引言
Scrapy是一个用Python编写的开源、功能强大的网络爬虫框架,专为网页抓取和数据提取设计。它允许开发者高效地从网站上抓取所需的数据,并通过一系列可扩展和可配置的组件来处理这些数据。Scrapy框架的核心组成部分包括:
- Scrapy Engine(引擎): 负责控制数据流,协调各个组件之间的交互,实现爬虫的逻辑。
- Scheduler(调度器): 负责管理待抓取的请求队列,决定下一个要抓取的请求是什么。
- Downloader(下载器): 负责处理调度器传来的请求,获取网页内容,并将其传递给Spider处理。
- Spiders(爬虫): 自定义类,定义了如何解析下载回来的网页内容,并提取结构化数据(Items)。每个Spider负责处理一个或一组特定的网站或页面结构。
- Item Pipeline(项目管道): 数据处理的流水线,负责处理Spider提取的数据,进行清洗、验证、去重、存储等操作。每个项目经过一系列的Pipeline组件,直至处理完成。
- Middlewares(中间件): 分为请求/响应中间件和Spider中间件,位于引擎和其他组件之间,可以全局地处理请求、响应或改变数据流向,提供了高度的灵活性和可扩展性。
Scrapy的特点和优势包括:
易于使用和部署: 提供了命令行工具简化了项目的创建、运行和管理。
灵活性和可扩展性: 设计为高度模块化,可以很容易地自定义或替换组件以满足特定需求。
高性能: 基于Twisted异步网络库,支持并发下载,能够高效处理大量请求。
广泛的应用场景: 适用于数据挖掘、价格监控、市场研究、搜索引擎优化等领域。
Scrapy通过定义良好的API和组件模型,使得开发者能够快速构建复杂的爬虫,同时保持代码的整洁和可维护性。
本篇文章爬取豆瓣网站top250电影 参考b站视频
【1小时学会爬取豆瓣热门电影,快速上手Scrapy爬虫框架,python爬虫快速入门!】 https://www.bilibili.com/video/BV18a411777v/?share_source=copy_web&vd_source=70bc998418623a0cee8f4ac32d696e49
一、在命令窗口中使用命令创建一个scrapy项目
首先我们进行安装有scrapy框架的虚拟环境下的scripts目录下,用scrapy startproject项目名称,来创建一个scrapy爬虫项目。
在希望scrapy项目放置位置的文件夹下运行如下命令:
scrapy startproject douban_spider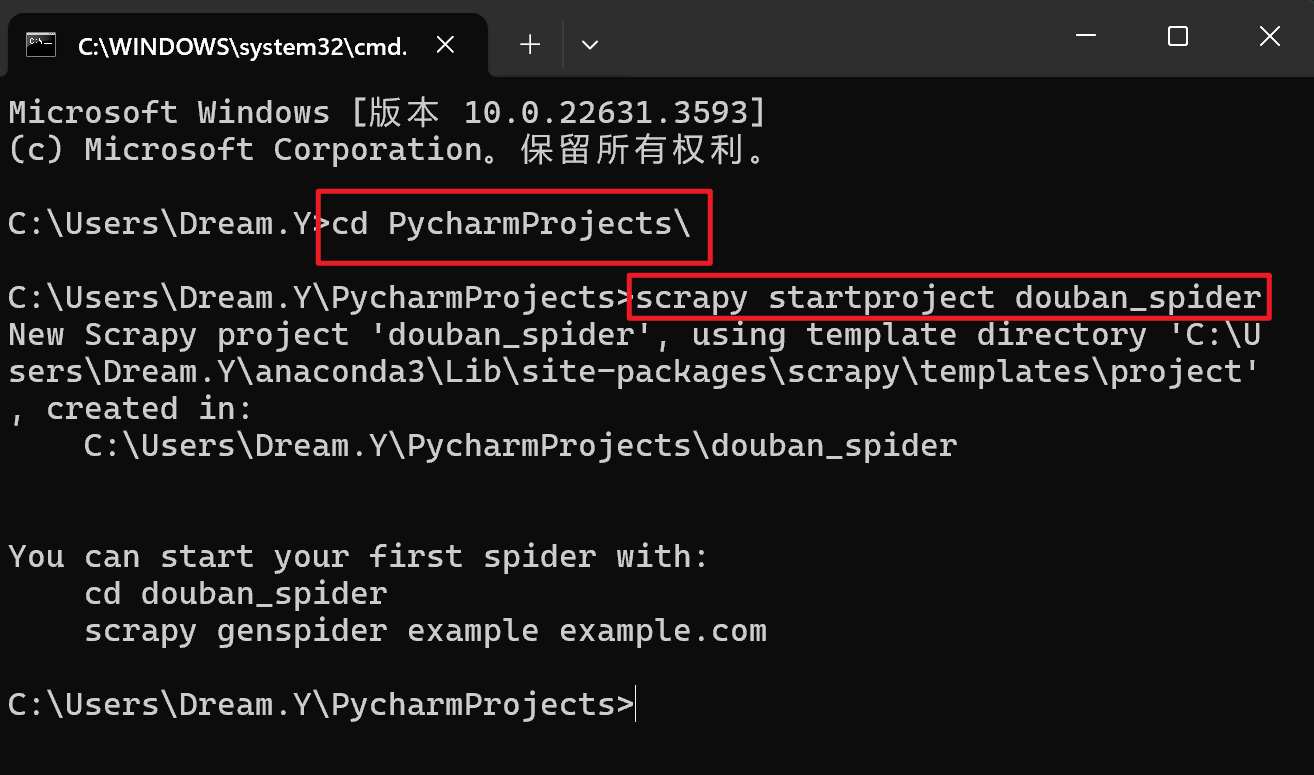
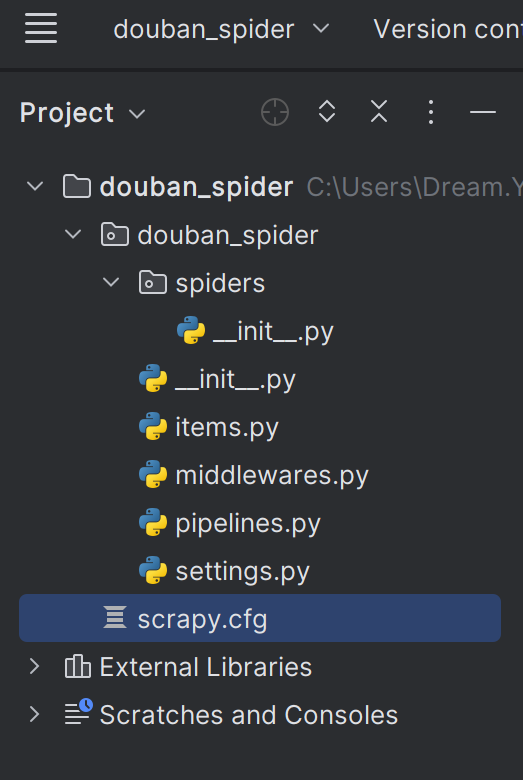
在pycharm编辑器打开改项目,生成的项目结构如下:
二、在items.py文件中定义字段
这些字段用来临时存储我们要去抓取的结构化数据,方便后面保数据到其他地方,比如数据库或者本地文本之类。
Item文件编写
- Item是保存爬取到的数据的容器;其使用方法和Python字典类似,并且提供了额外保护机制来避免拼写错误导致的未定义字段错误。
- 以豆瓣电影Top250 为例,我们需要抓取每一步电影的名字,电影的评分以及电影的评分人数。
- 豆瓣电影 Top 250 (douban.com)
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class DoubanSpiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() # 电影名字
star = scrapy.Field() # 评分
critical = scrapy.Field() # 评分人数
pass
三、在piplines.py中存储自己的数据,我们在此存储为csv格式
- 我们准备把分析提取出来的结构化数据存储为csv格式。首先在piplines文件中创建一个类,在该类的构造函数中创建一个文件对象,然后在process_item函数中做数据存储处理(编码成utf-8格式),最后关闭文件。
piplines.py文件代码如下:
class DoubanSpiderPipeline:
def __init__(self):
self.file = open("d:/douban.csv", "wb")
def process_item(self, item, spider):
str = item['title'].encode('utf-8') + b',' + item['star'].encode('utf-8') + b',' + item['critical'].encode(
'utf-8') + b'\n'
self.file.write(str)
return item
def close_spider(self, spider):
self.file.close()四、爬虫逻辑文件编写
把每个文件都配置好之后,就可以自己写一个逻辑处理文件,在spiders目录下创建一个douban.py文件,在改文件中我们写业务逻辑处理,主要是爬取,解析,把解析的内容结构化等等。
# encoding:utf-8
import scrapy
from scrapy.spiders import CrawlSpider
from scrapy.http import Request
from scrapy.selector import Selector
from douban_spider.items import DoubanSpiderItem
