一,项目描述
该项目将使用卷积神经网络算法,识别图片中的动物是猫还是狗
数据集地址:https://momodel.cn/explore/5efc77dbc018c95e69fb2a81?type=dataset
其中,训练用的图片数据集在 dogs_cats/data 文件夹下,整个数据集分为训练集和测试集,其中训练集在 dogs_cats/data/train 文件夹内,有 25000 张图片,猫狗各 12500 张。 而测试集在dogs_cats/data/test 文件夹内有 12500 张,没有标明是猫还是狗
部分数据展示如下:

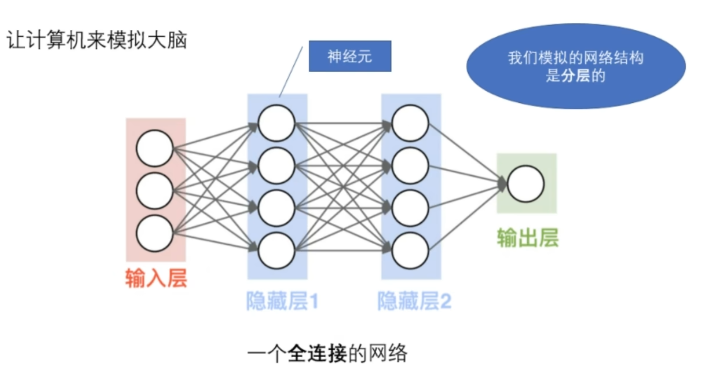
二,神经网络
(1)神经网络结构
可以通过下图进行理解神经网络的基本构成:

(2)图片在计算机内的储存
图片在计算机储存由像素点矩阵组成,黑白图片的像素点是0-255或者0-1之间的数值,代表明暗程度;彩色图片是RGB图像,RGB表示红,绿,蓝三原色,计算机里所有的颜色都是三原色不同比例组成的,即三色通道

(3)图像的传递
将二维图像经过flatten 展开成一维输入全连接网络中
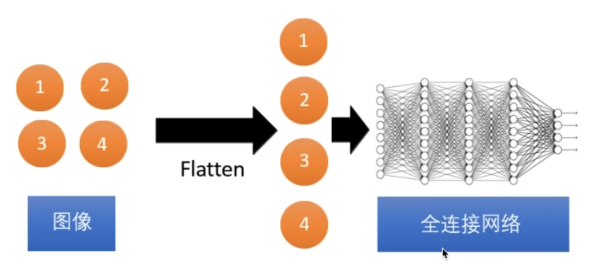
(4)训练数据
输入一组照片,通过全连接层的处理输出预测值和损失,损失越小越接近真实结果,因此需要找到最好的参数,即让所有的损失和最小,那么如何找到最好的参数呢?
现在选用的方法是梯度下降:

通过梯度下降不断迭代,调整初始参数,找到总损失比较小的最佳参数
三,卷积神经网络
(1)图片的特质
图片的一些模式比整张图片小的多
比如说要识别猫,可以只通过猫的一部分特征去进行识别,即一个神经元不需要看到整个图像去发现模式,可以通过较少的参数连接到小区域
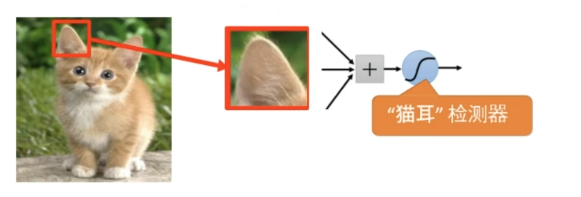
同样的模式可能出现在图像的不同区域
相同的猫耳检测器可以共享参数
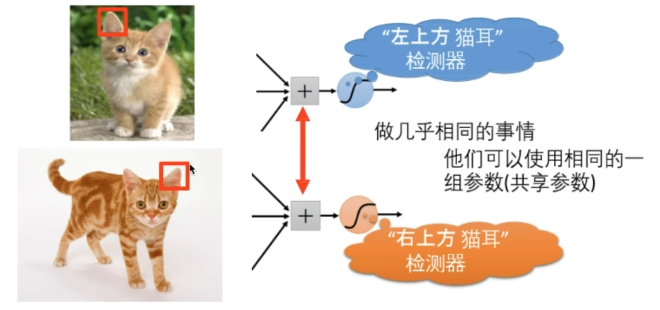
对图像进行缩放不会改变图像中的物体
当图片很大时,图片的像素点也会很多,那么图片传入神经网络后连接数就会很多,参数就会多。缩放后可以使参数减少,简化问题
(2)CNN模型
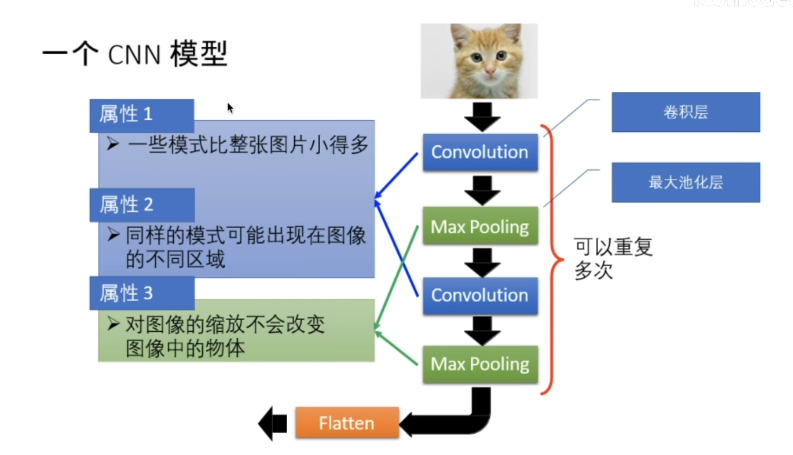
卷积层
卷积核在原始图片中起到探测模式的作用。可以发现卷积核的维度比原始图像要小,实现卷积的过程就是开始时,让卷积核从原始图像左上角对齐,对应每个小格子位置相乘,再将所有的结果相加,得到卷积结果矩阵的第一个值;再将卷积核向右移动,遍历原始图像,以此类推

