文章目录
- 1_概述
- 2_算法基本步骤
- 3_过程优化
- 4_优势以及局限
- 5_模拟实现
- 6_总结
1_概述
Frame of Reference(FoR)压缩算法 是一种用于压缩数值数据的算法,特别是在处理大规模数据集时,利用数据的局部性和重复性来减少存储和传输的开销。
该算法通常应用于数据库、数据压缩、信号处理、以及大数据分析等领域。
Frame of Reference压缩算法 的核心思想是,通过将数据的最小值作为参考点,将所有数据与这个参考点进行偏移,然后存储相对值(即“偏移量”)。
这样可以有效地减少需要存储的数字位数,尤其是在数据的范围比较小且有较多重复值时,能够显著提高压缩率。
2_算法基本步骤
可以分为如下四个步骤:
选择参考值:从数据集中的所有值中选择一个最小值(或称为“参考点”),这个值作为参照,用于后续的压缩过程。
计算偏移量:对数据集中的每个数值,计算它与参考值的差(即偏移量)。如果数据集中的数值接近参考值,那么它们的偏移量会较小,所需的存储空间也会较少。
存储偏移量:将所有的偏移量存储下来,而不直接存储原始数据。由于偏移量通常较小,可以使用较少的比特数进行编码,从而达到压缩的效果。
解压缩:解压时,使用存储的参考值将偏移量还原为原始数值。
举个例子——假设我们有一个数值数据集:
[10, 12, 14, 11, 13, 10, 10]
选择数据中的最小值 10 作为参考值,计算偏移量:
10 -> 10 - 10 = 012 -> 12 - 10 = 214 -> 14 - 10 = 411 -> 11 - 10 = 113 -> 13 - 10 = 310 -> 10 - 10 = 010 -> 10 - 10 = 0
得到的结果是偏移量数组:
[0, 2, 4, 1, 3, 0, 0]
由于偏移量范围较小(0到4),我们可以用较少的比特数来存储这些值。例如,我们可以使用3位二进制数来表示每个偏移量。这样,存储的空间将比存储原始数据(每个数值可能需要至少4个字节)要小。
解压时,我们将偏移量恢复到原始值,再加上参考值 10,得到原始数据集。
3_过程优化
经过上面的分析我们已经了解到了算法的整个逻辑,但是这里还不是极限,我们还可以进一步优化。
优化一
以数组中的最小值作为参考得到的差值并不是最小的,反而是最大的。所以我们希望得到更小的差值以减少存储差值的内存大小。
怎么做呢?
我们让数组中所有存储的元素变得有序(需要看使用场景),存储第一个元素的值,且每一个元素选取上一个元素作为参照存储差值,然后再根据差值数组中最大值的bit位选择合适的存储类型。
过程如下
[10, 12, 14, 11, 13, 10, 10] -> [10, 10, 10, 11, 12, 13, 14] -> 10 [0, 0, 1, 1, 1, 1]
这里示例减少的空间可能不是很明显,但是如果在初始值特别大且数据特别密集的情况下优化会很明显(比如第一个数 65535,差值一直为 1:用 int 表示初始值,byte 数组存储差值)。
优化二
如果经过优化一的过程之后存在一个数组的差值和其他元素相比差距过大,显得十分突兀,导致差值数组不能选择更小更合适的存储类型,影响编码效率该怎么办呢?如下情况:
[10, 12, 14, 650, 651, 652] -> 10 [2, 636, 1, 1, 1]
我们可以对数组进行拆分,将其拆分成多份存储,每块单独使用自己的基准值和差值集合,如下:
10 [2, 2] 650 [1, 1]
经过如上优化可以有效的将其压缩到合适的大小。
另外:由于还需要解压,所以别忘了使用一定空间指出每个数组占用的空间大小。
4_优势以及局限
优势:
-
空间效率:如果数据集中有很多相同的数值或者数值差异较小,FoR压缩能够显著减少存储需求。
-
简单高效:该算法的实现相对简单,适用于某些类型的连续数值数据。
局限性:
-
对数据的分布有依赖:当数据差异较大或分布不均匀时,FoR压缩可能效果不佳,因为参考值的选取并不能有效压缩整个数据集。
-
适用场景限制:这种算法通常适用于数值类型较为接近且重复性较高的数据,若数据值较为分散或随机,FoR压缩的效果就不如其他复杂的压缩算法(如Huffman编码、LZ77等)。
较为稀疏的数组就不适合选用此算法,可能需要其他的算法(如 Roaring Bitmaps 算法):
[1000W, 2000W, 3003W, 5248W, 9548W]
5_模拟实现
Java模拟实现
import java.util.*;
public class FrameOfReferenceCompressor {
static class Block {
int base; // 当前块的起始基准值
List<Integer> deltas; // 差值集合
Block(int base) {
this.base = base;
this.deltas = new ArrayList<>();
}
public String toString() {
return base + " " + deltas.toString();
}
}
/**
* 压缩主方法
*/
public static List<Block> compress(int[] input, int maxDeltaThreshold) {
List<Block> blocks = new ArrayList<>();
if (input == null || input.length == 0) return blocks;
Block currentBlock = new Block(input[0]);
blocks.add(currentBlock);
int prev = input[0];
for (int i = 1; i < input.length; i++) {
int delta = input[i] - prev;
if (delta > maxDeltaThreshold) {
// 如果当前差值过大,新建一个块
currentBlock = new Block(input[i]);
blocks.add(currentBlock);
prev = input[i];
} else {
currentBlock.deltas.add(delta);
prev = input[i];
}
}
return blocks;
}
/**
* 解压缩方法
*/
public static List<Integer> decompress(List<Block> blocks) {
List<Integer> result = new ArrayList<>();
for (Block block : blocks) {
int base = block.base;
result.add(base);
for (int delta : block.deltas) {
base += delta;
result.add(base);
}
}
return result;
}
public static void main(String[] args) {
// 有序数组
int[] input = {10, 12, 14, 650, 651, 652, 900, 1000, 1010};
// 设置一个差值阈值,超过则拆块(比如这里设置为100)
List<Block> compressed = compress(input, 100);
System.out.println("🔒 压缩结果:");
for (Block block : compressed) {
System.out.println(block);
}
System.out.println("\n🔓 解压后恢复:");
List<Integer> decompressed = decompress(compressed);
System.out.println(decompressed);
}
}
可以看到这里使用的是有序数组,至于应用场景,也就是我写这篇博客的初衷了,ES存储倒排索引时可能会使用 Frame Of Reference 压缩算法,倒排表中 term 对应的就是 id 有序数组,总体过程如下(跟我们模拟的差不多):
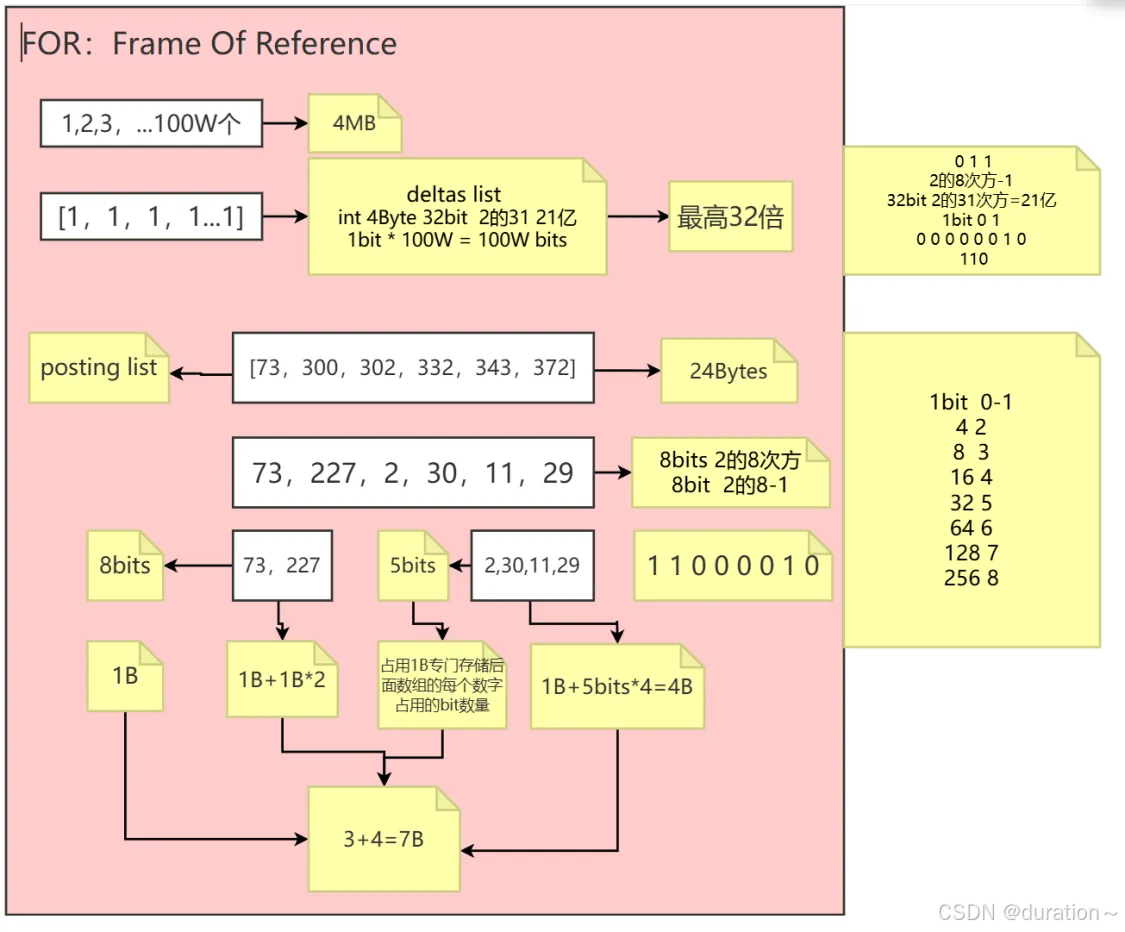
6_总结
应用场景:
-
数据库压缩:对于表中数值类型的数据,FoR压缩可以减少存储空间,尤其是在数值差异不大的情况下(ES)。
-
图像和视频压缩:在一些图像和视频压缩算法中,FoR也可用于对某些图像区域的亮度或色彩信息进行压缩。
-
科学计算与模拟:在模拟计算中,FoR可以减少大规模数据集的存储需求,尤其是在需要存储数值型模拟结果时。
总结来说,Frame of Reference压缩算法 是一种通过引用最小值来减少数据存储需求的技术,适用于有一定规律性或重复性的数值数据。
虽然它的应用场景有限,但在特定情况下,它能够大幅提高压缩效率。



![[ctfshow web入门] web2](https://i-blog.csdnimg.cn/direct/9f307c14635545d780c4ca10ba357a2d.png)