/Xrender、Windows 上的 Direct3D 或 macOS 上的 OpenGL。这些特定于平台的 API 通常提供比软件渲染更好的性能,并且通常会减轻 CPU 的负担。Metal 是用于此类渲染的新 macOS 平台 API,取代了已弃用的 OpenGL API。(该名称与 Swing “金属”外观和感觉无关;这只是巧合。)
我们创建了大量新的内部实现代码来使用 Metal 框架,就像我们已经为其他特定于平台的 API 所做的那样。虽然很容易适应现有框架,但新代码在使用图形硬件方面更加现代,使用着色器而不是固定功能管道。这些更改仅限于特定于 macOS 的代码,甚至只更新了 Metal 和 OpenGL 之间共享的最少量代码。我们没有引入任何新的 Java API,也没有改变任何现有的 API。
Metal 管道可以与 OpenGL 管道共存。当图形应用程序启动时,会选择其中一个。目前,OpenGL 仍然是默认设置。仅当在启动时指定或 OpenGL 初始化失败时才使用 Metal,就像在没有 OpenGL 支持的未来版本的 macOS 中一样。
在集成此 JEP 时,Apple 尚未删除 OpenGL。在此之前,应用程序可以通过-Dsun.java2d.metal=true在java命令行上指定来选择加入 Metal 。我们将在未来的版本中将 Metal 渲染管线设为默认。
在集成到 JDK 之前,我们在Project Lanai 中对这个 JEP 进行了工作。
4_JEP 391:macOS/AArch64 端口
概括
将 JDK 移植到 macOS/AArch64。
原因
Apple 宣布了一项将其 Macintosh 计算机系列从 x64 过渡到 AArch64的长期计划。因此,我们希望看到对 JDK 的 macOS/AArch64 端口的广泛需求。
尽管可以通过 macOS 的内置Rosetta 2 转换器在基于 AArch64 的系统上运行 JDK 的 macOS/x64 版本,但该翻译几乎肯定会带来显着的性能损失。
具体描述
Linux 的 AArch64 端口(JEP 237)已经存在,Windows 的 AArch64 端口(JEP 388)的工作正在进行中。我们希望通过使用条件编译(在 JDK 的端口中很常见)来重用来自这些端口的现有 AArch64 代码,以适应低级约定的差异,例如应用程序二进制接口 (ABI) 和保留的处理器寄存器集。
macOS/AArch64 禁止内存段同时可执行和可写,这一策略称为write-xor-execute (W^X)。HotSpot VM 会定期创建和修改可执行代码,因此此 JEP 将在 HotSpot 中为 macOS/AArch64 实现 W^X 支持。
5_JEP 398:弃用 Applet API 以进行删除
概述
弃用 Applet API 以进行删除。它基本上无关紧要,因为所有 Web 浏览器供应商都已取消对 Java 浏览器插件的支持或宣布了这样做的计划。 Java 9 中的JEP 289先前已弃用 Applet API,但并未将其删除。
具体内容
弃用或移除标准 Java API 的这些类和接口:
java.applet.Appletjava.applet.AppletStubjava.applet.AppletContextjava.applet.AudioClipjavax.swing.JAppletjava.beans.AppletInitializer
弃用(删除)引用上述类和接口的任何 API 元素,包括以下中的方法和字段:
java.beans.Beansjavax.swing.RepaintManagerjavax.naming.Context
6_JEP 403:强封装 JDK 内部
概述
强烈封装 JDK 的所有内部元素,除了 关键的内部 API,如sun.misc.Unsafe. 不再可能通过单个命令行选项来放松内部元素的强封装,就像在 JDK 9 到 JDK 16 中那样。
这个 JEP 是JEP 396的继承者,它将 JDK 从默认的宽松强封装转换为默认 强封装,同时允许用户根据需要返回到轻松的姿势。本 JEP 的目标、非目标、动机、风险和假设部分与 JEP 396 的部分基本相同,但为了读者的方便在此处复制。
目标
- 继续提高 JDK 的安全性和可维护性,这是Project Jigsaw的主要目标之一。
- 鼓励开发人员从使用内部元素迁移到使用标准 API,以便他们和他们的用户可以轻松升级到未来的 Java 版本。
原因
多年来,各种库、框架、工具和应用程序的开发人员以损害安全性和可维护性的方式使用 JDK 的内部元素。特别是:
- 包的一些非
public类、方法和字段java.*定义了特权操作,例如在特定类加载器中定义新类的能力,而其他则传送敏感数据,例如加密密钥。尽管在java.*包中,但这些元素是 JDK 的内部元素。外部代码通过反射使用这些内部元素会使平台的安全性处于危险之中。 - 包的所有类、方法和字段
sun.*都是 JDK 的内部 API。大多数类,方法和领域com.sun.*,jdk.*以及org.*包也是内部API。这些 API 从来都不是标准的,从来没有得到支持,也从来没有打算供外部使用。外部代码使用这些内部元素是一种持续的维护负担。为了不破坏现有代码,保留这些 API 所花费的时间和精力可以更好地用于推动平台向前发展。
在 Java 9 中,我们通过利用模块来限制对其内部元素的访问,提高了 JDK 的安全性和可维护性。模块提供强封装,这意味着
- 模块外的代码只能访问该 模块导出的包的
public和protected元素,并且 protected此外,元素只能从定义它们的类的子类中访问。
强封装适用于编译时和运行时,包括编译代码尝试在运行时通过反射访问元素时。public导出包的非元素和未导出包的所有元素都被称为强封装。
在 JDK 9 及更高版本中,我们强烈封装了所有新的内部元素,从而限制了对它们的访问。然而,为了帮助迁移,我们故意选择不在运行时强封装 JDK 8 中已经存在的内部元素。因此类路径上的库和应用程序代码可以继续使用反射来访问非public元素的java.*包,以及所有元素sun.*和其他内部包,用于在JDK 8存在这种安排被称为包宽松强大的封装性,并且在JDK 9的默认行为。
我们早在 2017 年 9 月就发布了 JDK 9。 JDK 的大多数常用内部元素现在都有标准替代品。开发人员必须在三年中,从标准的API,如JDK的内部元素迁移走 java.lang.invoke.MethodHandles.Lookup::defineClass,java.util.Base64和java.lang.ref.Cleaner。许多库、框架和工具维护者已经完成了迁移并发布了其组件的更新版本。现在对宽松强封装的需求比 2017 年弱,而且逐年进一步减弱。
在 2021 年 3 月发布的 JDK 16 中,我们迈出了下一步,以强封装 JDK 的所有内部元素。 JEP 396将强封装作为默认行为,但关键的内部 API(如sun.misc.Unsafe)仍然可用。在 JDK 16 中,最终用户仍然可以选择宽松的强封装,以便访问 JDK 8 中存在的内部元素。
我们现在准备通过移除选择宽松强封装的能力,在这个旅程中再迈出一步。这意味着 JDK 的所有内部元素都将被强封装,除了关键的内部 API,如sun.misc.Unsafe.
具体描述
松弛强封装由启动器选项控制 --illegal-access。这个选项由JEP 261引入,被挑衅地命名以阻止其使用。在 JDK 16 及更早版本中,它的工作方式如下:
-
--illegal-access=permit安排 JDK 8 中存在的每个包都对未命名模块中的代码开放。因此,类路径上的代码可以继续使用反射来访问包的非公共元素java.*,以及sun.*JDK 8 中存在的包和其他内部包的所有元素。对任何此类元素的第一次反射访问操作会导致发出警告,但在那之后不会发出警告。此模式是 JDK 9 到 JDK 15 的默认模式。
-
--illegal-access=warn``permit除了针对每个非法反射访问操作发出警告消息之外,其他都相同。 -
--illegal-access=debug``warn除了为每个非法反射访问操作发出警告消息和堆栈跟踪之外,其他都相同。 -
--illegal-access=deny禁用所有非法访问操作,但由其他命令行选项启用的操作除外,例如,--add-opens。此模式是 JDK 16 中的默认模式。
作为强封装 JDK 的所有内部元素的下一步,我们建议使该--illegal-access选项过时。此选项的任何使用,无论是使用permit、warn、debug或deny,都不会产生任何影响,只会发出警告消息。我们希望--illegal-access在未来的版本中完全删除该选项。
通过此更改,最终用户将无法再使用该 --illegal-access选项来启用对 JDK 内部元素的访问。(影响到包的列表,请点击这里。) **的sun.misc和sun.reflect软件包将仍然由出口 jdk.unsupported模块,并且仍然是开放的,这样的代码可以通过反射访问他们的非公开内容。**不会以这种方式打开其他 JDK 包。
