文章目录
- 准备工作
- Flink DataSet API
- Flink DataStream API
- 结论
准备工作
pom依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.chad</groupId>
<artifactId>guigu_learning_flink</artifactId>
<version>1.0-SNAPSHOT</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
<properties>
<flink.version>1.14.2</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>1.7.30</slf4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 日志管理 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
</dependency>
</dependencies>
</project>
创建word.txt
在项目下创建input目录,并创建word.txt文件

Flink DataSet API
创建java类BatchWordCount
package org.chad.wordcount;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class BatchWordCount {
public static void main(String[] args) throws Exception {
//1. 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//2. 读取数据源,从文件中读取
final DataSource<String> fileDS = env.readTextFile("input/word.txt");
//3. 转换算子操作环节,将数据转换为二元组
FlatMapOperator<String, Tuple2<String, Long>> wordAndOne = fileDS.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
//3. 将一行文本进行拆分,将每个单词转换为二元组输出
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
//4. 按照word进行分组
UnsortedGrouping<Tuple2<String, Long>> wordAndOneGroup = wordAndOne.groupBy(0);
//5. 分组内进行聚合统计
AggregateOperator<Tuple2<String, Long>> wordAndOneSum = wordAndOneGroup.sum(1);
//6. 对结果打印输出
wordAndOneSum.print();
}
}
补充说明:
以上方式为dataset api 官放在1.12之后已经将其视为软弃用状态,使用批流一体的方式,怎么运行批处理,只需要在执行任务时,
$ bin/flink run -Dexecution.runtime-mode=BATCH BatchWordCount.jar
运行结果
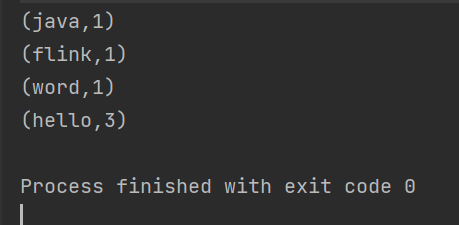
Flink DataStream API
创建java类BoundedStreamWordCount
package org.chad.wordcount;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class BoundedStreamWordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> ds = env.readTextFile("input/word.txt");
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = ds.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
KeyedStream<Tuple2<String, Long>, String> tuple2StringKeyedStream = wordAndOne.keyBy(data -> data.f0);
SingleOutputStreamOperator<Tuple2<String, Long>> sum = tuple2StringKeyedStream.sum(1);
sum.print();
env.execute("流处理");
}
}
因为是流处理,所以最后一定要加上env.execute(), 去执行以下它
它的运行结果
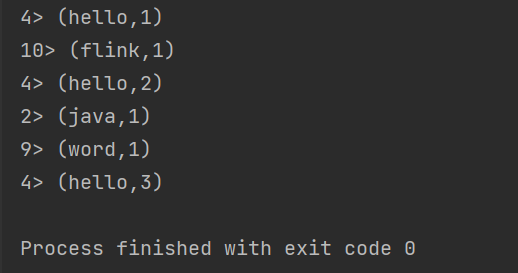
结论
- 我们可以看到DataStream API的形式输出的结果是一条一条的去相加的,并且每一行前面会有一个进程号
- 批处理是一下子全部输出的
- 既然后续DataSet API会弃用我们就只要掌握DataStream API就可以了,只需要在后续提交任务的时候,提交模式改为BATCH 就可以了。


![[leetcode]刷题--关于位运算的几道题](https://img-blog.csdnimg.cn/3d4f3a11a3a34a75acd00c9287c1a9bc.png)