一、主从集群
1.主从集群

主从集群读写分离,主能读能写,从只能读,读的数据是同步主的
docker搭建:
docker-compose
这里设置网络模式为model,就直接暴露在了宿主机中,就不用映射端口了
不改就是默认的桥接模式
建立主从关系:
进入从redis:
![]()
输入命令:
![]()
2.主从同步原理

①怎么判断第一次同步
建立主从关系后每个主从replicationID变成一样

②如何把所有数据发送
主会先将自己的数据持久化存入RDB文件中,然后直接把文件给从,从删除自己原有数据,再加载这个文件中的数据

③主怎么知道从缺少什么数据
首先建立主从关系后就会有一个repl_backlog缓存区来记录从一开始的命令,并有一个值offset来记录执行命令条数。只要是断开重连的还会携带offset,与repl_backlog中进行比较,然后就会把差的命令传给从。

④主从集群优化
repl_backlog是一个环形数组,写满后会覆盖原先的数据
因为宕机重连的时间不会很长,就算一直往主中写数据,从也会不断赶着去写,只要主停下来就会追上

但是如果宕机时间太长,长到未同步的数据也被覆盖了就会数据不同步,只能全量同步
所以判断是否第一次来时还会判断是否被覆盖
![]()

优化方案:
前两个是对全量同步的优化

3.哨兵原理
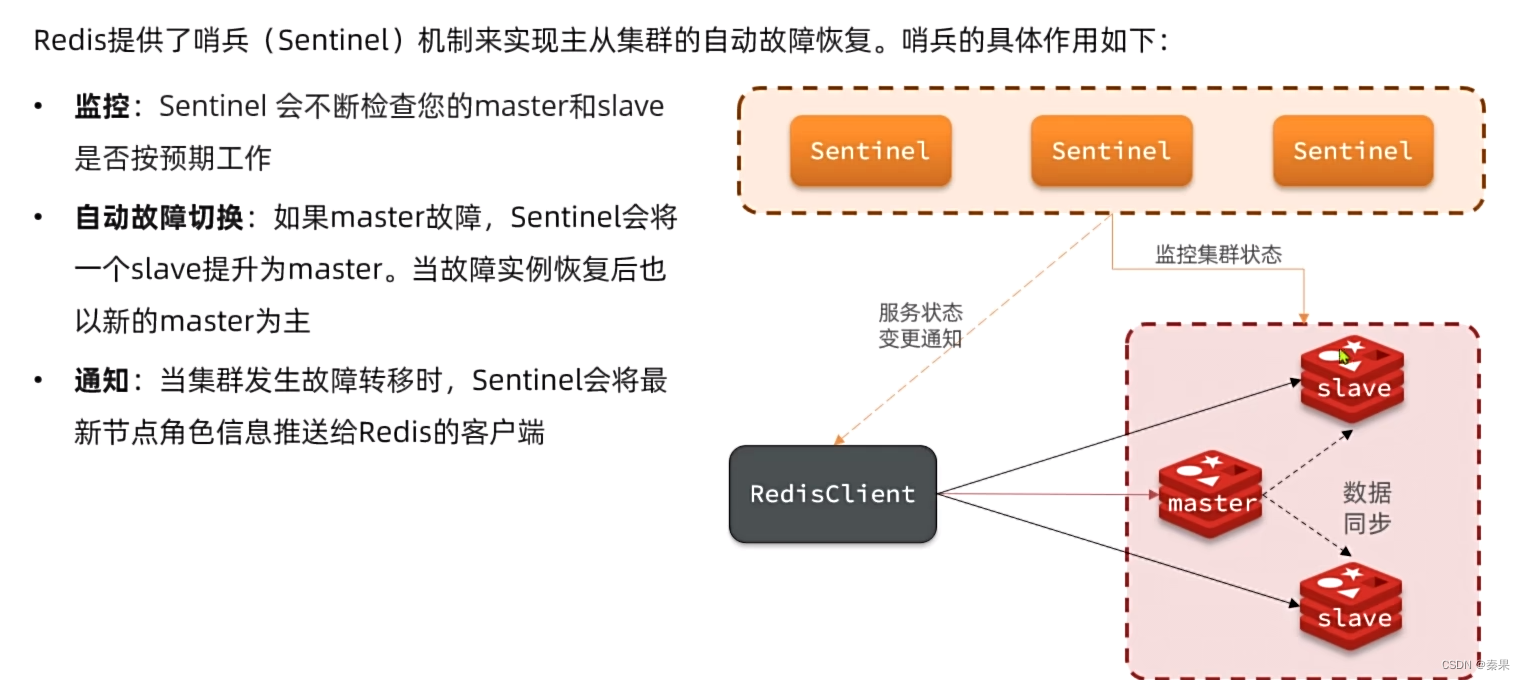
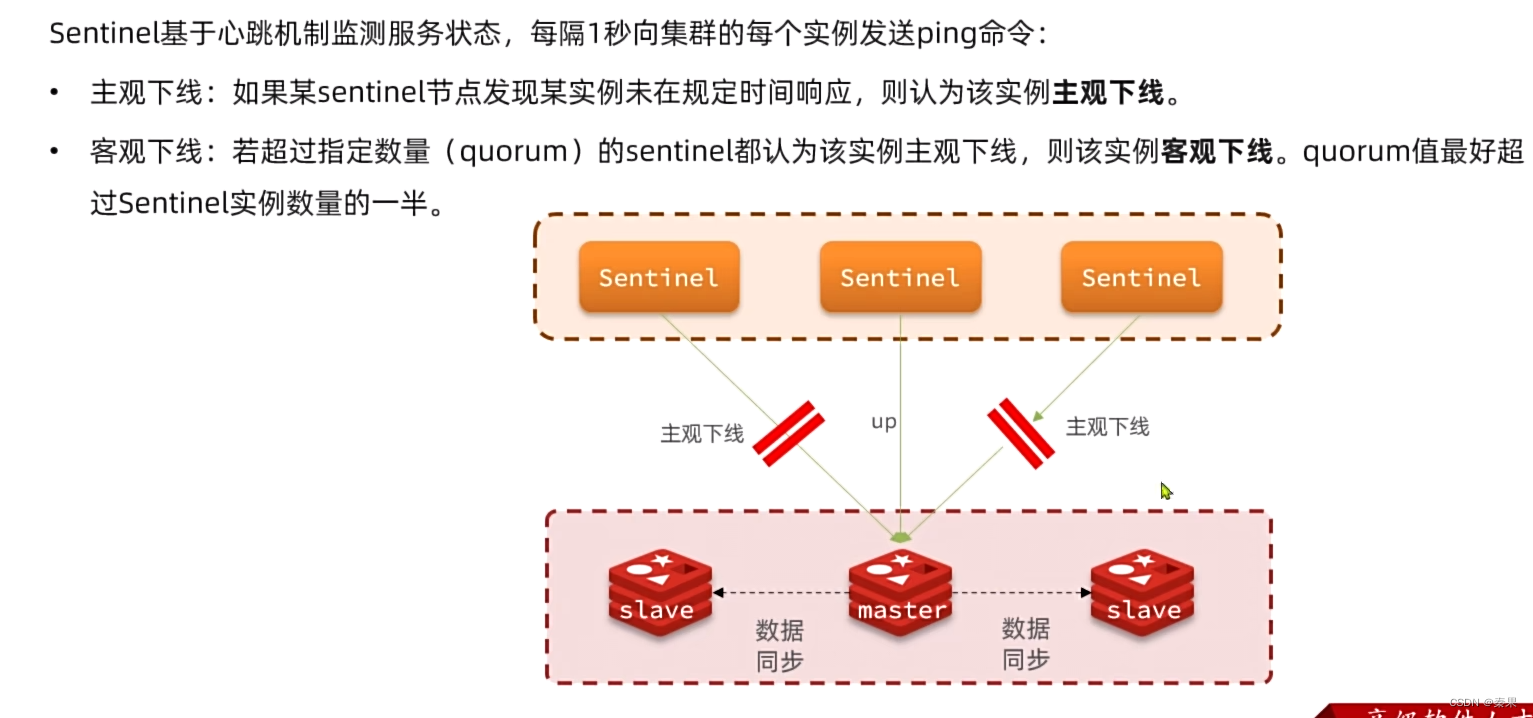
①怎么发现服务故障
②怎么选取新的slave为master
slave-piority是默认的为1不配置的话
运行id大小是随机的,就是随机挑
最重要的就是:offset