仍然可以使用--add-opens 命令行选项或Add-OpensJAR 文件清单属性来打开特定的包。
7_JEP 407:删除 RMI 激活
概括
删除远程方法调用 (RMI) 激活机制,同时保留 RMI 的其余部分。
原因
RMI 激活机制已过时且已废弃。它已被Java SE 15 中的JEP 385弃用。没有收到针对该弃用的评论。请参阅JEP 385了解完整的背景、原理、风险和替代方案。
Java EE 平台包含一项称为JavaBeans Activation Framework (JAF) 的技术。作为Eclipse EE4J计划的一部分,它后来更名为Jakarta Activation。JavaBeans Activation 和 Jakarta Activation 技术与 RMI Activation 完全无关,它们不受从 Java SE 中删除 RMI Activation 的影响。
具体描述
java.rmi.activation从 Java SE API 规范中删除包- 更新RMI 规范以删除提及 RMI 激活
- 去掉实现RMI激活机制的JDK库代码
- 删除 RMI 激活机制的 JDK 回归测试
- 删除 JDK 的
rmid激活守护进程及其文档
8_JEP 410:删除实验性 AOT 和 JIT 编译器
概括
删除实验性的基于 Java 的提前 (AOT) 和即时 (JIT) 编译器。该编译器自推出以来几乎没有什么用处,维护它所需的工作量很大。保留实验性的 Java 级 JVM 编译器接口 (JVMCI),以便开发人员可以继续使用外部构建的编译器版本进行 JIT 编译。
原因
提前编译(该jaotc工具)已通过JEP 295作为实验性功能合并到 JDK 9 中。该jaotc工具使用 Graal 编译器,它本身是用 Java 编写的,用于 AOT 编译。
Graal 编译器通过JEP 317在 JDK 10 中作为实验性 JIT 编译器提供。
自从引入这些实验性功能以来,我们几乎没有看到它们的使用,并且维护和增强它们所需的工作量很大。这些特性没有包含在 Oracle 发布的 JDK 16 版本中,并且没有人抱怨。
具体操作
删除三个 JDK 模块:
jdk.aot—jaotc工具jdk.internal.vm.compiler— Graal 编译器jdk.internal.vm.compiler.management— 格拉尔的MBean
保留这两个 Graal 相关的源文件,以便 JVMCI 模块 ( jdk.internal.vm.ci, JEP 243 ) 继续构建:
src/jdk.internal.vm.compiler/share/classes/module-info.javasrc/jdk.internal.vm.compiler.management/share/classes/module-info.java
删除与AOT编译相关的HotSpot代码:
src/hotspot/share/aot— 转储和加载 AOT 代码- 由保护的附加代码
#if INCLUDE_AOT
最后,删除测试以及与 Graal 和 AOT 编译相关的 makefile 中的代码。
9_JEP 411:弃用安全管理器以进行删除
概述
弃用安全管理器以在未来版本中移除。安全管理器可追溯到 Java 1.0。多年来,它一直不是保护客户端 Java 代码的主要手段,也很少用于保护服务器端代码。为了推动 Java 向前发展,我们打算弃用安全管理器,以便与旧 Applet API ( JEP 398 )一起删除。
目标
- 为开发人员在 Java 的未来版本中移除安全管理器做好准备。
- 警告用户他们的 Java 应用程序是否依赖于安全管理器。
- 评估是否需要新的 API 或机制来解决使用安全管理器的特定狭窄用例,例如阻塞
System::exit。
原因
Java 平台强调安全性。数据的完整性受到 Java 语言和 VM 内置内存安全的保护:变量在使用前被初始化,数组边界被检查,内存释放是完全自动的。同时,数据的机密性受到 Java 类库对现代加密算法和协议(如 SHA-3、EdDSA 和 TLS 1.3)的可信实现的保护。安全是一门动态的科学,因此我们不断更新 Java 平台以解决新的漏洞并反映新的行业态势,例如通过弃用弱加密协议。
一个长期存在的安全元素是安全管理器,它可以追溯到 Java 1.0。在 Web 浏览器下载 Java 小程序的时代,安全管理器通过在沙箱中运行小程序来保护用户机器的完整性及其数据的机密性,从而拒绝访问文件系统或网络等资源。Java 类库的小尺寸java.*——Java 1.0 中只有八个包——使得代码变得可行,例如,java.io在执行任何操作之前咨询安全管理器。安全管理器在不受信任的代码(来自远程机器的小程序)和受信任的代码之间划清了界限(本地机器上的类):它会批准所有涉及可信代码资源访问的操作,但拒绝不可信代码的资源访问。