不同的卷积核有不同的效果,而其中的值都是需要学习的参数
例:原始图片是8x8像素的,卷积核是3x3像素的,卷积结果是多少像素的?
答:6x6像素,8x8矩阵减去边缘一圈,即8-2=6
(1)边界处理
有两种边界处理方式,Full Padding和Same Padding

(2)Stride: 卷积核每次移动的步长
最大池化层
在每个小区域内最大值取出来组合,起到图像缩放的作用,减少参数

Flatten层
将二维图像经过flatten 展开成一维输入全连接层中
(3)keras
Sequential 模型:非常简单,只支持单输入,单输出的模型,适用于70%的应用场景
函数式API:支持多输入,多输出模型,适用于95%的应用场景
建立一个全连接层:
import keras
from keras import layers#导入层结构
model = keras.Sequential() #建立序列模型
# 全连接层(本层神经元个数,激活函数,输入图片参数值数量)
model.add(layers.Dense(20, activation='relu', input_shape=(10,)))
model.add(layers.Dense(20, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
# 训练模型
# x-样本数据即图片,y-图片标签,epochs=处理图片的次数,batch_size=一次性处理几张图片
model.fit(x, y, epochs=10, batch_size=32)建立一个卷积层:
keras.layers.Conv2D(filters, kernel_size, strides=(1,1), padding='valid', data_format=None)
# filters: 输出空间的维度
# kernel_size: 1个整数或2个整数表示的元组,2D卷积窗口的宽度和高度
# strides: 2个整数表示的元组,卷积沿宽度和高度方向的步长
# padding: 边界处理的方法,"valid"或"same"建立一个最大池化层:
keras.layers.MaxPooling2D(pool_size=(2,2), strides=None, padding='valid', data_format=None )
# pool_size: 沿(垂直,水平)方向缩小比例的因数,如果只有一个整数,则两个维度使用相同窗口长度
# strides: 2个整数表示的元组,步长值,None表示默认值pool_size
# padding: 边界处理的方法,"valid"或"same"四,代码实现
完整代码在末尾,所有的文件路径都需要修改成自己的文件路径喔!
(1)定义一个基础CNN模型
其中卷积层的卷积核数量为32,卷积核尺寸为3x3,激活函数为ReLU,padding设置为same,最大池化层的尺寸为2x2
#todo:创建一个cnn模型
def define_cnn_model():
#使用序列模型
model = Sequential()
#卷积层
model.add(Conv2D(32, (3,3), activation="relu",
kernel_initializer='he_uniform',
padding="same",
input_shape=(200,200,3)))
'''卷积核数量,卷积核维度,激活函数,padding,图片像素200x200,3代表彩色图片'''
#最大池化层
model.add(MaxPooling2D((2,2)))
#Flatten 层
model.add(Flatten())
#全连接层
model.add(Dense(128, activation="relu",kernel_initializer='he_uniform' ))
model.add(Dense(1, activation="sigmoid"))#输出层0,1,sigmoid模型实现输出值0~1之间,分别代表猫狗
#编译模型
opt = SGD(lr=0.001, momentum=0.9)#优化器,随机梯度下降,为模型找到最佳的参数
model.compile(optimizer=opt,
loss='binary_crossentropy',
metrics=['accuracy'])
return model
#打印模型图片
from keras.utils import plot_model
model = define_cnn_model()
plot_model(model,
to_file='cnn_model.png',
dpi = 100,
show_shapes=True,
show_layer_names=True)
打印出卷积神经网络模型图为:

训练模型:
#训练模型
def train_cnn_model():
#实例化模型
model = define_cnn_model()
#创建图片生成器,产生图片并输入
datagen = ImageDataGenerator(rescale=1.0 / 225.0)
train_it = datagen.flow_from_directory(
'C:\\Users\\Alixy\\Desktop\\ma1ogo3ushu4ju4ji2\\dogs_cats\\data\\train',
class_mode='binary',
batch_size=64, #一次产生并输入64张图片
target_size=(200, 200) #缩放图片为200x200,和输入图片大小相同!!!
)
#训练模型
model.fit_generator(train_it,
steps_per_epoch=len(train_it),
epochs=20,
verbose=1 )
#把模型保存到文件夹,basic_cnn_result.h5是提前就创建好的,用来保存模型的
model.save("D:\\python\\python\\MCM\\Data_clean\\basic_cnn_result.h5")运行训练模型:
if __name__ == "__main__":
train_cnn_model()这个构建的CNN模型在迭代20个epoch时,可以达到约95%的准确率,是一个不错的结果
使用训练好的模型做一些预测:
从测试文件夹中随机读取一张照片,并进行判断
#定义函数读取测试文件夹中的照片
def read_random_image():
folder = r'C:\\Users\\Alixy\Desktop\\ma1ogo3ushu4ju4ji2\\dogs_cats\\data\\test\\'
file_path = folder + random.choice(os.listdir(folder))
print(file_path)
pil_im = Image.open(file_path, 'r')
return pil_im
#对一个使用模型对读取出的图片进行预测
def get_predict(pil_im, model):
#对图片进行缩放
pil_im = pil_im.resize((200,200)) #这里很重要,要符合后面输入图片规定的大小
#将格式转换为 numpy array 格式
array_im = np.asarray(pil_im)
array_im = np.expand_dims(array_im, axis=0)
#对图片进行预测
result = model.predict(array_im)
if result[0][0] > 0.5:
print("预测结果是:狗")
else:
print("预测结果是:猫")
pil_im = read_random_image()
get_predict(pil_im, model)
pil_im.show(np.asarray(pil_im)) #显示随机选取的照片输出结果:


(2)完整代码
CNN_train.py
#导入需要的包
import sys
from matplotlib import pyplot
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Dense
from keras.layers import Flatten
from keras.optimizers import SGD
from keras.preprocessing.image import ImageDataGenerator
import tensorflow as tf
tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR)
#todo:创建一个cnn模型
def define_cnn_model():
#使用序列模型
model = Sequential()
#卷积层
model.add(Conv2D(32, (3,3), activation="relu",
kernel_initializer='he_uniform',
padding="same",
input_shape=(200,200,3)))
'''卷积核数量,卷积核维度,激活函数,padding,图片像素200x200'''
#最大池化层
model.add(MaxPooling2D((2,2)))
#Flatten 层
model.add(Flatten())
#全连接层
model.add(Dense(128, activation="relu",kernel_initializer='he_uniform' ))
model.add(Dense(1, activation="sigmoid"))#输出层0,1,sigmoid模型实现输出值0~1之间,分别代表猫狗
#编译模型
opt = SGD(lr=0.001, momentum=0.9)#优化器,随机梯度下降,为模型找到最佳的参数
model.compile(optimizer=opt,
loss='binary_crossentropy',
metrics=['accuracy'])
return model
#打印模型图片
from keras.utils import plot_model
model = define_cnn_model()
plot_model(model,
to_file='cnn_model_basic.png',
dpi = 100,
show_shapes=True,
show_layer_names=True)
#训练模型
def train_cnn_model():
#实例化模型
model = define_cnn_model()
#创建图片生成器,产生图片并输入
datagen = ImageDataGenerator(rescale=1.0 / 225.0)
train_it = datagen.flow_from_directory(
'C:\\Users\\Alixy\\Desktop\\ma1ogo3ushu4ju4ji2\\dogs_cats\\data\\train',
class_mode='binary',
batch_size=64, #一次产生并输入64张图片
target_size=(200, 200) #缩放图片为200x200,和输入图片大小相同
)
#训练模型
model.fit_generator(train_it,
steps_per_epoch=len(train_it),
epochs=20,
verbose=1 )
#把模型保存到文件夹
model.save("D:\\python\\python\\MCM\\Data_clean\\basic_cnn_result.h5")
if __name__ == "__main__":
train_cnn_model()CNN_predict.py
from keras.models import load_model
#模型地址
model_path = 'D:\\python\\python\\MCM\\Data_clean\\basic_cnn_result.h5'
#载入模型
model = load_model(model_path)
import os, random
import numpy as np
from PIL import Image
#定义函数读取测试文件夹中的照片
def read_random_image():
folder = r'C:\\Users\\Alixy\Desktop\\ma1ogo3ushu4ju4ji2\\dogs_cats\\data\\test\\'
file_path = folder + random.choice(os.listdir(folder))
print(file_path)
pil_im = Image.open(file_path, 'r')
return pil_im
#对一个使用模型对读取出的图片进行预测
def get_predict(pil_im, model):
#对图片进行缩放
pil_im = pil_im.resize((200,200))
#将格式转换为 numpy array 格式
array_im = np.asarray(pil_im)
array_im = np.expand_dims(array_im, axis=0)
#对图片进行预测
result = model.predict(array_im)
if result[0][0] > 0.5:
print("预测结果是:狗")
else:
print("预测结果是:猫")
pil_im = read_random_image()
get_predict(pil_im, model)
pil_im.show(np.asarray(pil_im)) #显示随机选取的照片有错误欢迎指正!😃