paper
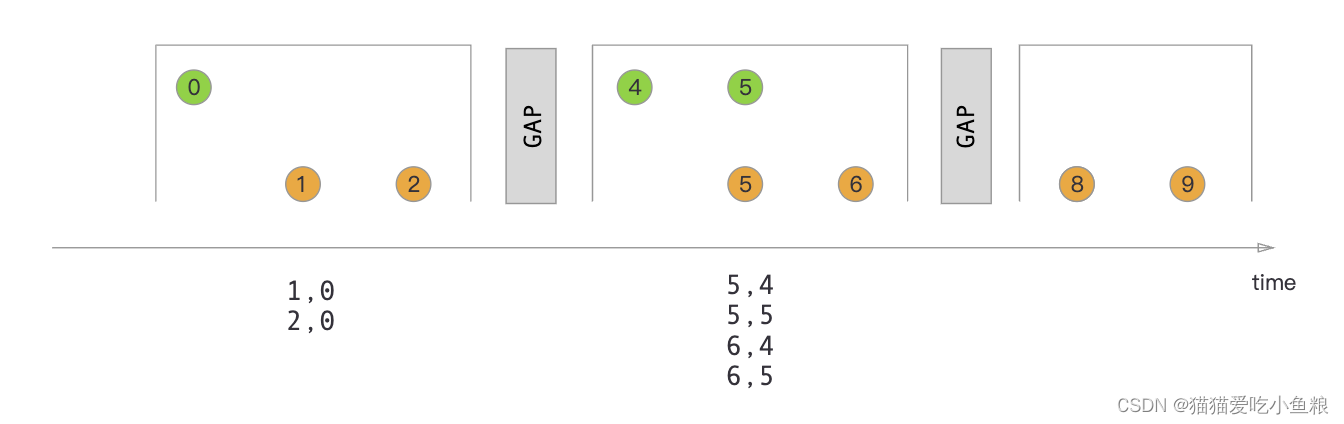
基于HIM的离线RL算法,解决基于序列模型的离线强化学习算法缺乏对序列拼接能力。
Intro
文章提出了ContextFormer,旨在解决决策变换器(Decision Transformer, DT)在轨迹拼接(stitching)能力上的不足。轨迹拼接是离线RL中一个重要的能力,它允许算法通过组合次优的轨迹片段来获得更优的策略。ContextFormer通过集成基于上下文信息的模仿学习(Imitation Learning, IL)和序列建模,模仿有限数量专家轨迹的表示,来实现次优轨迹片段的拼接。实验结果表明,ContextFormer在多模仿学习设置下具有竞争力,并且在与其他DT变体的比较中表现出色。
两个定义

 上述两个定义分别给出基于隐变量的条件序列模型建模方式,以及使用专家序列,通过度量经过embedding后的变量距离,使得待优化策略应满足靠近专家策略,远离次优轨迹策略。对于定义二有如下形式化的目标来优化上下文隐变量表征
上述两个定义分别给出基于隐变量的条件序列模型建模方式,以及使用专家序列,通过度量经过embedding后的变量距离,使得待优化策略应满足靠近专家策略,远离次优轨迹策略。对于定义二有如下形式化的目标来优化上下文隐变量表征
J
z
∗
=
min
z
∗
,
I
ϕ
E
τ
∗
∼
π
∗
(
τ
)
[
∥
z
∗
−
I
ϕ
(
τ
∗
)
∥
]
−
E
τ
^
∼
π
^
[
∥
z
∗
−
I
ϕ
(
τ
^
)
∥
]
,
\mathcal{J}_{\mathbf{z}^{*}}=\operatorname*{min}_{\mathbf{z}^{*},I_{\phi}}\mathbb{E}_{\tau^{*}\sim\pi^{*}(\tau)}[\|\mathbf{z}^{*}-I_{\phi}(\tau^{*})\|]\\-\mathbb{E}_{\hat{\tau}\sim\hat{\pi}}[\|\mathbf{z}^{*}-I_{\phi}(\hat{\tau})\|],
Jz∗=z∗,IϕminEτ∗∼π∗(τ)[∥z∗−Iϕ(τ∗)∥]−Eτ^∼π^[∥z∗−Iϕ(τ^)∥],
Method

ContextFormer的训练过程包括两个关键模型:Hindsight Information Extractor I ϕ I_{\phi} Iϕ和Contextual Policy。Hindsight Information Extractor使用BERT作为编码器,并采用VQ-VAE(Vector Quantization Variational Autoencoder)损失来训练。Contextual Policy则是一个基于潜在条件的序列模型(DT),通过上下文信息作为目标来优化策略接近专家策略。
根据定义4.1建模序列模型以及
I
ϕ
I_{\phi}
Iϕ,通过监督学习方式优化上下文策略
π
z
\pi_z
πz以及HI extractor。
J
π
z
,
I
ϕ
=
E
τ
∼
(
π
∗
,
π
^
)
[
∥
π
z
(
⋅
∣
I
ϕ
(
τ
)
,
s
0
,
a
0
,
⋯
,
I
ϕ
(
τ
)
,
s
t
)
−
a
t
∥
]
,
(
4
)
\mathcal{J}_{\pi_{\mathbf{z}},I_{\phi}}=\mathbb{E}_{\tau\sim(\pi^{*},\hat{\pi})}[\|\pi_{\mathbf{z}}(\cdot|I_{\phi}(\tau),\mathbf{s}_{0},\mathbf{a}_{0},\cdots,I_{\phi}(\tau),\mathbf{s}_{t})-\mathbf{a}_{t}\|], (4)
Jπz,Iϕ=Eτ∼(π∗,π^)[∥πz(⋅∣Iϕ(τ),s0,a0,⋯,Iϕ(τ),st)−at∥],(4)
其中
π
^
a
n
d
π
∗
\hat{\pi}\mathrm{~and~}\pi^{*}
π^ and π∗分别表示次优策略以及专家策略。同时,基于定义4.2对
I
ϕ
I_\phi
Iϕ以及上下文embedding
z
∗
z^*
z∗进行优化。
J
z
∗
,
I
ϕ
=
min
z
∗
,
I
ϕ
E
τ
^
∼
π
^
(
τ
)
,
τ
∗
∼
π
∗
(
τ
)
[
∥
z
∗
−
I
ϕ
(
τ
∗
)
∥
−
∣
∣
z
∗
−
I
ϕ
(
τ
^
)
∣
∣
]
(
5
)
\mathcal{J}_{\mathbf{z}^{*},I_{\phi}}=\min_{\mathbf{z}^{*},I_{\phi}}\mathbb{E}_{\hat{\tau}\sim\hat{\pi}(\tau),\tau^{*}\sim\pi^{*}(\tau)}[\|\mathbf{z}^{*}-I_{\phi}(\tau^{*})\|-||\mathbf{z}^{*}-I_{\phi}(\hat{\tau})||] (5)
Jz∗,Iϕ=z∗,IϕminEτ^∼π^(τ),τ∗∼π∗(τ)[∥z∗−Iϕ(τ∗)∥−∣∣z∗−Iϕ(τ^)∣∣](5)
除此外,对于
I
ϕ
I_\phi
Iϕ还需VQ-loss进行优化,三者联合构成了VQ-VAE的训练损失函数。

伪代码

(伪代码Training部分的第二步,VQ-loss应对应公式20)
结果