随着对 Java 兴趣的增长,我们引入了签名小程序以允许安全管理器信任远程代码,从而允许小程序访问与通过java命令行运行的本地代码相同的资源。同时,Java 类库也在迅速扩展——Java 1.1 引入了 JavaBeans、JDBC、反射、RMI 和序列化——这意味着受信任的代码可以访问重要的新资源,如数据库连接、RMI 服务器和反射对象。允许所有受信任的代码访问所有资源是不可取的,因此在 Java 1.2 中,我们重新设计了安全管理器以专注于应用*最小权限原则:*默认情况下,所有代码都将被视为不受信任,受阻止访问资源的沙盒式控制的约束,并且用户将通过授予他们访问特定资源的特定权限来信任特定的代码库。理论上,类路径上的应用程序 JAR 在使用 JDK 的方式方面可能比来自 Internet 的小程序更受限制。限制权限被视为限制代码体中可能存在的任何漏洞影响的一种方式——实际上是一种纵深防御机制。
因此,安全经理希望防范两种威胁:恶意意图(尤其是远程代码)和意外漏洞(尤其是本地代码)。
由于 Java 平台不再支持小程序,远程代码的恶意威胁已经消退。Applet API在 2017 年在 Java 9 中被弃用,然后在 2021 年在 Java 17 中被弃用,并打算在未来的版本中将其删除。2018 年,运行小程序的闭源浏览器插件与闭源 Java Web Start 技术一起从 Oracle 的 JDK 11 中删除。因此,安全管理器防范的许多风险不再重要。此外,安全管理器无法防范许多现在很重要的风险。安全经理无法解决行业领导者在 2020 年确定的25 个最危险问题中的19 个,因此诸如 XML 外部实体引用 (XXE) 注入和不正确的输入验证等问题需要 Java 类库中的直接对策。(例如,JAXP 可以防止 XXE 攻击和 XML 实体扩展,而序列化过滤可以防止恶意数据在造成任何损害之前被反序列化。)安全管理器也无法防止基于推测执行漏洞的恶意行为。
不幸的是,安全管理器对恶意意图缺乏效力,因为安全管理器必须被编入 Java 类库的结构中。因此,这是一个持续的维护负担。必须评估所有新功能和 API,以确保它们在启用安全管理器时正确运行。基于最小特权原则的访问控制可以在Java 1.0中的类库已经可行,但快速增长java.*和javax.*包导致了整个 JDK 中的数十个权限和数百个权限检查。这是保持安全的一个重要表面区域,特别是因为权限可以以令人惊讶的方式进行交互。某些权限,例如,允许应用程序或库代码执行一系列安全操作,其整体效果足够不安全,如果直接授予则需要更强大的权限。
使用安全管理器几乎不可能解决本地代码中意外漏洞的威胁。许多声称安全管理器被广泛用于保护本地代码的说法经不起推敲。它在生产中的使用远比许多人想象的要少。它没有使用的原因有很多:
- 脆弱的权限模型— 希望从安全管理器中受益的应用程序开发人员必须仔细授予应用程序执行所有操作所需的所有权限。没有办法获得部分安全性,其中只有少数资源受到访问控制。例如,假设开发人员担心非法访问数据,因此希望授予仅从特定目录读取文件的权限。授予文件读取权限是不够的,因为应用程序几乎肯定会使用 Java 类库中除了读取文件(例如,写入文件)之外的其他操作,而这些其他操作将被安全管理器拒绝,因为代码将没有适当的许可。只有仔细记录他们的代码如何与 Java 类库中的安全敏感操作交互的开发人员才能授予必要的权限。这不是常见的开发人员工作流程。(安全管理员不允许否定权限,可以表示“授予除读取文件以外的所有操作的权限”。)
- 困难的编程模型——安全经理通过检查导致操作的所有运行代码的权限来批准安全敏感操作。这使得编写与安全管理器一起运行的库变得困难,因为库开发人员记录其库代码所需的权限是不够的。除了已授予该代码的任何权限之外,使用该库的应用程序开发人员还需要为其应用程序代码授予相同的权限。这违反了最小特权原则,因为应用程序代码可能不需要库的权限来进行自己的操作。库开发人员可以通过谨慎使用
java.security.AccessControllerAPI 要求安全管理器只考虑库的权限,但是这个和其他安全编码指南的复杂性远远超出了大多数开发人员的兴趣。应用程序开发人员的阻力最小的路径通常是授予AllPermission任何相关的 JAR 文件,但这又与最小权限原则背道而驰。 - 性能不佳——安全管理器的核心是一个复杂的访问控制算法,它通常会带来不可接受的性能损失。因此,默认情况下,对于在命令行上运行的 JVM,安全管理器始终处于禁用状态。这进一步降低了开发人员对投资使库和应用程序与安全管理器一起运行的兴趣。缺乏帮助推断和验证权限的工具是另一个障碍。
