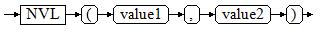1.索引简介
官网介绍:MySQL :: MySQL 8.0 Reference Manual :: 10.3.1 How MySQL Uses Indexes
索引用于快速查找具有特定列值的行。如果没有索引, MySQL 必须从第一行开始,然后读取整个表以找到相关的行。表越大,花费就越多。如果表中有相关列的索引,MySQL 可以快速确定数据文件中间要查找的位置,而不必查看所有数据。这比按顺序读取每一行要快得多。
我们来看一个案例,假设我有一个50w数据的表没有索引的情况下我的查询速度。

当我为product_price字段建立索引后的查询速度
ALTER table product_new ADD INDEX idx_product_price(product_price) -- 建立索引
那么索引究竟是怎么提升性能的呢?
官网:MySQL :: MySQL 8.0 Reference Manual :: 10.3.1 How MySQL Uses Indexes
Most MySQL indexes (
PRIMARY KEY,UNIQUE,INDEX, andFULLTEXT) are stored in B-trees. Exceptions: Indexes on spatial data types use R-trees;MEMORYtables also support hash indexes;InnoDBuses inverted lists forFULLTEXTindexes.
看到这里我们就知道了,索引是存储在B-trees中的,也就是我们所说的B+树,是一种数据结构,那么索引其实就是用空间换时间。单独把偶你一些额外的,能帮助提高检索性能的数据。
思考: 上面提到了2种数据结构,一种是B+树,一种是hash,区别是什么呢?是不是所有的存储引擎都支持呢?
1.B+tree 支持范围,但是 Hash 是 k-v 的形式,所以不支持范围查询2. 查询性能,如果等值查询, hash 比 tree 要快很多,还是因为它是 k-v 的hash结构1.B+tree 在 MyISam 跟 memory 、 innoDB 都支持2.hash 索引只支持 memory , InnoDB 有页自适应,但是不是 hash 索引
2.B+树索引
博客Mysql之Innodb存储引擎-CSDN博客 中已经介绍了我们查询数据的时候,会先从内存查询,如果内存没有,会去磁盘获取,内存跟磁盘的最小交互单位是页。页里面存储的是数据行。
那我们举个例子,假如我现在有个表zsc_teacher,这里有18条数据,这些都是行,行我们都会放到page页中,一个页的大小是有限制的,默认16k。我们假设我们的每个页只能存放3条数据,那么这18条数据就需要放到6个页。页里面的数据保存规则是什么呢?
1. 页里面的数据一定要排序,假如默认得根据主键排序,如果没有主键,非空的唯一字段,如果还没有,用隐藏的row_id 排序字段2. 页中的数据需要是单链表链起来,这样能让我快速的去操作相关数据,链表的操作性能更高,加数据的时候,我只需要更改前后的链表指向就行。3. 既然需要很多的页,那么页跟页一定要连起来,我得知道这个页的下一个页是哪个,我才能去找,所以页跟页之前是一个双向链表,并且下一个页的最小数据必须大于上一个页的最大数据。
如图所示,我们的zsc_teacher表在页中的存储如下:

每行上面的0代表的是这是一个数据行,假如,我现在要去插id=50的数据,我就需要从第一页开始,遍历6个页。页又是内存跟磁盘的最小交互单位,所以我最多可能需要跟磁盘进行6次IO,页跟 页之间又是一个双向链表的关系,查询性能是O(n),页越多,要查后面的数据遍历的页也就越多。那么索引是怎么提升我们的查询性能的呢?
