背景
- 业务部门提供了一个数据,数据甚至不是excel类型的,是data
.txt,每一行都是一个数据,需要对此数据进行统计分析
统计各个月份的销量
- 因为直接获取resources下的data.txt,所以要借助输入流进行获取数据,再通过BufferedReader 将数据传递给流
- 想要
对key进行排序,推荐使用TreeMap
public class Main4 {
static final int INDEX = 0; // 索引
static final int DATETIME = 1; // 日期
static final int ORDERID = 2; // 订单号
static final int ITEMID = 3; // 商品编号
static final int AMOUNT = 4; // 数量
static final int PRICE = 5; // 价格
static final int TOTAL = 6; // 总价
public static void main(String[] args) {
try (
// 读取文件 通过ClassLoader获取文件流
InputStream is = Main4.class.getClassLoader().getResourceAsStream("data.txt");
// 将InputStream 装换为 Stream<String>
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(is));
Stream<String> lines = bufferedReader.lines()
) {
// 测试一下流是否生成
// lines.forEach(System.out::println);
// 统计每个月的的订单数量
// 定义一个格式化模版 用于解析日期
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
lines.map(line -> line.split(",")) // 将每一行数据转换为数组 分隔符是逗号
// 将日期字符串解析为YearMonth对象 用于统计月份
// 通过Collectors.groupingBy方法进行分组统计
// 第一个参数是分组的key 可以理解为提取器
// 第二个参数是容器类型 TreeMap::new 用于指定分组后的Map类型 第二个参数可以不指定,默认是hashMap 但是hashMap是无序的 这里使用TreeMap 有序
// 第三个参数是下游收集器 用于统计数量 Collectors.counting()
.collect(Collectors.groupingBy((arr -> YearMonth.from( dateTimeFormatter.parse(arr[DATETIME])) ), TreeMap::new, Collectors.counting())) // 统计每个月的订单数量
.forEach((k, v) -> System.out.println(k + "月订单数量:" + v));
} catch (Exception e) {
e.printStackTrace();
}
}
}
获取订单最大的月份
- 对TreeMap中的entrySet的数值进行遍历,获取最大值
- max
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
TreeMap<YearMonth, Long> collect = lines.map(line -> line.split(",")) // 将每一行数据转换为数组 分隔符是逗号
// 将日期字符串解析为YearMonth对象 用于统计月份
// 通过Collectors.groupingBy方法进行分组统计
// 第一个参数是分组的key 可以理解为提取器
// 第二个参数是容器类型 TreeMap::new 用于指定分组后的Map类型 第二个参数可以不指定,默认是hashMap 但是hashMap是无序的 这里使用TreeMap 有序
// 第三个参数是下游收集器 用于统计数量 Collectors.counting()
.collect(Collectors.groupingBy((arr -> YearMonth.from(dateTimeFormatter.parse(arr[DATETIME]))), TreeMap::new, Collectors.counting()));// 统计每个月的订单数量
// 对结果进行stream遍历 获取最大值
collect.entrySet().stream().max(Comparator.comparing(Map.Entry::getValue)).ifPresent(System.out::println);
获取销量最高的产品
// 获取销售数量最多的商品
private static void getMaxSaleCount(Stream<String> lines){
Map<String, Integer> collect = lines.map(line -> line.split(","))
.collect(Collectors.groupingBy(arr -> arr[ITEMID], Collectors.summingInt(arr -> Integer.parseInt(arr[AMOUNT])))
);
collect.entrySet().stream().max(Comparator.comparing(Map.Entry::getValue)).ifPresent(System.out::println);
}
获取销量最高的两个产品
// 获取销售数量前两的商品
private static void getTop2SaleCount(Stream<String> lines){
Map<String, Integer> collect = lines.map(line -> line.split(","))
.collect(Collectors.groupingBy(arr -> arr[ITEMID], Collectors.summingInt(arr -> Integer.parseInt(arr[AMOUNT])))
);
collect.entrySet().stream().sorted((a,b)->{
return a.getValue().compareTo(b.getValue()) * -1;
}).limit(2).forEach(System.out::println);
}
// 获取销售数量前两的商品
private static void getTop2SaleCount(Stream<String> lines){
Map<String, Integer> collect = lines.map(line -> line.split(","))
.collect(Collectors.groupingBy(arr -> arr[ITEMID], Collectors.summingInt(arr -> Integer.parseInt(arr[AMOUNT])))
);
collect.entrySet().stream().sorted(
Comparator.comparing(Map.Entry<String,Integer>::getValue).reversed()
)
.limit(2).forEach(System.out::println);
}
使用小顶堆来实现
- 如果数据量很大,把所有的商品的销售数量统计出来,资源占用很大
- 可以使用小顶堆,每次只统计最大的10个,当有新的数据进来的时候,和最小的数值进行比较,如果新值大于最小值,则根据小顶堆的规则插入进去
小顶堆的规则:父节点的值小于子节点的值,根节点的值最小
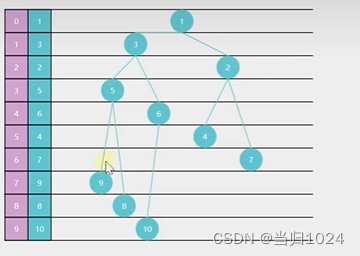
- 小顶堆的个数是无限的,我们需要重写一下offer方法
// 写一个小顶堆的子类,最多存储2个数据
static class MyQueue<E> extends PriorityQueue<E>{
private int max;
public MyQueue(Comparator<? super E> comparator,int max) {
super(comparator);
this.max = max;
}
@Override
public boolean offer(E e) {
boolean r = super.offer(e);
if(size() > max){
poll();
}
return r;
}
}
// 获取销售数量前两的商品
private static void getTop2SaleCount(Stream<String> lines){
Map<String, Integer> collect = lines.map(line -> line.split(","))
.collect(Collectors.groupingBy(arr -> arr[ITEMID], Collectors.summingInt(arr -> Integer.parseInt(arr[AMOUNT])))
);
MyQueue<Map.Entry<String, Integer>> myQueue = collect.entrySet().stream().collect(
() -> new MyQueue<>(Comparator.comparingInt(Map.Entry<String, Integer>::getValue), 2),
(queue, entry) -> queue.offer(entry), // 将entry加入到queue中
(queue1, queue2) -> queue1.addAll(queue2) // 没用并行流,其实这段代码用不上
);
while (!myQueue.isEmpty()){
System.out.println(myQueue.poll());
}
}
获取每种商品下单数量最多的用户
- 先使用商品进行分类,再使用用户进行分类,最后统计数量
// 获取每种商品下单最多的用户 打印 商品 用户 数量
private static void getMaxOfPerItem(Stream<String> lines){
// 先使用商品进行分类,再使用用户进行分类,最后统计数量
Map<String, Map<String, Integer>> collect = lines.map(line -> line.split(","))
.collect(Collectors.groupingBy(arr -> arr[ITEMID],
Collectors.groupingBy(arr -> arr[USERID], Collectors.summingInt(arr -> Integer.parseInt(arr[AMOUNT])))
));
// 打印一下每种商品下单的用户以及数量
// collect.forEach((k, v) -> {
// v.entrySet().stream().forEach(entry -> System.out.println(k + " " + entry.getKey() + " " + entry.getValue()));
// });
collect.forEach((k, v) -> {
v.entrySet().stream().max(Comparator.comparing(Map.Entry::getValue)).ifPresent(entry -> System.out.println(k + " " + entry.getKey() + " " + entry.getValue()));
});
}
获取每种商品下单前二的用户
- 使用双重groupingBy进行分组
- 使用自定义的小顶堆,获取每组前两个的用户
private static void getTop2OfPerItem(Stream<String> lines){
// 先使用商品进行分类,再使用用户进行分类,最后统计数量
Map<String, Map<String, Integer>> collect = lines.map(line -> line.split(","))
.collect(Collectors.groupingBy(arr -> arr[ITEMID],
Collectors.groupingBy(arr -> arr[USERID], Collectors.summingInt(arr -> Integer.parseInt(arr[AMOUNT])))
));
// 打印一下每种商品下单的用户以及数量
// collect.forEach((k, v) -> {
// v.entrySet().stream().forEach(entry -> System.out.println(k + " " + entry.getKey() + " " + entry.getValue()));
// });
collect.forEach((k, v) -> {
MyQueue<Map.Entry<String, Integer>> myQueue = v.entrySet().stream().collect(
() -> new MyQueue<>(Comparator.comparingInt(Map.Entry<String, Integer>::getValue), 2),
(queue, entry) -> queue.offer(entry), // 将entry加入到queue中
(queue1, queue2) -> queue1.addAll(queue2) // 没用并行流,其实这段代码用不上
);
while (!myQueue.isEmpty()){
System.out.println(k + " " + myQueue.poll());
}
});
}
按照总金额的区间 统计每个区间的数量
// 按照订单总金额的区间划分,统计每个区间的订单数量 小于500 500-1000 1000-1500 1500 以上的
private static void getTotalAmount(Stream<String> lines){
lines.map(line -> line.split(","))
.collect(Collectors.groupingBy(arr -> {
double total = Double.parseDouble(arr[TOTAL]);
if(total < 500){
return "小于500";
}else if(total < 1000){
return "500-1000";
}else if(total < 1500){
return "1000-1500";
}else {
return "1500以上";
}
}, Collectors.counting()))
.forEach((k, v) -> System.out.println(k + " " + v));
}