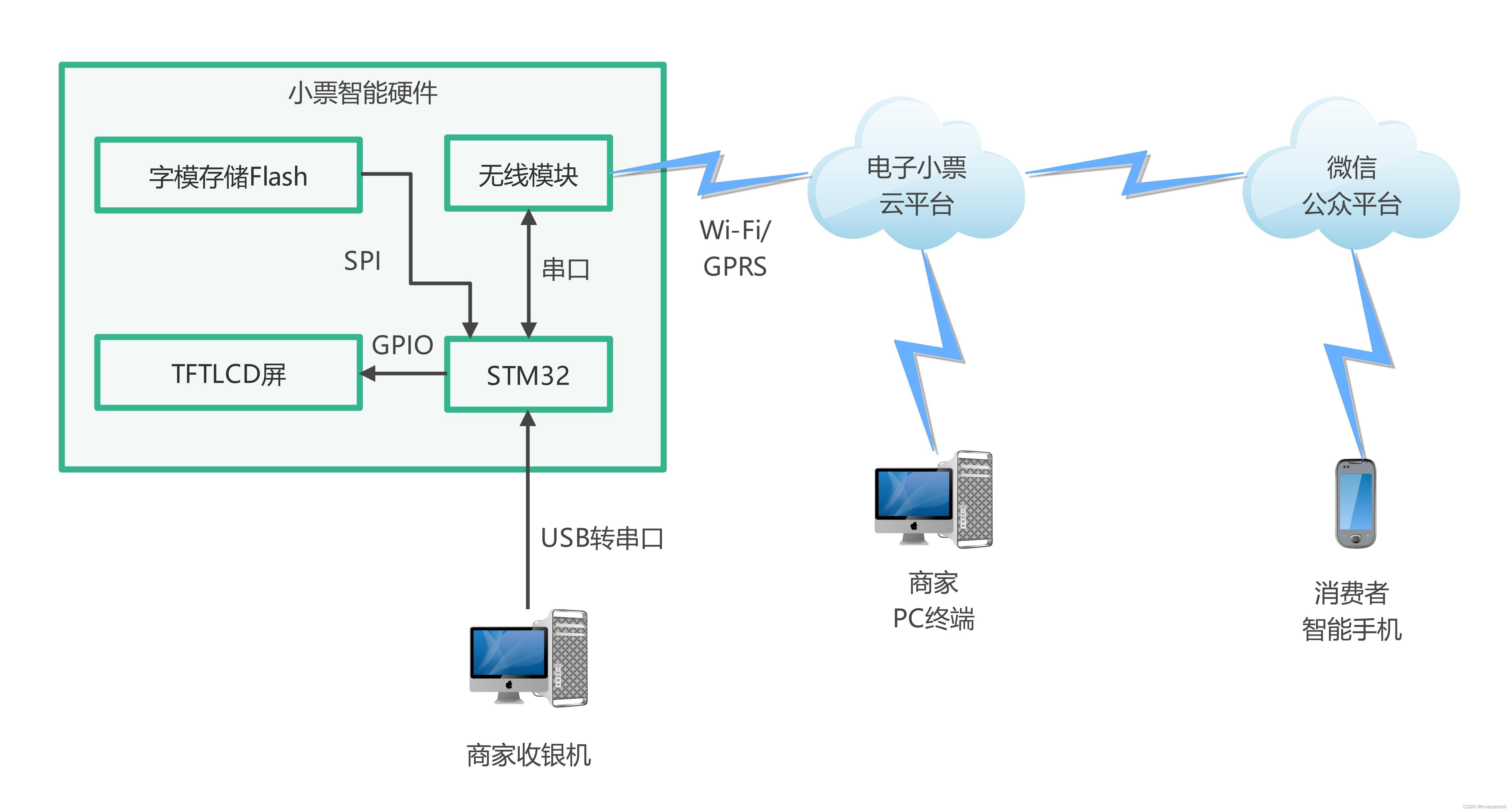
这里要对 unordered_set 与 unordered_map 进行封装,封装时使用的是上一篇中学的 HashBucket 。不仅要完成封装,同时要写入迭代器。
一、HashBucket 的修改
1.1 节点的修改 T
首先来认识一下使用 unordered_set 和 ordered_map 时的区别:
unordered_set 存储唯一的键值。你只需要传入要插入的值。
#include <unordered_set>
#include <iostream>
int main() {
std::unordered_set<int> mySet;
mySet.insert(10);
mySet.insert(20);
for (const auto& elem : mySet) {
std::cout << elem << " ";
}
return 0;
}
unordered_map 存储键值对。你需要传入键和值。
#include <unordered_map>
#include <iostream>
int main() {
std::unordered_map<int, std::string> myMap;
myMap.insert({1, "one"});
myMap.insert({2, "two"});
for (const auto& pair : myMap) {
std::cout << pair.first << ": " << pair.second << " ";
}
return 0;
}
因为 unordered_set 只存储值,而 unordered_map 存储键值对并提供键到值的映射,所以当它们底层使用同一容器进行封装时,要求该容器可以兼容这两种数据类型。
template<class T>//
struct HashNode
{
T _data;//
HashNode* _next;
HashNode(const T& data) :_data(data), _next(nullptr)//
{}
};节点模板的修改是为了满足两者的需要,满足双方的供求。
1.2 类的修改 KeyOfT
因为 unordered_map 传入的是键值对,但是并不知道键值对的键值是什么,所以在定义类模板时,会多传入一个参数 KeyOfT ,作为键值。但肯定有很多人会疑惑,传入的本身就是键值对了, pair<K, V> 中的 K 不就是键值对的键值吗?这么做不是多此一举吗?
事实上,传入 KeyOfT 而不是直接使用键 Key 的主要原因是为了提高代码的灵活性和通用性,尤其是在存储复杂对象时。以下是一个具体的例子来说明这种情况:
示例场景
假设我们有一个存储复杂对象的哈希表,这些对象有多个属性,其中一个属性作为键。
struct Employee
{
int employee_id;
std::string name;
std::string department;
Employee(int id, const std::string& n, const std::string& d)
: employee_id(id), name(n), department(d) {}
};
KeyOfT 提取键的机制
我们需要一种机制来从 Employee 对象中提取 employee_id 作为键。为此,我们定义一个 KeyOfEmployee 函数对象。
struct KeyOfEmployee
{
int operator()(const Employee& emp) const
{
return emp.employee_id;
}
};
键值对
- 键:
employee_id(例如,1) - 值:
Employee对象(例如,Employee(1, "Alice", "HR"))
传入示例
bool Insert(const T& obj)
{
K key = KeyOfT()(obj);
size_t index = Hash()(key) % _bucket.size();
_bucket[index] = new T(obj);
return true;
}
HashBucket<int, Employee, KeyOfEmployee, HashFunc> hb;
hb.Insert(Employee(1, "Alice", "HR"));
hb.Insert(Employee(2, "Bob", "IT"));
由上面的案例就不难看出,传入的对象不一定是键值对,有可能是自定义的类对象,此时就只需要添加 KeyOfT 的模板,就可以在类内部找到键值。
类模板添加KeyOfT
template<class K, class T, class KeyOfT, class Hash = Hashfunc<K>>
class HashBucket
{
private:
vector<Node*> _bucket;
size_t _n;
};于 unordered_set 来说,KeyOfT 的方式有些多此一举。unordered_set 本质上是一个存储唯一元素的集合,没有键值对的概念。所以这里的修改是为了将就 unordered_map 。
//unordered_set
template<class K>
class unordered_set
{
struct SetKeyOfT
{
const K& operator()(const K& Key)
{
return Key;
}
};
public:
private:
HashBucket<K, K, SetKeyOfT> _ht;//注意传参要对应HashBucket
};
//unordered_map
template<class K, class V>
class unordered_map
{
struct MapKeyOfT
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
public:
private:
HashBucket<K, pair<K, V>, MapKeyOfT> _ht;//注意传参要对应HashBucket
};1.3 类的修改 HashFunc
下面先来看一下这三个类与其对应的类模板:
template<class K>
class unordered_set
{
private:
HashBucket<K, K, SetKeyOfT> _ht;
};
template<class K, class V>
class unordered_map
{
private:
HashBucket<K, pair<K, V>, MapKeyOfT> _ht;
};
template<class K, class T, class KeyOfT, class Hash = HashFunc<K>>
class HashBucket
{};在使用时,用户是直接使用 unordered_set 与 unordered_map ,所以应该希望在 unordered_set 与 unordered_map 层有一个默认的 HashFunc ,这样用户不仅可以自定义,也可以使用默认的 HashFunc ,提高了代码的灵活性,而在 HashBucket 层,只需要按照上层的指令来即可,所以就需要把默认的 HashFunc 提前到上层。
template<class K, class Hash = HashFunc<K>>
class unordered_set
{
private:
HashBucket<K, K, SetKeyOfT, Hash> _ht;
};
template<class K, class V, class Hash = HashFunc<K>>
class unordered_map
{
private:
HashBucket<K, pair<K, V>, MapKeyOfT, Hash> _ht;
};
template<class K, class T, class KeyOfT, class Hash>
class HashBucket;
{};二、迭代器
2.1 定义迭代器成员
首先,迭代器要知道自己的位置,这就需要定义一个节点指针,另外,当在哈希桶中使用自增直到遍历完 vector 的某一节点时,因为迭代器另一个单独的类,所以需要让迭代器直到自己所处的哈希桶的结构,才好寻找下一个存在值的节点,这就需要定义一个哈希桶的指针。
这样不仅得到了迭代器的成员,也得到了迭代器的构造函数。
template<class K, class T, class KeyOfT, class Hash>
struct __HtIterator
{
typedef HashNode<T> Node;
Node* _node;
HashBucket<K, T, KeyOfT, Hash>* _pht;
__HtIterator(Node* node, HashBucket<K, T, KeyOfT, Hash>* pht)
:_node(node), _pht(pht)
{}
};问题1:
因为迭代器中存在了哈希桶的指针来指向哈希桶,那么当遍历哈希桶的数组时,不可避免地会使用到哈希桶的 _bucket ,但是这又是个私有成员,如何解决呢?
可以使用友元来帮助解决(省略不必要的部分):
template<class K, class T, class KeyOfT, class Hash>
class HashBucket
{
public:
template<class K, class T, class KeyOfT, class Hash>
friend struct __HtIterator;//友元
};问题2:
在迭代器中,存在了哈希桶;在哈希桶中,又用到了迭代器。那么又有一个问题,编译器访问某一个的时候,必然会访问不到另一个,这是代码顺序的问题,这个问题怎么解决呢?和函数声明类似,可以在迭代器前加上哈希桶的类声明:
template<class K, class T, class KeyOfT, class Hash>//类声明
class HashBucket;
template<class K, class T, class KeyOfT, class Hash>
struct __HtIterator
{};2.2 begin 与 end 函数
2.2.1 begin 函数
如下图, begin 返回的是哈希桶第一个存值的迭代器,所以只需要挨个遍历即可,但是返回节点的地址容易,那么哈希桶的地址怎么办呢?这可是在哈希桶类中返回自己的地址,应该怎么办?
return iterator(cur, this);其实答案很久之前就已经学过了,this指针代表的不就是本身吗?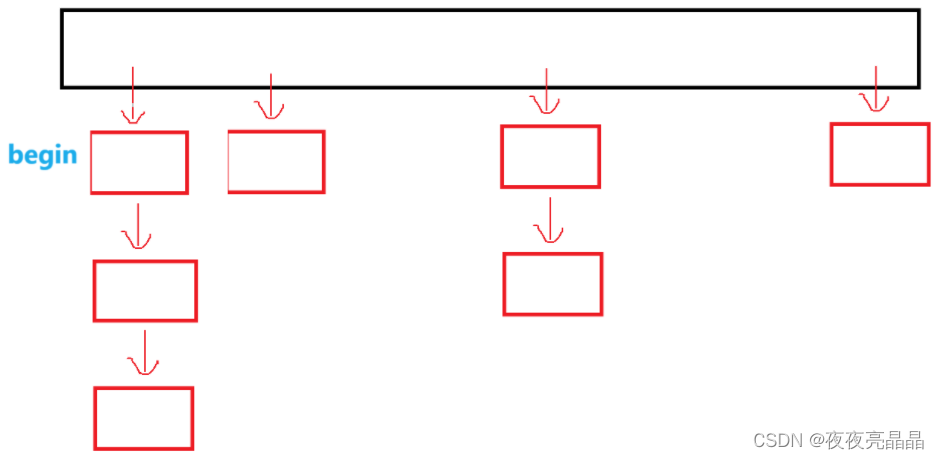
若没有找到,可以直接返回 end ,下面只需要对 end 继续做优化即可。
template<class K, class T, class KeyOfT, class Hash>
class HashBucket
{
typedef HashNode<T> Node;
public:
typedef __HtIterator<K, T, KeyOfT, Hash> iterator;
iterator begin()
{
for (size_t i = 0; i < _bucket.size(); i++)
{
Node* cur = _bucket[i];
if (cur)
{
return iterator(cur, this);
}
}
return end();
}
private:
vector<Node*> _bucket;
size_t _n;
};2.2.2 end 函数
end 返回的是最后一个存值的节点的下一个位置,所以直接可以使用空指针来构造:
iterator end()
{
return iterator(nullptr, this);
}2.3 operator重载
2.3.1 自增的重载
这里有两种情况:
1.当前桶还为遍历完,那么迭代器可以直接指向当前节点的下一个。
2.当前桶已经遍历完,那么就需要遍历整个 vector ,直到找到下一个不为空的桶。
template<class K, class T, class KeyOfT, class Hash>
struct __HtIterator
{
typedef HashNode<T> Node;
typedef __HtIterator<K, T, KeyOfT, Hash> Self;
Node* _node;
HashBucket<K, T, KeyOfT, Hash>* _pht;
__HtIterator(Node* node, HashBucket<K, T, KeyOfT, Hash>* pht)
:_node(node), _pht(pht)
{}
Self& operator++()
{
if (_node->_next)
{
//当前桶未遍历完,取桶的下一个节点
_node = _node->_next;
}
else
{
//当前桶已遍历完,找下一个不为空的桶
KeyOfT kot;
Hash hs;
size_t i = hs(kot(_node->_data)) % _pht->_bucket.size();
++i;
for (; i < _pht->_bucket.size(); i++)
{
if (_pht->_bucket[i])
break;
}
if (i == _pht->_bucket.size()) _node = nullptr;//没找到下一个不为空的桶
else _node = _pht->_bucket[i];//找到了下一个不为空的桶
}
return *this;
}
};2.3.2 解引用和不等于的重载
这两个比较简单,就直接放在一起上代码了:
T& operator*()
{
return _node->_data;
}
bool operator!=(const Self& s)
{
return _node != s._node;
}2.4 完整代码
下面就可以来测试一下迭代器了,测试之前先看一下完整的代码:
2.4.1 完整的迭代器
template<class K, class T, class KeyOfT, class Hash>//
class HashBucket;
template<class K, class T, class KeyOfT, class Hash>
struct __HtIterator
{
typedef HashNode<T> Node;
typedef __HtIterator<K, T, KeyOfT, Hash> Self;
Node* _node;
HashBucket<K, T, KeyOfT, Hash>* _pht;