首先,为每个完整的行数据创建一个目录行,目录行中只保存这个页的最小值以及这个最小值所在的页码,因此,这样依赖,页的空间就多了,因此可能保存的目录行就不止3个了,我们假设此时保存的是4个。
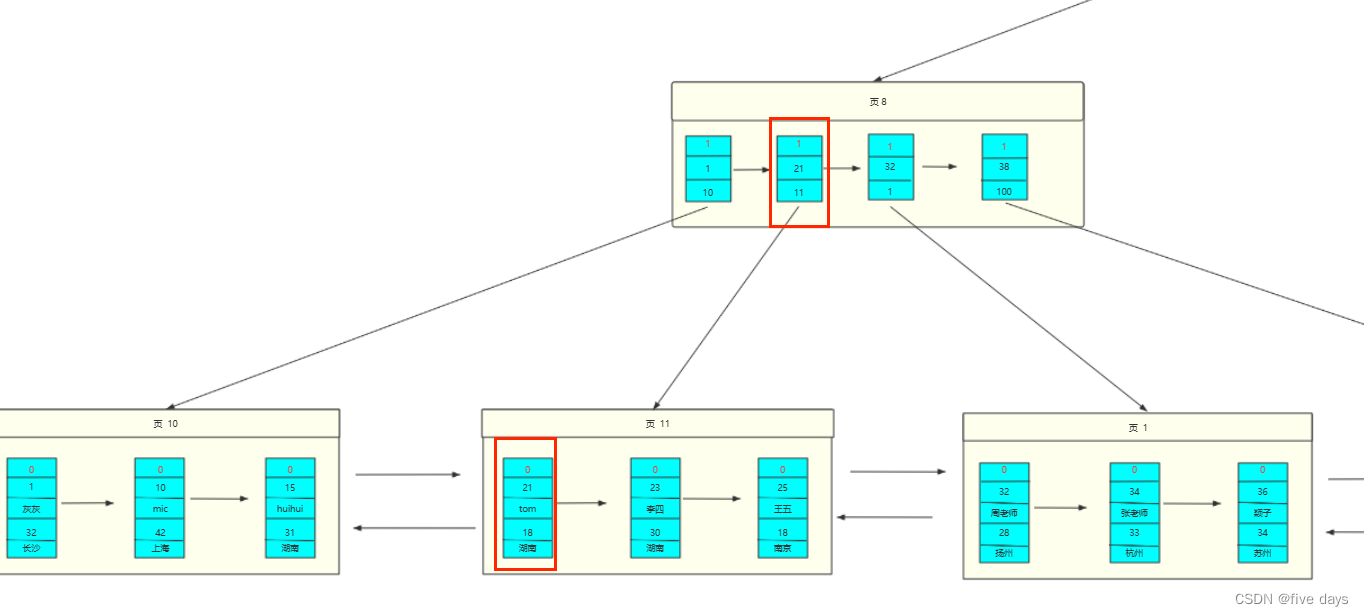
这样一来,我们6个页的数据,就需要2个目录页来保存就可以了,但是2个目录页来保存,想按照树的方式去查询,还是不行,因为没有跟目录,因此依照上面的原理,再建立一个根目录页出来。最终的树形结构如下所示:

这样,我们再去查询一遍id=50的数据
1.遍历根目录。 有2条目录数据,50大于44,所以去二级目录的888页
2. 遍历 888 页, 50 大于 49 ,去页 22 找3. 遍历页 22 的数据,找到 50
我们发现相比之前遍历的6个页。我现在只需要遍历3个页,并且这3个页是稳定的,因为遍历的页面数就是这棵树的高度。树越高,遍历的页面就越多,树越低,遍历的页数就越少,跟磁盘IO的次数也就越少,性能越高。
B+树索引有哪些优势呢?
1. 叶子节点才会有完整的一行数据,而非叶子节点是目录,非叶子节点的行大小就越小,越小,那能放的数据就越多,数据越多,同样层级的树能容纳的数据也就越多,或者同样的数据量可能需要的树的高度越低,高度越低,磁盘可能IO 的次数越少,性能越高。所以 整体性能比其他树更好2. 稳定,不管你查什么,因为非叶子结点没有完整的行数据,所以都需要遍历树的高度。3. 叶子节点是有序并且链表关联,所以可以更好的范围查询跟遍历。
3.索引类型
3.1 聚簇索引、二级索引
主键、聚集、聚簇索引(Clustered Index): 每个InnoDB存储引擎都会有且只有一个Clustered Index索引树,默认以主键排序,如果没有主键,会用非空的唯一字段,非空的唯一字段也没有,就会用隐藏的row_id。
二级索引(secondary Indexes): 除Clustered Index外的单列、多列索引,手动去基于哪些字段建立索引时,会根据这些字段排序创建一个B+树,排序规则先根据第一个字段,第一个字段相等根据第二个,以此类推。 注意: 二级索引不会有完整的行数据,只有索引的字段以及Clustered Index的排序字段。
举例: 以zsc_teacher表为例,假设我建立了一个age字段的索引,就会以age排序建立索引树,后续根据age去查询的时候就会快很多。
如果是多个字段呢?假如我根据age name建立联合索引,则索引树上就会有age、name字段以及clustered Index的排序字段。在索引树的排序规则是先根据a排序,如果a相等,再根据b排序(这就是索引最左匹配的本质),如图所示:
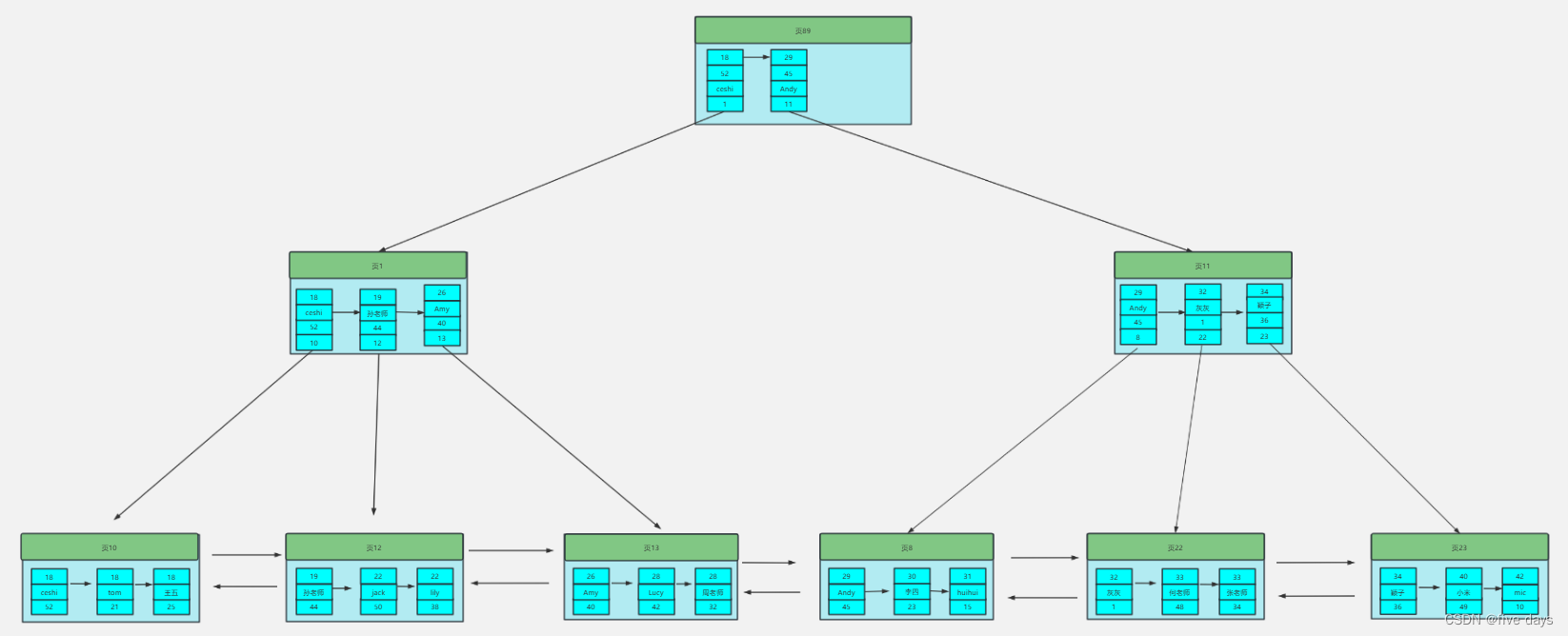
3.2 回表、覆盖索引
回表: 查询走的索引树,不包含我们要查询的字段,需要根据clustered Index的排序字段回到clusterd Index去查询需要的字段。
举例: 比如我们要查询
select * from zsc_teacher where age = 32;由于我们查询的是*,是全部数据,因此即使我们age创建了索引,但是我们的二级索引树中只包含了age,name 和id。并没有全部数据,这个时候就需要查到id后,再回表去查询所有的数据,这个过程就叫做回表。
覆盖索引: 查询计划走到的索引树包含了需要查询的字段,不需要回到Clustered Index查询。
举例:
select age,name from zsc_teacher where age = 32;这条sql,我们只查询age和name,由于age和name都在二级索引树中,因此我们此时就不需要再去回表操作,这个就叫做覆盖索引
3.3 索引下推
索引下推: 把本来要在server层执行器里过滤的数据,移动到二级索引树(如果二级索引树有相关数据能过滤),从而达到减少回表的次数以及server层跟存储层之间的数据交互的目的。
举例,我们执行这样的一条sql
select * from zsc_teacher where age = 13 and name like '%huihui1' 
分析: 由于我建立了一个age与name的联合索引,所以age一定是有序的,我这个查询也就肯定能走到age的联合索引,查询age等于13我能查到两条;然后第二个条件,like 百分号开头,由于是百分号开头,所以这个字段肯定是走不到索引的,走不到索引,并且没有索引下推的情况,我会把这两条数据都给到我们的server层,然后server层会去过滤,当然了,在过滤之前,由于查询的是*,因此我会回表两次,再返回给我们的server层。
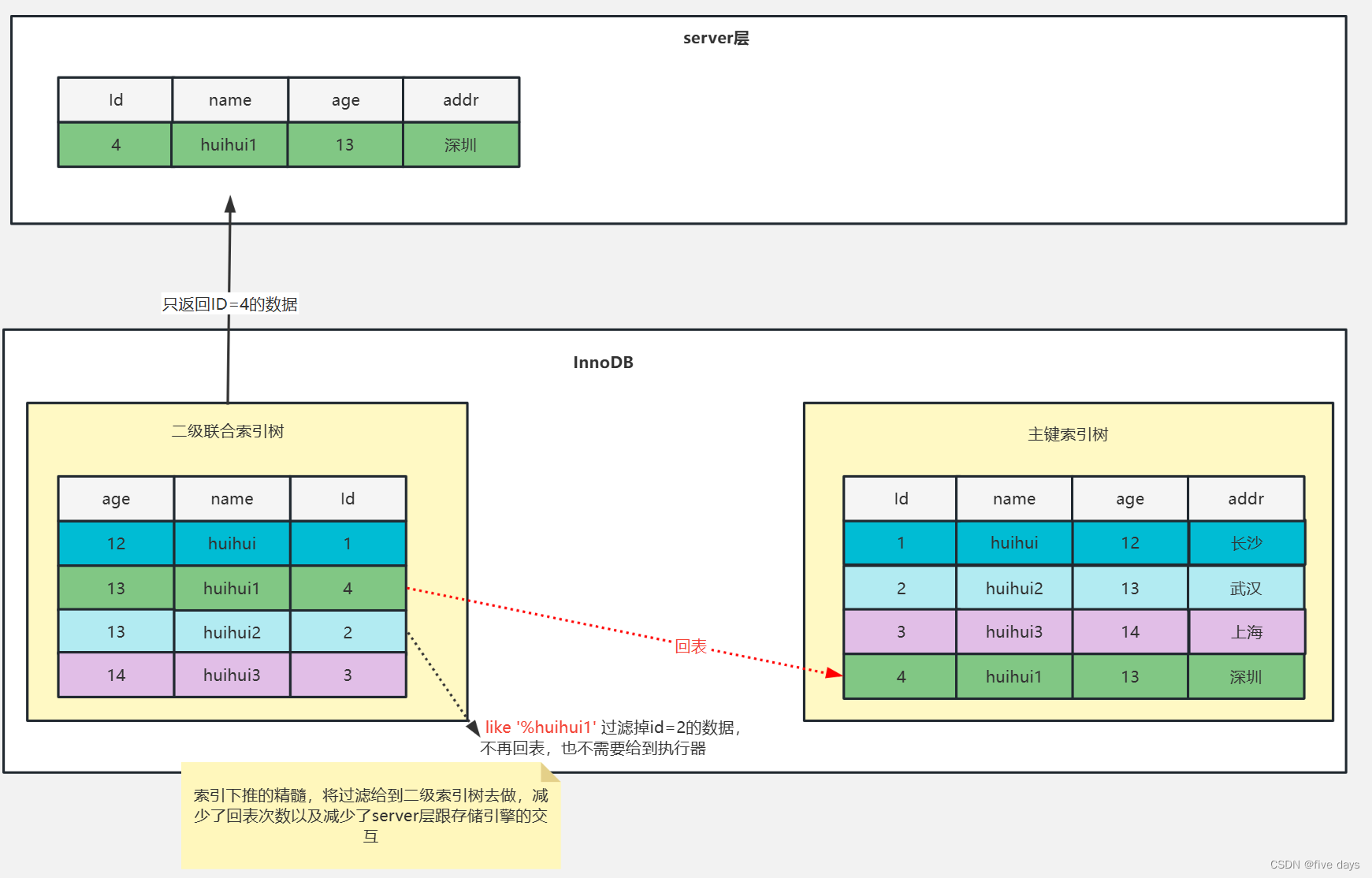
分析: 有了索引下推以后,虽然还是只有age能够走到我们的索引,name同样的走不到索引,但是由于name这个字段 在我的二级索引里面是有的,既然有,那我就可以在二级索引中把它过滤掉,虽然我根据age还是扫到了两条,但是我可以根据这个二级索引去把这个huihui2给过滤掉,这样我就不需要回表两条,也不需要给到server层两条,所以这个就是索引下推,索引下推的精髓就是把过滤的条件在我们的存储引擎中,基于二级索引去做掉,减少回表的次数以及减少server层跟存储引擎的交互数量。
当然,也可以进行配置 开启或者关闭
set optimizer_switch = 'index_condition_pushdown=off'
set optimizer_switch = 'index_condition_pushdown=on'
思考: 既然我们了解了索引的原理,那么什么情况下索引会失效呢?
我们举个例子,假如我们建立了一个组合索引a , b , c查询条件 c=10 and a = 1 and b>= 30,是否都会用到索引呢?
联合索引 abc ,在索引树是先根据 a 排序, a 相同的根据 b 排, b 相同的再根据c 排。首先,最左匹配原则: a where 条件中存在,满足,所以肯定能走到索引树,但是不确定是否所有条件都会走。继续最左, b b 在条件中也存在,所以 b 也能走到索引。但是 b 是个范围查询,范围查询后,c 就是无序的。
总结索引失效的场景:
- 不满足最左匹配
- 范围查询会使下一个索引列失效,因为下一个是无序的
- 类型转换,排序规则是不一样
- 运算
总之,一句话,走不走索引,其实是索引优化器说了算,索引我们要学会怎么查看执行计划。
4.执行计划分析
我们要分析sql语句究竟走不走索引,要去看执行计划,怎么看?很简单,explain加上sql语句就行,适用于select、delete、insert、replace、和update等语句
举例:
explain select * from b_bid_info where id = 3090;
输出字段的官网介绍: MySQL :: MySQL 8.0 Reference Manual :: 10.8.2 EXPLAIN Output Format
select_type: 查询类型
partitions: 分区,查询语句要走哪些分区 MySQL :: MySQL 8.0 Reference Manual :: 26.3.5 Obtaining Information About Partitions
type: 连接类型 MySQL :: MySQL 8.0 Reference Manual :: 10.8.2 EXPLAIN Output Format
system( 特例 const, 系统表中只有 1 行 ) 、 const 、 eq_ref 、 ref 、 fulltext 、ref_or_null、 index_merge 、 unique_subquery 、 index_subquery 、range、 index 、 ALL
我们的执行计划最好能达到range,如果达不到,就要进行优化
possible_keys: 可以选择的索引查询,如果为null 则没有索引可供选择
key: 真正使用到的索引
key_len: 使用的键的长度
ref: 索引引用关系
rows: 执行查询必须扫描的行数,对于innodb来讲,这是个预估值,不是非常准确
filtered: 行数据过滤百分比
Extra:MySQL :: MySQL 8.0 Reference Manual :: 10.8.2 EXPLAIN Output Format
5.索引优化案例
5.1 count优化
count是一个聚合函数,对于返回的结果集是一行一行去判断统计的,如果count括号里的不是null,那么累计值+1,否则不加,最后返回一个累计的总数。
括号里的字段选择:
count 括号里的参数应该是 id 、还是字段、还是 1 、还是 *1. * 是整条数据,也进行了优化,因为整条数据肯定不会为 null 。所以也不需要去判断2. count(id ) , 主键 id ,肯定不为 null ,也不会去判断 null, 但是相对于count(1)来讲,要去解析 ID. 稍微慢点,但是也可以忽略不计3. count( 字段),如果字段没有索引,就需要进行全表扫描, explain 是all; 如果字段不为 null ,那么不需要进行 null 逻辑判断,如果可为空,则每条数 据要进行非空判断
5.2 limit优化
limit m,n; 其实去扫描m+n条数据,然后过滤掉前面的m条数据,当m越大,那么需要扫描的数据也就越多,性能也会越来越慢。
EXPLAIN SELECT * FROM product_new LIMIT 300000,10 -- 很慢很慢
EXPLAIN SELECT * FROM product_new ORDER BY id LIMIT300000,10
-- 需要添加排序条件 就能走到id的索引针对这种情况,有以下几个方案可以进行优化
1.如果id是趋势递增的,那么每次查询都可以返回这次查询最大的ID,然后下次查询,加上大于 上次最大id的条件,这样会通过主键索引去扫描,并且扫描数量会少很多很多。因为只需要扫描where条件的数据
SELECT * FROM product_new WHERE id>300396 ORDER BY id LIMIT 10
-- 根据id查询,并且使用where过滤2.先limit出来主键ID,然后用主表跟查询出来的ID进行inner join 内连接,这样,也能一定上提速,因为减少了回表,查询ID只需要走聚集索引就行。
SELECT * FROM product_new INNER JOIN
(
SELECT id FROM product_new ORDER BY id LIMIT 300000,10
) a
ON product_new.id=a.id3.当然,如果mysql级别优化不了了。我们也可以对分页数据进行缓存,比
如 Redis 缓存,数据进行变动的时候,做好缓存依赖即可
4.因为越往后,一般用户行为触及不到,比如你去看淘宝,不会去翻后面几
百页的数据,所以,业务层面也可以做一些让步,最多展示多少页。
5.3 order by优化
官网介绍: MySQL :: MySQL 8.0 Reference Manual :: 10.2.1.16 ORDER BY Optimization
如果让 orderby 的字段走索引,那么排序流程直接可以在索引树完成,如果排序的字段不走索引,整个排序流程必须先把数据放到内存,在内存实现排序。这个内存的大sort_buffer_size 配置 , 如果内存不够保存这个数据,那么就会启用磁盘的临时文件来进行排序。
怎么判断orderby是否用到了索引?
如果输出 Extra 的列 EXPLAIN 不包含 Using filesort ,则使用索引如果输出 Extra 列 EXPLAIN 包含 Using filesort ,则不使用索引
5.4 group by优化
官网介绍: MySQL :: MySQL 8.0 Reference Manual :: 10.2.1.17 GROUP BY Optimization
首先,我们先看下group by如果没有走到索引的实现流程
1. 会将符合条件的数据扫描后,放到一个临时表,并且这个临时表是根据group by的字段排序好的2. 然后在临时表根据用户的聚合需求,比如是求 count 、 sum, 返回给用户相关结果
举例:
EXPLAIN SELECT SUM(product_type), product_count FROM
product_new WHERE product_type=6 GROUP BY product_count;分析: product_type属于一个索引,product_count属于另外一个索引。会先通过product_type索引拿到结果,然后放入临时表中进行分组处理。结果,用到了临时表

但是如果groupby写得够好,那么就可以避免创建临时表的逻辑,让直接通过索引来group by。防止group by去创建临时表,有2种场景: loose index scan(松散索引)和tight index scan(紧密索引),感兴趣的想深入研究的可以去官网上查看,有具体的实例。
6.慢查询及优化
6.1 慢日志参数
是否开启慢查,默认情况是关闭的
SET GLOBAL slow_query_log=1; -- 开启慢查慢时间,必须超过这个值才是慢查
SELECT @@long_query_time; -- 默认是10 单位s
SET GLOBAL long_query_time=1; -- 设置超过1s就算慢查检索数量,检索查询数量的行如果低于这个值,不进入慢查
SELECT @@min_examined_row_limit; -- 默认是 0慢查默认不包括管理语句,比如创建表、创建索引等等
SELECT @@log_slow_admin_statements;
SET GLOBAL log_slow_admin_statements=1; -- 开启默认也不记录不使用索引的慢查
SELECT @@log_queries_not_using_indexes;
SET @@GLOBAL.log_queries_not_using_indexes=1; -- 开启日志保存方式,FILE或table,也可以table,file或者null,代表禁用日志写入
SELECT @@log_output; -- 慢查存在哪里
SET GLOBAL log_output='table,file'; -- 比如我希望2边都保存比如添加到file
SELECT @@slow_query_log_file;
SET GLOBAL slow_query_log_file='/var/lib/mysql/huihuislow.log';如果是表,则保存在mysql.slow_log表中
6.2 慢日志分析
表分析:
查询 mysql.slow_log 表,慢查在我们的慢查表中
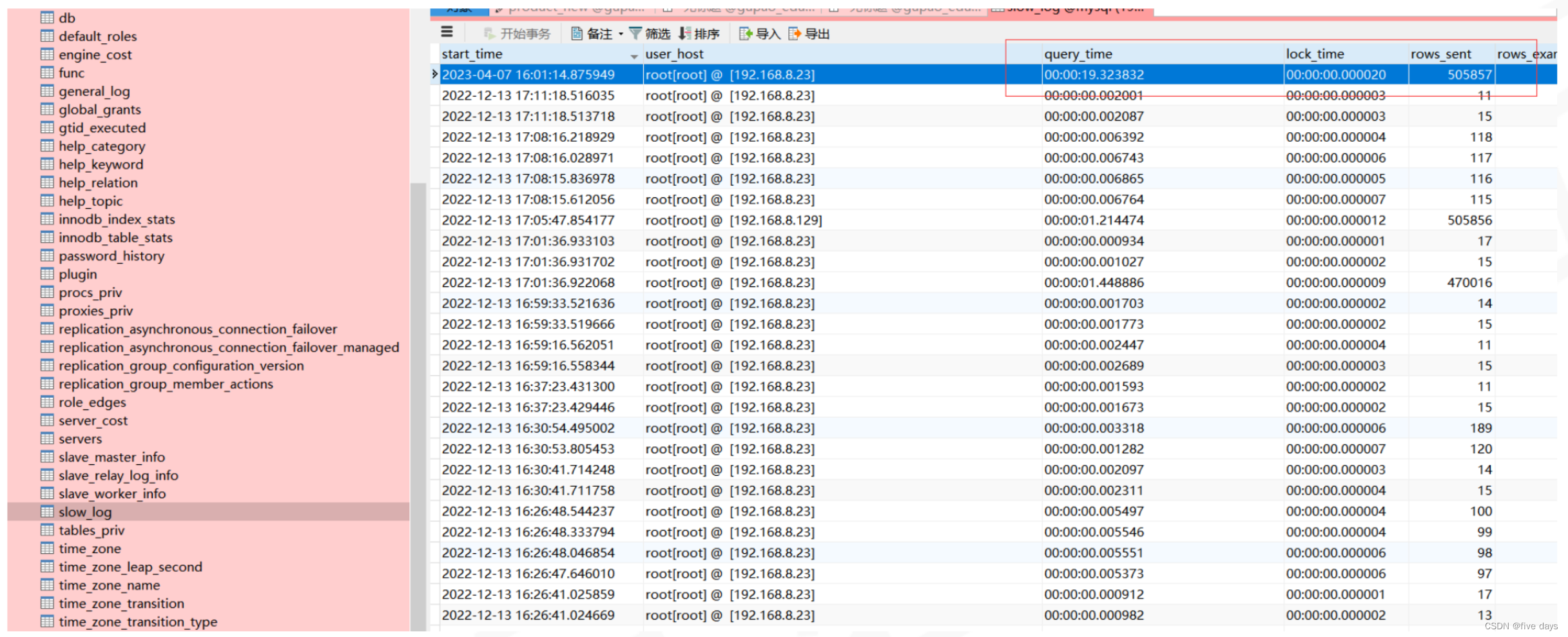
我们发现,sql_text是一些二进制,我们需要给它转码一下
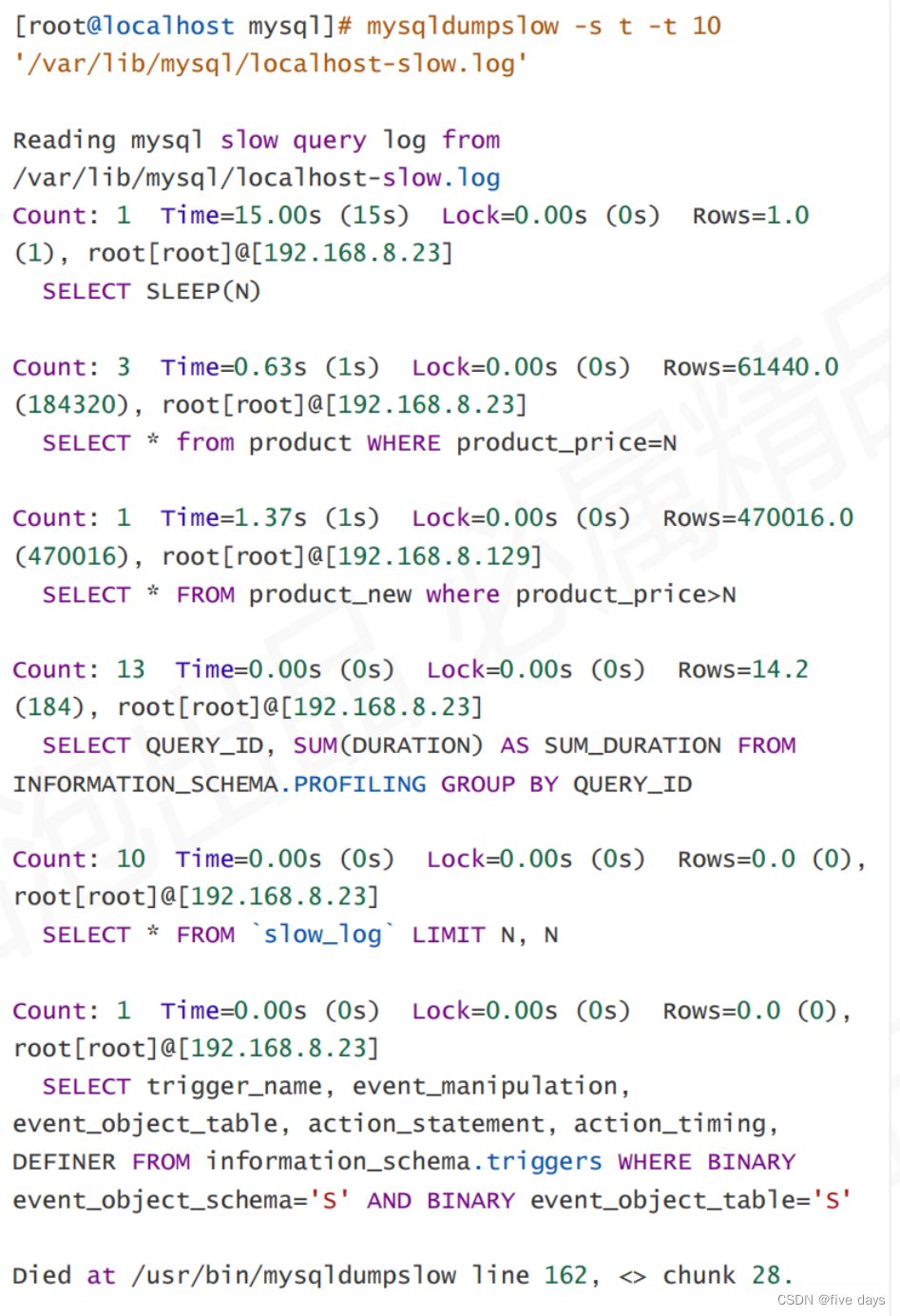
SELECT *,CONVERT(sql_text using utf8) FROM slow_log文件分析:MySQL :: MySQL 8.0 Reference Manual :: 6.6.10 mysqldumpslow — Summarize Slow Query Log Files
官网中有提供慢查分析的指令,mysqldumpslow
6.3 mysql优化
a.硬件层面优化,我们知道Mysql最重要的瓶颈在磁盘的io,所以硬件层面,最终的其实就是磁盘
1. 提高磁盘读写能力,可以用比较新型的磁盘2. 减少寻址时间,可以横向扩展,将数据添加到不同的磁盘,每个磁盘数据的寻址通常1s 100 次寻址,那么单个磁盘有限制,就多个磁盘寻址3. 当然,除了磁盘以外, cpu 、内存以及带宽也是比较重要的因素; 增加服务器资源部署主从、多主多从等集群
b 数据库层面优化
b.1 表结构优化
1.字段类型 尽可能使用最小的并且满足业务场景的数据类型,这样行数据占用的内存越小,索引树越矮,磁盘IO 次数越低。同时尽量避免 null字段出现,可以指定默认值,减少判断null 的开销,因为有 null 的时候,索引需要对null 进行单独处理2.合适的存储引擎3.分库分表;横向拆分,就统一的业务表 数据量可能会很大,为了减少单表的压力,比如产品表 分为产品表1 、 2 、 3;纵向拆分 则是业务相对独立的模块 单独拆分表。以及表字段过多的时候,会进行分表。
b2.Innodb存储引擎优化
1. 增加 bufferpool 大小bufferpool 我们知道是 innodb 里面缓存数据的内存区间,默认大小为128M , bufferpool 越大,那么内存能放的数据越大,这样,查询数据去磁盘查询的次数也就越少。2. 增加重做日志大小