在引入安全管理器的四分之一个世纪以来,采用率一直很低。只有少数应用程序附带限制其自身操作的策略文件(例如,ElasticSearch)。类似地,只有少数框架附带策略文件(例如Tomcat),使用这些框架构建应用程序的开发人员仍然面临着确定他们自己的代码和他们使用的库所需的权限这一几乎无法克服的挑战。一些框架(例如NetBeans)避开策略文件而是实现自定义安全管理器以防止插件调用System::exit 或者深入了解代码的行为,例如它是否打开文件和网络连接——我们认为通过其他方式更好地服务的用例。
总之,使用安全管理器开发现代 Java 应用程序没有太大的兴趣。根据权限做出访问控制决策既笨拙又缓慢,并且在整个行业中失宠;例如,.NET不再支持它。通过在 Java 平台的较低级别提供完整性可以更好地实现安全性——例如,通过加强模块边界 ( JEP 403 ) 以防止访问 JDK 实现细节,并强化实现本身— 并通过容器和管理程序等进程外机制将整个 Java 运行时与敏感资源隔离。为了推动 Java 平台向前发展,我们将弃用从 JDK 中删除的旧安全管理器技术。我们计划在多个版本中弃用和削弱安全管理器的功能,同时为诸如阻塞等任务System::exit和其他被认为足够重要以进行替换的用例创建替代 API 。
具体操作
在 Java 17 中,我们将:
- 弃用(删除)大多数与安全管理器相关的类和方法。
- 如果在命令行上启用了安全管理器,则在启动时发出警告消息。
- 如果 Java 应用程序或库动态安装安全管理器,则在运行时发出警告消息。
在 Java 18 中,除非最终用户明确选择允许,否则我们将阻止 Java 应用程序或库动态安装安全管理器。从历史上看,Java 应用程序或库总是被允许动态安装安全管理器,但从Java 12 开始,最终用户已经能够通过在命令行 ( )上设置系统属性java.security.manager来阻止它——这会导致抛出. 在Java中18起,默认值将是,如果不通过其他方式设置。因此,调用的应用程序和库可能会由于意外的. 为了像以前一样工作,最终用户必须设置disallow``java -Djava.security.manager=disallow ...``System::setSecurityManager``UnsupportedOperationException``java.security.manager``disallow``java -D...``System::setSecurityManager``UnsupportedOperationException``System::setSecurityManager``java.security.manager到allow命令行 ( java -Djava.security.manager=allow ...)。
在 Java 18 及更高版本中,我们将降级其他安全管理器 API,以便它们保持原样,但功能有限或没有功能。例如,我们可以AccessController::doPrivileged简单地修改来运行给定的动作,或者修改System::getSecurityManager总是返回null。这将允许支持安全管理器并针对以前的 Java 版本编译的库继续工作而无需更改甚至重新编译。一旦这样做的兼容性风险下降到可接受的水平,我们希望删除这些 API。
在 Java 18 及更高版本中,我们可能会更改 Java SE API 定义,以便之前执行权限检查的操作不再执行它们,或者在启用安全管理器时执行更少的检查。因此,@throws SecurityException将出现在 API 规范中较少的方法中。
10_JEP 412:外部函数和内存 API(孵化器)
概括
介绍一个 API,Java 程序可以通过该 API 与 Java 运行时之外的代码和数据进行互操作。通过有效调用外部函数(即 JVM 之外的代码),以及安全地访问外部内存(即不由 JVM 管理的内存),API 使 Java 程序能够调用本地库和处理本地数据,而没有JNI。
历史
本 JEP 中提出的 API 是两个孵化 API 的演变:外部内存访问 API 和外部链接器 API。Foreign-Memory Access API 最初由JEP 370提出,并于 2019 年末针对 Java 14 作为孵化 API;它由Java 15 中的JEP 383和Java 16 中的JEP 393重新孵化。外部链接器 API 最初由JEP 389提出,并于 2020 年末针对 Java 16,也作为孵化 API。
目标
- 易用性— 用高级的纯 Java 开发模型替换 Java 本机接口 ( JNI )。
- 性能 — 提供与现有 API(例如 JNI 和
sun.misc.Unsafe. - 通用性— 提供对不同类型的外部内存(例如,本机内存、持久内存和托管堆内存)进行操作的方法,并随着时间的推移适应其他平台(例如,32 位 x86)和用其他语言编写的外部函数比 C(例如,C++、Fortran)。
- 安全——默认禁用不安全的操作,只有在应用程序开发人员或最终用户明确选择后才允许它们。
原因
Java 平台一直为希望超越 JVM 并与其他平台交互的库和应用程序开发人员提供丰富的基础。Java API 以方便可靠的方式公开非 Java 资源,无论是访问远程数据 (JDBC)、调用 Web 服务(HTTP 客户端)、服务远程客户端(NIO 通道)还是与本地进程通信(Unix 域套接字) . 不幸的是,Java 开发人员在访问一种重要的非 Java 资源时仍然面临重大障碍:与 JVM 位于同一台机器上但在 Java 运行时之外的代码和数据。
外部存储
存储在 Java 运行时之外的内存中的数据称为堆外数据。(堆是 Java 对象所在的地方——堆上数据——以及垃圾收集器工作的地方。)访问堆外数据对于Tensorflow、Ignite、Lucene和Netty等流行 Java 库的性能至关重要,主要是因为它让他们避免了与垃圾收集相关的成本和不可预测性。它还允许通过将文件映射到内存中来序列化和反序列化数据结构,例如mmap。然而,Java 平台目前还没有为访问堆外数据提供令人满意的解决方案。
- 该
ByteBufferAPI允许创建的直接被分配离堆字节缓冲区,但他们的最大大小为2 GB的,他们得不到及时释放。这些和其他限制源于这样一个事实,即ByteBufferAPI 不仅设计用于堆外内存访问,而且还用于生产者/消费者在字符集编码/解码和部分 I/O 操作等领域交换批量数据。在这种情况下,多年来提交的许多堆外增强请求(例如4496703、6558368、4837564和5029431)一直无法满足。 - 该
sun.misc.UnsafeAPI对堆数据自曝存储器存取操作也为离堆数据的工作。使用Unsafe是高效的,因为它的内存访问操作被定义为 HotSpot JVM 内部函数并由 JIT 编译器优化。但是,使用Unsafe是危险的,因为它允许访问任何内存位置。这意味着 Java 程序可以通过访问一个已经释放的位置来使 JVM 崩溃;由于这个原因和其他原因,Unsafe一直强烈反对使用。 - 使用 JNI 调用本地库然后访问堆外数据是可能的,但性能开销很少使它适用:从 Java 到本地比访问内存慢几个数量级,因为 JNI 方法调用没有从许多常见的JIT 优化,例如内联。
综上所述,在访问堆外数据时,Java 开发人员面临一个两难选择:他们应该选择安全但效率低下的路径 ( ByteBuffer) 还是应该放弃安全以支持性能 ( Unsafe)?他们需要的是用于访问堆外数据(即外部内存)的受支持 API,从头开始设计以确保安全并考虑到 JIT 优化。
外部函数
JNI 从 Java 1.1 开始就支持调用本机代码(即外部函数),但是由于多种原因它不够用。
- JNI 涉及几个乏味的工件:Java API(
native方法)、从 Java API 派生的 C 头文件,以及调用感兴趣的本机库的 C 实现。Java 开发人员必须跨多个工具链工作以保持依赖于平台的工件同步,这在本机库快速发展时尤其繁重。 - JNI 只能与用语言(通常是 C 和 C++)编写的库进行互操作,这些语言使用操作系统和 CPU 的调用约定,JVM 是为其构建的。一个
native方法不能被用来调用写在使用不同的约定语言的功能。 - JNI 不协调 Java 类型系统与 C 类型系统。Java 中的聚合数据是用对象表示的,而 C 中的聚合数据是用结构体表示的,因此任何传递给
native方法的Java 对象都必须由本机代码费力地解包。例如,考虑PersonJava 中的记录类:将Person对象传递给native方法将需要本机代码使用 JNI 的 C API从对象中提取字段(例如,firstName和lastName)。因此,Java 开发人员有时会将他们的数据扁平化为单个对象(例如,字节数组或直接字节缓冲区),但更多时候,由于通过 JNI 传递 Java 对象很慢,他们使用UnsafeAPI 来分配堆外内存和将其地址作为native方法传递给方法long— 这使得 Java 代码非常不安全!
多年来,出现了许多框架来填补 JNI 留下的空白,包括JNA、JNR和JavaCPP。尽管这些框架通常比 JNI 有了显着的改进,但情况仍然不太理想,尤其是与提供一流的本地互操作性的语言相比时。例如,Python 的ctypes包可以在本地库中动态包装函数,无需任何胶水代码。其他语言,例如Rust,提供了从 C/C++ 头文件机械地派生本机包装器的工具。
最终,Java 开发人员应该有一个受支持的 API,让他们可以直接使用任何被认为对特定任务有用的本机库,而不需要 JNI 的乏味粘连和笨拙。一个极好的构建方法是handles,它是在 Java 7 中引入的,用于支持 JVM 上的快速动态语言。通过方法句柄公开本机代码将从根本上简化编写、构建和分发依赖本机库的 Java 库的任务。此外,能够对外部函数(即本机代码)和外部内存(即堆外数据)进行建模的 API 将为第三方本机互操作框架提供坚实的基础。
描述
外部函数和内存 API (FFM API) 定义了类和接口,以便库和应用程序中的客户端代码可以
- 分配外部内存
(MemorySegment,MemoryAddress, 和SegmentAllocator), - 操作和访问结构化的外部内存
(MemoryLayout,MemoryHandles, 和MemoryAccess), - 管理外部资源的生命周期 (
ResourceScope),以及 - 调用外部函数(
SymbolLookup和CLinker)。
FFM API 位于模块的jdk.incubator.foreign包中jdk.incubator.foreign。
例子
作为使用 FFM API 的简短示例,这里是 Java 代码,它获取 C 库函数的方法句柄radixsort,然后使用它对 Java 数组中的四个字符串进行排序(省略了一些细节):
// 1. Find foreign function on the C library path
MethodHandle radixSort = CLinker.getInstance().downcallHandle(
CLinker.systemLookup().lookup("radixsort"), ...);
// 2. Allocate on-heap memory to store four strings
String[] javaStrings = { "mouse", "cat", "dog", "car" };
// 3. Allocate off-heap memory to store four pointers
MemorySegment offHeap = MemorySegment.allocateNative(
MemoryLayout.ofSequence(javaStrings.length,
CLinker.C_POINTER), ...);
// 4. Copy the strings from on-heap to off-heap
for (int i = 0; i < javaStrings.length; i++) {
// Allocate a string off-heap, then store a pointer to it
MemorySegment cString = CLinker.toCString(javaStrings[i], newImplicitScope());
MemoryAccess.setAddressAtIndex(offHeap, i, cString.address());
}
// 5. Sort the off-heap data by calling the foreign function
radixSort.invoke(offHeap.address(), javaStrings.length, MemoryAddress.NULL, '\0');
// 6. Copy the (reordered) strings from off-heap to on-heap
for (int i = 0; i < javaStrings.length; i++) {
MemoryAddress cStringPtr = MemoryAccess.getAddressAtIndex(offHeap, i);
javaStrings[i] = CLinker.toJavaStringRestricted(cStringPtr);
}
assert Arrays.equals(javaStrings, new String[] {"car", "cat", "dog", "mouse"}); // true
这段代码比任何使用 JNI 的解决方案都清晰得多,因为隐藏在native方法调用后面的隐式转换和内存取消引用现在直接用 Java 表示。也可以使用现代 Java 习语;例如,流可以允许多个线程在堆上和堆外内存之间并行复制数据。