__HtIterator(Node* node, HashBucket<K, T, KeyOfT, Hash>* pht)
:_node(node), _pht(pht)
{}
Self& operator++()
{
if (_node->_next)
{
//当前桶未遍历完,取桶的下一个节点
_node = _node->_next;
}
else
{
//当前桶已遍历完,找下一个不为空的桶
KeyOfT kot;
Hash hs;
size_t i = hs(kot(_node->_data)) % _pht->_bucket.size();
++i;
for (; i < _pht->_bucket.size(); i++)
{
if (_pht->_bucket[i])
break;
}
if (i == _pht->_bucket.size()) _node = nullptr;//没找到下一个不为空的桶
else _node = _pht->_bucket[i];//找到了下一个不为空的桶
}
return *this;
}
T& operator*()
{
return _node->_data;
}
bool operator!=(const Self& s)
{
return _node != s._node;
}
};
2.4.2 完整的HashBucket
template<class K, class T, class KeyOfT, class Hash>//
class HashBucket
{
typedef HashNode<T> Node;//
public:
template<class K, class T, class KeyOfT, class Hash>
friend struct __HtIterator;
typedef __HtIterator<K, T, KeyOfT, Hash> iterator;
iterator begin()
{
for (size_t i = 0; i < _bucket.size(); i++)
{
Node* cur = _bucket[i];
if (cur)
{
return iterator(cur, this);
}
}
return end();
}
iterator end()
{
return iterator(nullptr, this);
}
HashBucket()
{
_bucket.resize(10, nullptr);
_n = 0;
}
~HashBucket()
{
for (size_t i = 0; i < _bucket.size(); i++)
{
Node* cur = _bucket[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_bucket[i] = nullptr;
}
}
bool Insert(const T& data)
{
KeyOfT kot;
if (Find(kot(data))) return false;//Find(kv.first)->Find(kot(data))
Hash hs;
if (_n == _bucket.size())
{
vector<Node*> newBucket(_bucket.size() * 2, nullptr);
for (size_t i = 0; i < _bucket.size(); i++)
{
Node* cur = _bucket[i];
while (cur)
{
Node* next = cur->_next;
size_t index = hs(kot(cur->_data)) % newBucket.size();//
cur->_next = newBucket[index];
newBucket[index] = cur;
cur = next;
}
_bucket[i] = nullptr;
}
_bucket.swap(newBucket);
}
size_t index = hs(kot(data)) % _bucket.size();
Node* newnode = new Node(data);
newnode->_next = _bucket[index];
_bucket[index] = newnode;
++_n;
return true;
}
bool Erase(const K& Key)
{
KeyOfT kot;
Hash hs;
size_t index = hs(kot(Key)) % _bucket.size();
Node* cur = _bucket[index];
Node* prev = nullptr;
while (cur)
{
if (kot(cur->_data) == Key)
{
//删除的是第一个节点
if (prev == nullptr)