③如何实现故障转移
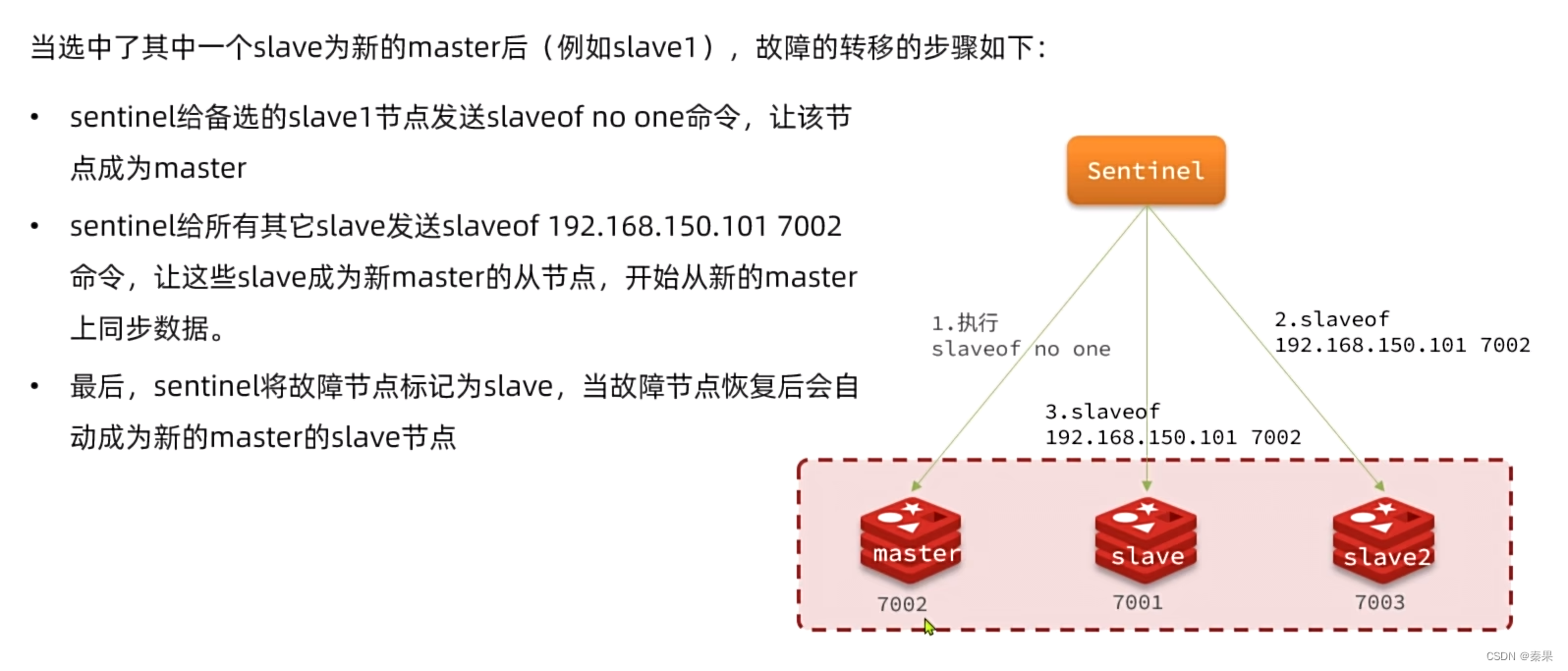
4.搭建哨兵集群
哨兵配置:

第一个是哨兵的ip,第二个是监控的集群名字,主从集群的master节点端口,以及超过多少数量哨兵算客观下线,第三个是多久不连接判断是下线,第四个是多久进行一次故障恢复,只要失败就过多久再故障恢复
搭建步骤:
day10-Redis面试篇 - 飞书云文档 (feishu.cn)
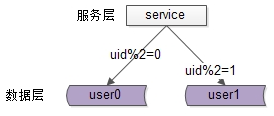
二、Redis分片
主从和哨兵是备份的,所以它的容量上限是单节点的。而且不能设置的太高,太高主从同步,数据持久化的效率都会非常低,一般不超过8g
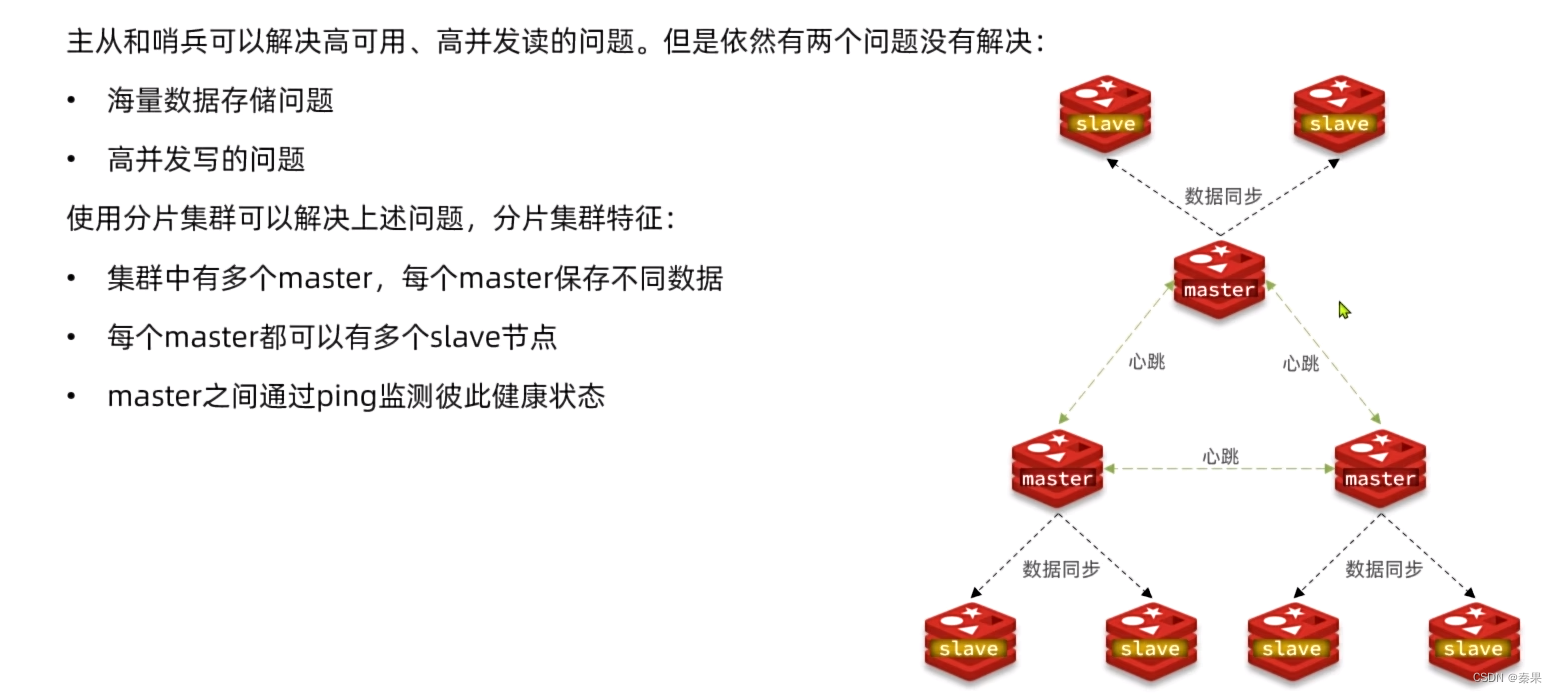
分片集群,就是不同主从集群保存了不同的数据,且主节点互相监控健康状态,如果宕机会让宕机的集群中从节点变成主节点。
缺点:集群结构很复杂,成本很高,只有在大型企业中有应用。
1.分片集群搭建
①以cluster模式运行redis

可以在compose文件中直接部署。
②建立分片集群连接

2.散列插槽
就是怎么分配数据


三、Redis数据结构
1.RedisObject

lru和refcount是判断是否回收的依据
编码方式眼熟即可:


2.SkipList
链表查询效率低,因为查询跨度是1,只能从一个一个去查
允许32级指针
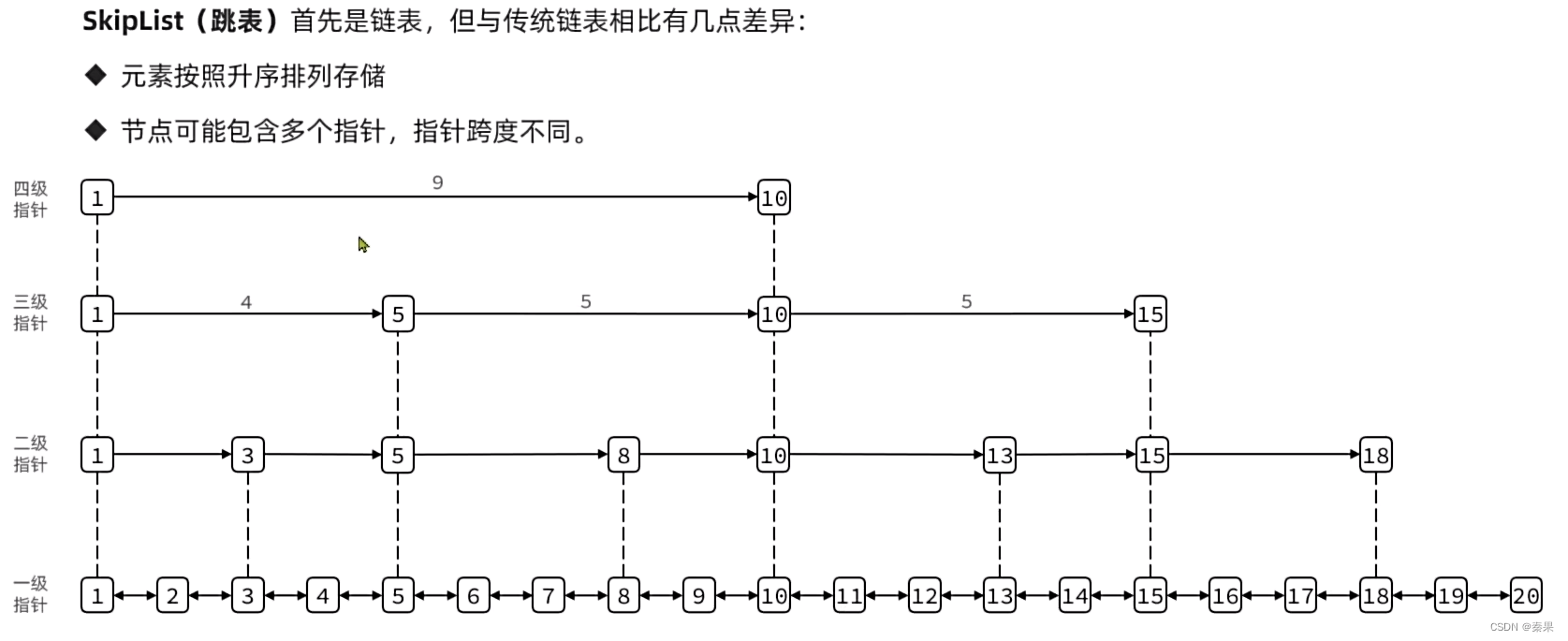
通过跳着和后面节点建立连接,当需要查询后面的节点时就可以跳着向后面进行查询,空间换时间

3.SortedSet
就是ZSet
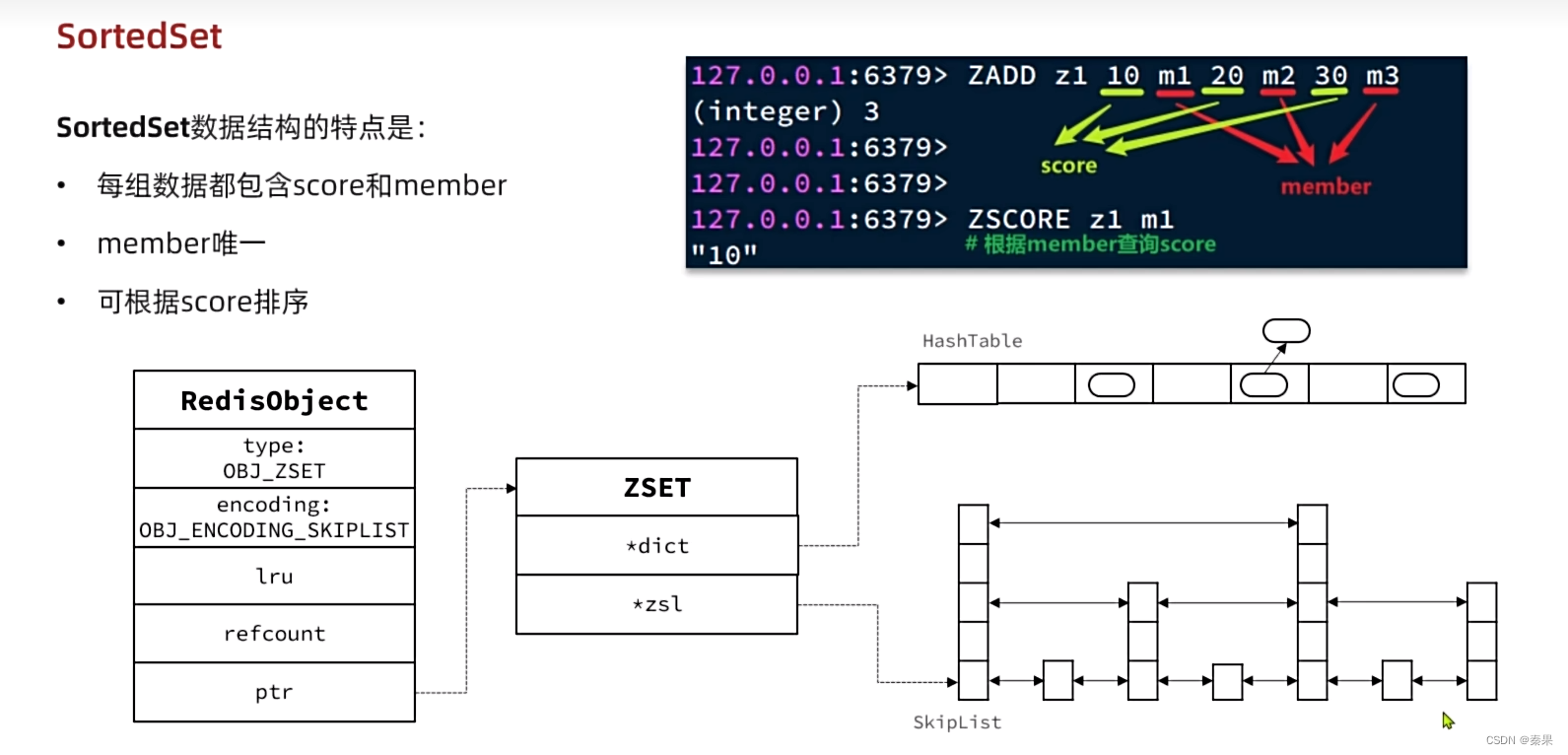
就是首先会使用哈希表进行数据的存储,放入member再用链表将每一个member连起来。
其次还会使用跳表,根据score将数据进行排序,每个节点包含了score和member
当我想知道一个member的排名时就会先从哈希表中拿到它的score,然后再去跳表中,查询到score对应的排序。

四、Redis回收处理
1.过期KEY处理
可以给Key设置过期时间

①如何知道键过期

②过期处理

2.内存淘汰策略
之前说到,一个数据RedisObject包含了lru:最后访问时间,可以根据它们对过期KEY回收。这是其中淘汰策略会用到的数据

基本使用LRU或者LFU中进行选择。但是LRU可能就重要的没有不重要的被访问最近,所以最优是LFU。
底层怎么知道最后访问时间和访问频率就是redisObject中的一个lru字段。

逻辑访问次数是:只有频率足够大的时候才会加一。往上加很难,还会随时间衰减。
五、缓存问题
1.缓存一致性

这里对缓存数据设置了TTL就可以有兜底方案,如果更新数据库缓存失败,也会在一个时间段后去更新缓存。
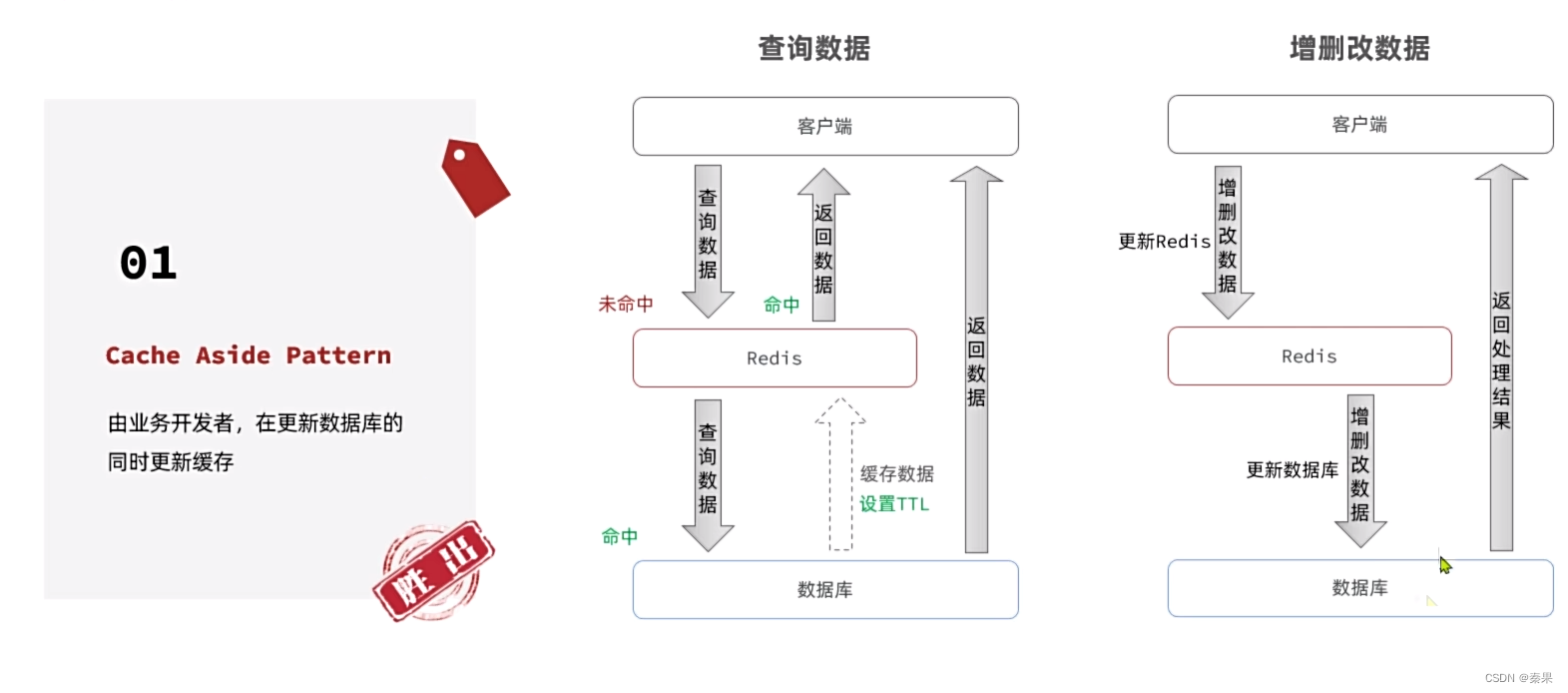
- 这里有些增可以不同步,当别人查的时候再去更新缓存。例如当我添加菜品分类时,可以不添加相应缓存,但是添加菜品的一个信息还是需要更新缓存。
- 然后删可以直接删除。
- 改的话也删除,当查了就会进行缓存。
如果增删改先操作redis后操作数据库,并发情况下会造成数据不一致的问题:
如果一个查一个改线程同时来,改了redis还没来得及改数据库,查的发现redis没了去查数据库。查比改数据库快,就会返回旧数据库的数据。数据不一致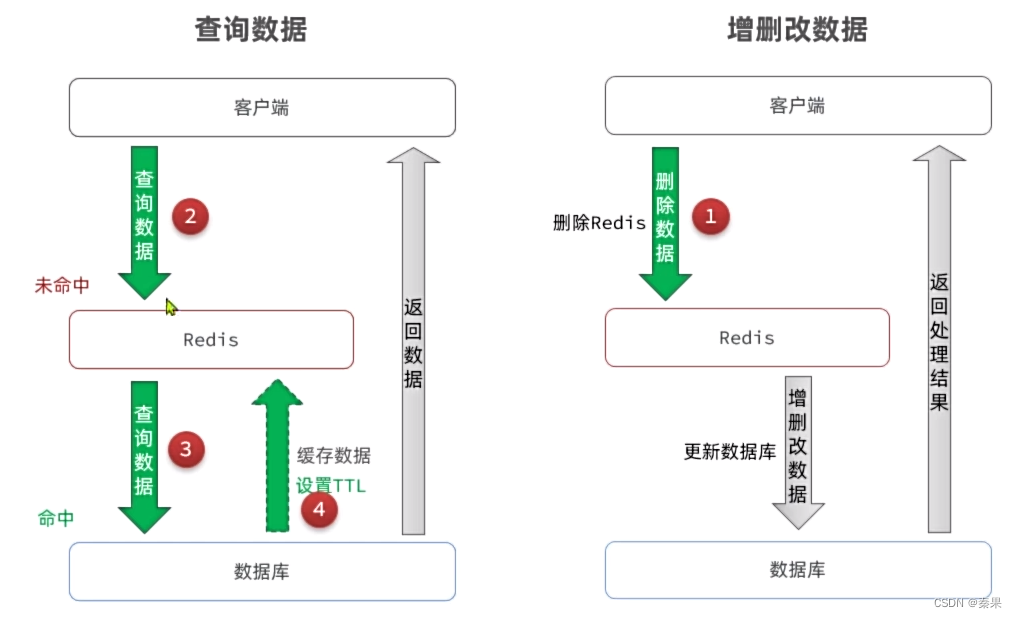
所以得先操作数据库,再操作redis:
但是在极端情况下也会出现不一致:
查发现Redis中数据刚好过期,去读数据库并缓存redis之前发生了另一个线程去更新数据库,删除redis的操作。这两个操作后再去缓存数据,缓存的是旧数据。
条件很苛刻

2.缓存穿透

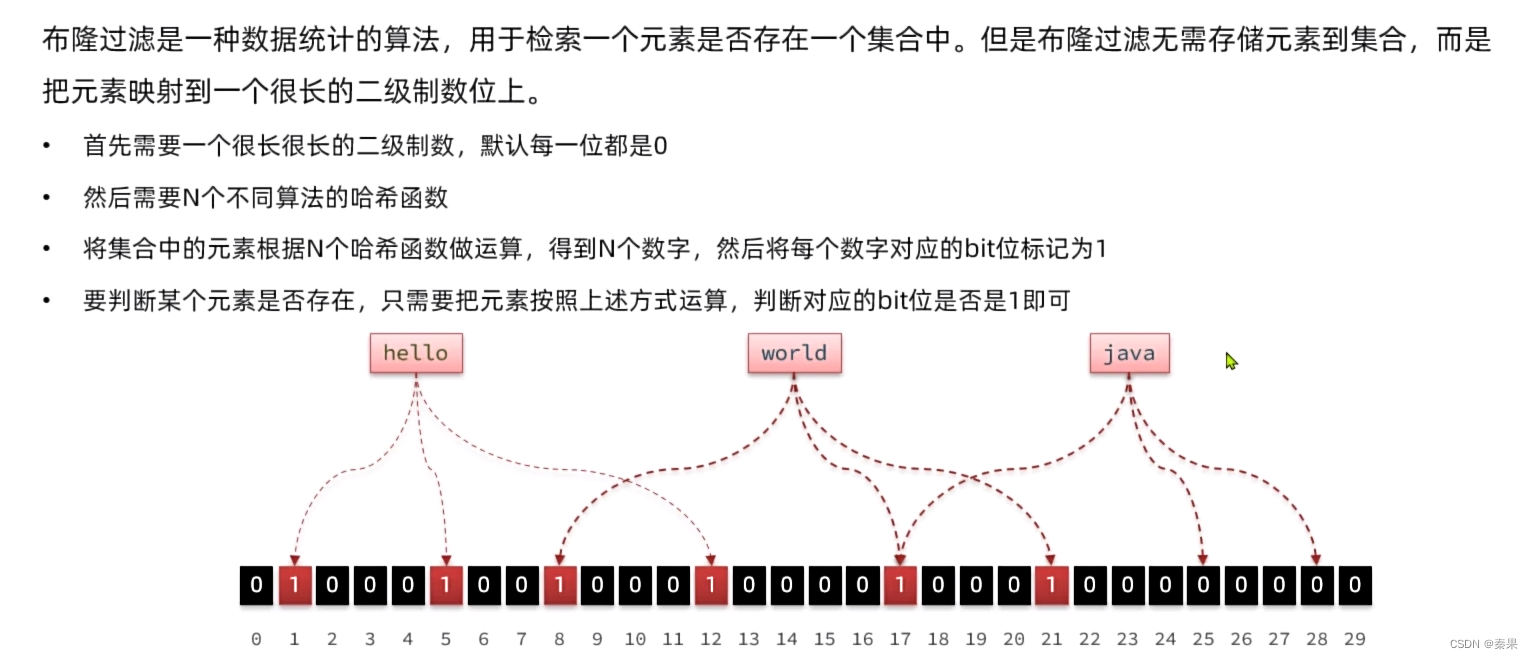
布隆过滤器的作用方式就是将存入redis中的所有key利用哈希函数做运算在一个很长的二进制数上做标记,这样就可以在空间占用率很低的情况下判断key是否存在。
3.缓存雪崩
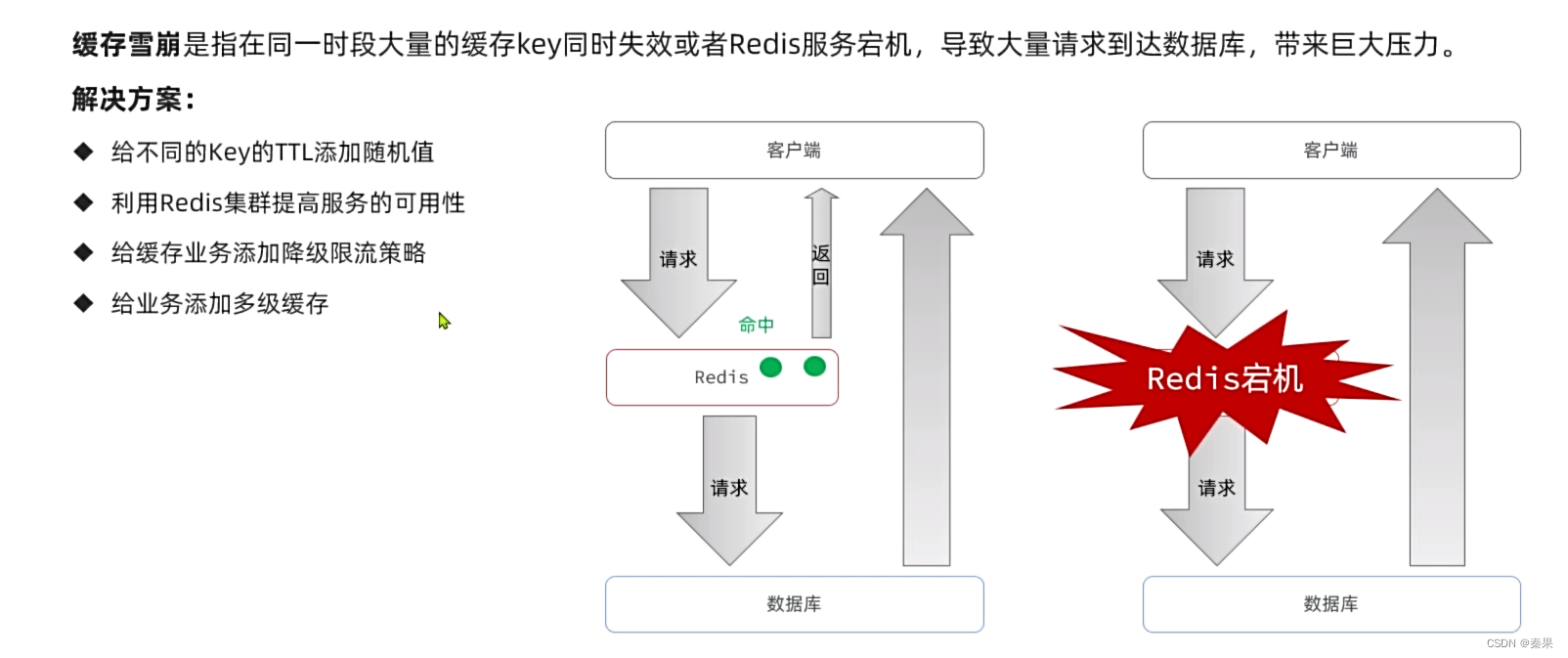
避免同一时段大量缓存key同时失效采用失效值为随机
避免宕机采用集群的方式
兜底方案:
(1)有redis宕机后,对查询的业务限流或者直接熔断不让访问
(2)添加多级缓存:
浏览器本地缓存,缓存静态资源
nginx建立缓存,缓存更新麻烦,缓存都是一致性低,更新频率低的缓存
可以jvm进行本地缓存
再考虑缓存redis
4.缓存击穿

互斥锁就是当一个线程发现失效后就会拿到锁去进行重建,其他线程访问到时拿不到锁就一直等待查看是否命中。
逻辑过期就是不设置TTL,数据中多一个过期时间的字段。在程序中实现,发现如果这个字段已经过期,拿到锁就开启一个线程去重建,自己就返回旧数据。其他线程在还没重建完前发现拿不到锁就也返回旧数据结束。