# 定义一个类 继承
class Douban(CrawlSpider):
name = "douban" # 爬虫项目名
allowed_domains = ['douban.com'] # 爬取的域名
start_urls = ['https://movie.douban.com/top250'] # 爬取的页面网址
# 请求是分布式的
def start_requests(self):
for url in self.start_urls:
yield Request(url=url, callback=self.parse)
def parse(self, response):
item = DoubanSpiderItem()
selector = Selector(response)
Movies = selector.xpath('//div[@class="info"]')
for eachMovie in Movies:
title = eachMovie.xpath('div[@class="hd"]/a/span/text()').extract()[0]
star = eachMovie.xpath('div[@class="bd"]/div/span[@class="rating_num"]/text()').extract()[0]
critical = eachMovie.xpath('div[@class="bd"]/div/span/text()').extract()[1]
item['title'] = title
item['star'] = star
item['critical'] = critical
yield item
nextLink = selector.xpath('//span[@class="next"]/a/@href').get()
# 确保nextLink有效且不是最后一页
if nextLink and 'javascript:void(0)' not in nextLink:
# 注意处理相对路径
if not nextLink.startswith(('http:', 'https:')):
nextLink = response.urljoin(nextLink)
yield Request(url=nextLink, callback=self.parse)
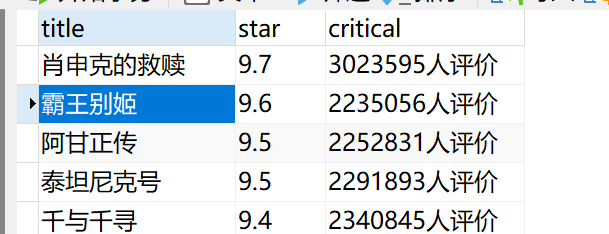
运行程序
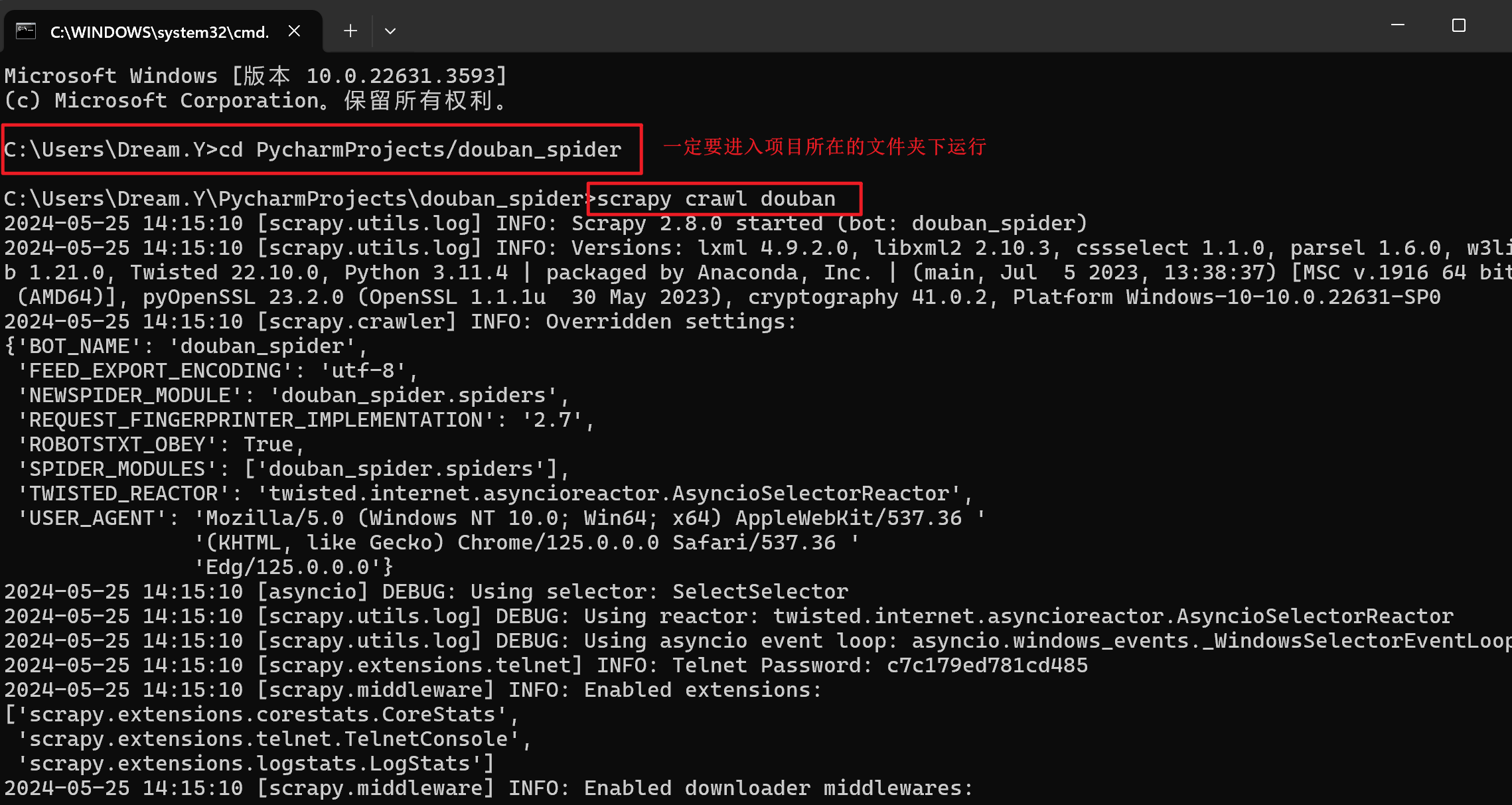
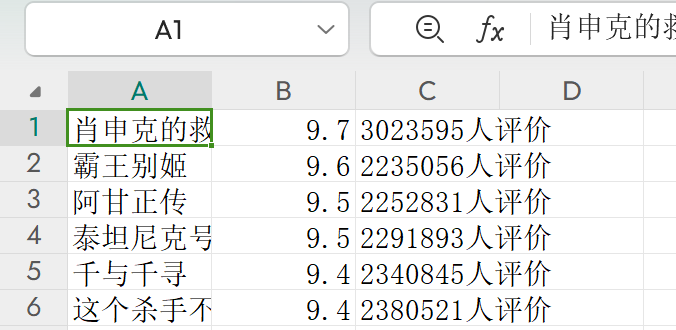
得到的csv文件如下:
*Settings文件编写
- 该文件不是必须要编写,我们完全可以把配置放在其他相应的文件中,比如headers放在页面逻辑抓取文件中,文件或数据库配置放在Pipeline文件中等等。
*如果需要转存到数据库方法
import csv
import mysql.connector
from mysql.connector import Error
# MySQL数据库连接参数
db_config = {
'host': '127.0.0.1', # 数据库主机地址
'user': 'root', # 数据库用户名
'password': '021211', # 数据库密码
'database': 'douban' # 数据库名称
}
# CSV文件路径
csv_file_path = 'd:/douban.csv'
try:
# 连接到MySQL数据库
connection = mysql.connector.connect(**db_config)
if connection.is_connected():
db_info = connection.get_server_info()
print(f"Successfully connected to MySQL Server version {db_info}")
cursor = connection.cursor()
columns = ["title", "star", "critical"] # 替换为你的列名
# 读取CSV文件并插入数据
with open(csv_file_path, mode='r', encoding='utf-8') as file:
csv_reader = csv.reader(file)
next(csv_reader)
for row in csv_reader:
placeholders = ', '.join(['%s'] * len(row))
query = f"INSERT INTO douban_spider ({', '.join(columns)}) VALUES ({placeholders})"
cursor.execute(query, tuple(row))
# 提交事务
connection.commit()
print(f"{cursor.rowcount} rows were inserted successfully.")
except Error as e:
print(f"Error while connecting to MySQL: {e}")
finally:
# 关闭连接
if connection.is_connected():
cursor.close()
connection.close()
print("MySQL connection is closed.")