{
_bucket[index] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
delete cur;
return true;
}
else
{
prev = cur;
cur = cur->_next;
}
}
return false;
}
Node* Find(const K& Key)
{
KeyOfT kot;
if (_bucket.empty()) return nullptr;
Hash hs;
size_t index = hs(Key) % _bucket.size();
Node* cur = _bucket[index];
while (cur)
{
if (kot(cur->_data) == Key)/**/
return cur;
else cur = cur->_next;
}
return nullptr;
}
private:
vector<Node*> _bucket;
size_t _n;
};
三、迭代器的测试
3.1 重命名
迭代器的测试其实就是在 unordered_set 与 ordered_map 中复用 HashBucket 的函数,在两个类中对迭代器进行重命名,注意一定不要错了!
//unordered_set中
typedef typename HashBucket<K, K, SetKeyOfT, Hash>::iterator iterator;
//unordered_map中
typedef typename HashBucket<K, pair<K, V>, MapKeyOfT, Hash>::iterator iterator;此外,说明一下 typename 在这里的作用:明确指出某个标识符是一个类型,从而避免编译器将其解释为非类型名称。而且,迭代器的重命名要定义在 public 域中。
3.2 unordered_set
template<class K, class Hash = HashFunc<K>>
class unordered_set
{
struct SetKeyOfT
{
const K& operator()(const K& Key)
{
return Key;
}
};
public:
typedef typename HashBucket<K, K, SetKeyOfT, Hash>::iterator iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
bool insert(const K& Key)
{
return _ht.Insert(Key);
}
private:
HashBucket<K, K, SetKeyOfT, Hash> _ht;
};
void Test_unordered_set()
{
unordered_set<int> s;
s.insert(31);
s.insert(23);
s.insert(19);
s.insert(6);
s.insert(22);
s.insert(37);
for (auto e : s)
{
cout << e << endl;
}
}3.3 unordered_map
template<class K, class V, class Hash = HashFunc<K>>
class unordered_map
{
struct MapKeyOfT
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
public:
typedef typename HashBucket<K, pair<K, V>, MapKeyOfT, Hash>::iterator iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
bool insert(const pair<K, V>& kv)
{
return _ht.Insert(kv);
}
private:
HashBucket<K, pair<K, V>, MapKeyOfT, Hash> _ht;
};
void Test_unordered_map()
{
unordered_map<int, int> m;
m.insert(make_pair(31, 31));
m.insert(make_pair(23, 23));
m.insert(make_pair(19, 19));
m.insert(make_pair(6, 6));
m.insert(make_pair(22, 22));
m.insert(make_pair(37, 37));
for (auto e : m)
{
cout << e.first << ":" << e.second << endl;
}
cout << endl;
}在 main 函数中进行测试时,可以看到两者都可以跑起来: