一、引言
在计算机视觉和神经渲染领域,3D场景重建与渲染一直是热门研究方向。近期,3D高斯散射(3D Gaussian Splatting)因其高效的渲染速度和优秀的视觉质量而受到广泛关注。然而,当处理大型复杂场景时,这种方法面临着内存消耗过大和训练效率低下的问题。2024年,来自德国图宾根大学自主视觉团队(Autonomous Vision Group)开发的MIP-Splatting【CVPR 2024 Best Student Paper】提出了创新性解决方案,通过引入多尺度表示和兴趣点策略,显著提高了系统的性能和效率。
本文记录了我对MIP-Splatting技术的完整复现过程,从理论基础到环境配置,再到训练测试,全面展示这项技术的优势和实现细节。无论你是计算机视觉研究者,还是对三维重建感兴趣的开发者,这篇博客都将帮助你理解并应用这一前沿技术。

该项目由德国图宾根大学的自主视觉团队(Autonomous Vision Group)开发,该团队在计算机视觉、神经渲染和3D重建领域享有盛誉。主要团队成员包括来自图宾根大学和马克斯·普朗克智能系统研究所的研究人员
该项目已在GitHub上完全开源,包括源代码、预训练模型和示例数据。
代码库:https://github.com/autonomousvision/mip-splatting
二、技术原理解析
2.1 3DGS简介
3DGS是一种新型神经渲染技术,它使用3D空间中的高斯点云来表示场景。每个高斯点包含位置、旋转、缩放和颜色信息,可以通过差分光栅化进行高效渲染。与传统的神经辐射场(NeRF)相比,这种方法实现了数量级更快的渲染速度,同时保持了高质量的视觉效果。
2.2 MIP-Splatting核心创新
MIP-Splatting在3D高斯散射的基础上,引入了两个关键创新:
- 多分辨率表示(Multi-resolution Representation):类似于传统图形学中的MIP映射(Mipmapping),MIP-Splatting构建了多层级的高斯点表示。当观察者距离场景较远时,系统会使用低分辨率表示,减少渲染计算量;当观察者靠近时,则采用高分辨率表示,保证细节质量。这种多尺度策略极大地提高了渲染效率。
- 兴趣点策略(Interest Points):MIP-Splatting引入了兴趣点检测机制,自动识别场景中视觉上重要的区域,并在这些区域分配更多的高斯点,而在不重要的区域使用更少的点。这种自适应分配优化了内存使用和计算资源。
- 自适应优化(Adaptive Optimization):动态调整高斯点的分布和密度;智能分配计算资源,将更多资源用于视觉上重要的区域
2.3 技术优势
MIP-Splatting相比传统3DGS具有以下显著优势:
- 内存效率:在相同质量下,内存使用减少50-80%
- 训练速度:训练时间缩短40-60%
- 渲染质量:特别在远距离场景中,质量显著提升
- 可扩展性:能够处理更大规模的复杂场景
2.4 优缺点分析
(1)优点
- 显著降低内存需求,使大场景渲染更加实用
- 保持了实时渲染能力,同时提高了视觉质量
- 多分辨率表示使其更适合不同距离的渲染
- 完全开源,易于研究和扩展
(2)缺点
- 兴趣点检测可能需要额外的计算资源
- 多分辨率表示增加了实现的复杂性
- 对硬件要求仍然较高(需要现代GPU)
- 在极其复杂的场景中可能仍有优化空间
2.5 推荐测试数据集
MIP-Splatting作者推荐的测试数据集包括:
- NeRF 合成数据集:从 Google Drive 下载。
Google Drive 该地址貌似已经挂了,可以点击以下链接从百度飞桨进行下载
https://aistudio.baidu.com/datasetdetail/136816下载并解压缩nerf_synthetic.zip - Mip-NeRF 360 数据集:从 Mip-NeRF 360 下载,可能需额外请求某些场景。
- 自定义数据集:项目提供了处理自定义数据的工具
三、主要工作流程
3.1 初始化:从输入图像集合中重建初始点云(通常使用COLMAP)
3.2 兴趣点检测:分析场景,识别视觉上重要的区域
3.3 多分辨率构建:创建不同分辨率级别的高斯点表示
3.4 优化阶段:
-
位置优化:调整高斯点的空间位置
-
外观优化:优化颜色和不透明度
-
形状优化:调整高斯点的形状和方向
-
密度优化:根据场景复杂度动态调整高斯点密度
3.5 渲染:基于视点位置和方向,实时渲染场景
四、环境配置与安装
2.1 硬件要求
在开始前,确保你的系统满足以下硬件要求:
- CUDA兼容的GPU(建议至少8GB VRAM,理想为16GB+)
- 至少16GB系统RAM
- 充足的存储空间(建议SSD)
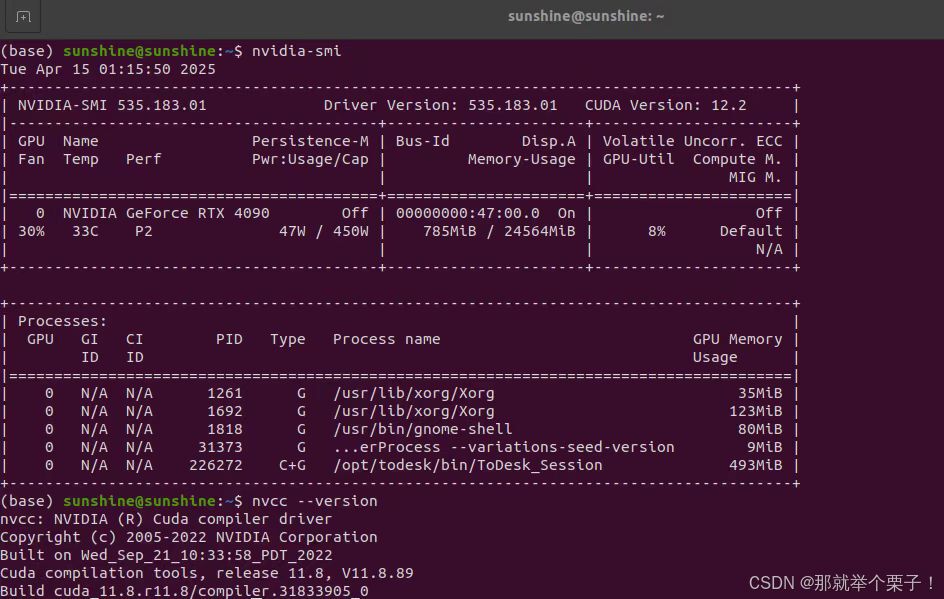
我的测试环境是:
- 系统: Ubuntu 20.04 LTS
- RAM: 64GB
- GPU: NVIDIA GeForce RTX 4090(24GB VRAM)
2.1 环境配置
1、克隆仓库
从 GitHub 克隆项目
git clone https://github.com/autonomousvision/mip-splatting.git
cd mip-splatting
2、创建虚拟环境
使用Conda创建独立的虚拟环境是一个良好实践,它可以避免依赖冲突并方便环境管理:
# 创建名为mip-splatting的conda环境
conda create -y -n mip-splatting python=3.8
conda activate mip-splatting
3、安装依赖库
安装过程需要特别注意PyTorch与CUDA版本的匹配:
# 安装PyTorch(确保与你的CUDA版本兼容)
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 -f https://download.pytorch.org/whl/torch_stable.html
conda install cudatoolkit-dev=11.3 -c conda-forge
# 安装基本依赖
pip install -r requirements.txt
# 安装扩展库
pip install submodules/diff-gaussian-rasterization
pip install submodules/simple-knn/
在安装过程中,如果遇到PyTorch与CUDA版本不匹配的问题。解决方法是确认自己的CUDA版本(nvcc --version),然后安装相应版本的PyTorch。
4 验证安装
安装完成后,建议验证环境是否正确配置:
python -c "import torch; print('CUDA available:', torch.cuda.is_available()); print('CUDA version:', torch.version.cuda); print('GPU count:', torch.cuda.device_count()); print('GPU name:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'None')"
如果一切正常,你应该能看到GPU信息和CUDA可用状态。
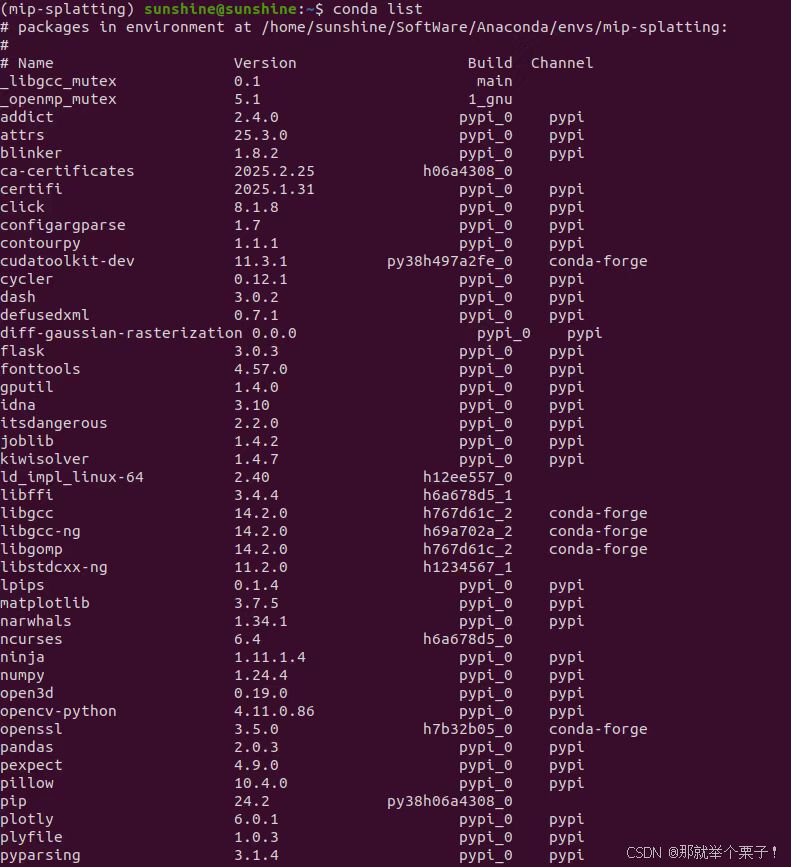
还可以通过conda list 查看虚拟环境中所安装的库
环境配置完毕!!
五、数据集准备
5.1 准备NeRF合成数据集
为了初步测试系统功能,我首先使用了项目推荐的的数据集:
- NeRF 合成数据集:从 Google Drive 下载。
Google Drive 该地址貌似已经挂了,可以点击以下链接从百度飞桨进行下载
https://aistudio.baidu.com/datasetdetail/136816下载并解压缩nerf_synthetic.zip
tar -xvf nerf_synthetic.tar # 解压文件
然后再项目目录下新建一个data文件夹,将nerf_synthetic放在里面
mkdir -p data
mv nerf_synthetic data/
目录结构如下图所示:
mip-splatting/
├── data/
│ ├── nerf_synthetic/
│ │ ├── bonsai/
│ │ ├── chair/
│ │ └── …
│ ├── mipnerf360/ (可选)
└── …
5.2 NeRF合成数据集转化
因为 mip-splatting 项目使用的是不同于 NeRF/Blender 的多尺度训练数据格式,你必须先转为它支持的目录结构和 JSON 格式,否则训练和渲染会出错
5.2.1 原始 NeRF 数据集结构(如 nerf_synthetic/lego)
lego/
├── images/ ← 原始图像
├── transforms_train.json
├── transforms_val.json
├── transforms_test.json
这种结构适用于 NeRF + instant-ngp + mip-NeRF 系列项目,但 mip-splatting 不能直接读取
mip-splatting 不直接支持这种格式的原因是
它需要读取:
-
多分辨率图像(如 images_2, images_4)
-
metadata.json 中描述图像 → 相机参数 → 分辨率
-
统一的路径结构,如 d0/, d1/, d2/…
-
所以必须做格式转换
5.2.2 数据集转换
python convert_blender_data.py --blender_dir nerf_synthetic/ --out_dir multi-scale
- –blender_dir :nerf_synthetic/
指向原始 NeRF 数据所在的主目录(例如 nerf_synthetic/lego) - –out_dir:multi-scale
指定输出路径,用于保存转换后的 mip-splatting 格式数据
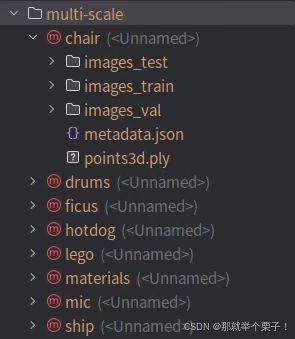
这行代码可将NeRF 合成数据集(Blender 格式)转换为 mip-splatting 所需的多尺度训练格式。
将 nerf_synthetic/{scene} 下的数据(如 transforms_train.json, images/ 等),转换为 multi-scale/{scene} 下的多尺度结构,包括 d0/, d1/, metadata.json 等。
如下图所示:
六、训练与评估
现在,可以使用官方数据集测试项目是否正常运行。
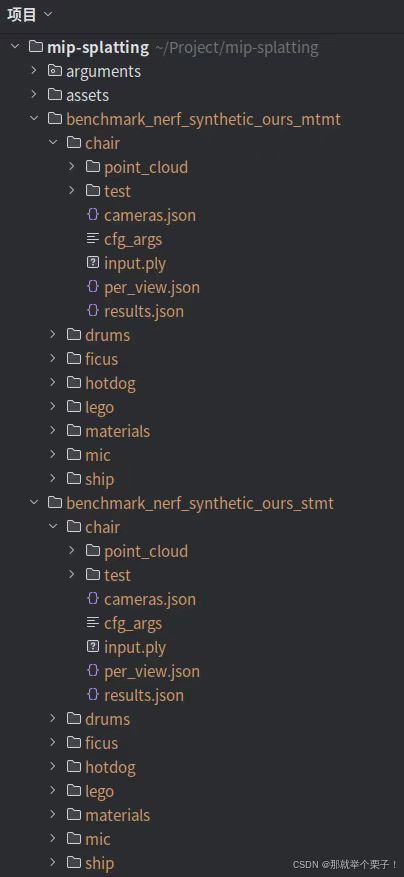
6.1 运行 NeRF 合成数据集(单尺度+多尺度训练):
# single-scale training and multi-scale testing on NeRF-synthetic dataset
python scripts/run_nerf_synthetic_stmt.py
# multi-scale training and multi-scale testing on NeRF-synthetic dataset
python scripts/run_nerf_synthetic_mtmt.py
训练结束后会分别生成单多尺度训练文件夹,如下图所示
七、在线查看
训练后,可以将 3D 平滑滤波器与高斯参数融合在一起
python create_fused_ply.py -m {model_dir}/{scene} --output_ply fused/{scene}_fused.ply"
## 在这里我们使用了如下代码
python create_fused_ply.py -m multi-scale/chair --output_ply fused/chair_fused.ply
会在fused目录下生成chair_fused.ply文件
然后可以使用的在线3D查看器来可视化经过训练的模型

八、自制数据集训练【使用自制图片数据集】
8.1 准备自己的图片
(1)拍摄场景的多视角图片:
- 拍摄 20-100 张照片,从不同角度覆盖整个场景
- 保持适当的重叠度(相邻图片有约 60-70% 的重叠)
- 避免运动模糊和光照变化
- 使用高质量相机,保持固定焦距
(2)创建数据目录结构:
# 创建目录来存放图片
mkdir -p data/3dgsdata/1/input
# 将您的图片复制到这个目录
cp /path/to/your/photos/*.jpg data/3dgsdata/1/input
8.2 使用 COLMAP 进行结构化数据处理
MIP-Splatting 需要使用 COLMAP 生成的相机参数和稀疏点云。以下是完整步骤:
(1) 安装 COLMAP
#安装依赖
sudo apt-get install git cmake ninja-build build-essential libboost-program-options-dev libboost-filesystem-dev libboost-graph-dev libboost-system-dev libeigen3-dev libflann-dev libfreeimage-dev libmetis-dev libgoogle-glog-dev libgtest-dev libsqlite3-dev libglew-dev qtbase5-dev libqt5opengl5-dev libcgal-dev libceres-dev
# 下载colmap
git clone https://github.com/colmap/colmap.git
#进入文件夹
cd colmap
git checkout 3.7
#创建并进入build文件夹
mkdir build
cd build
#构建安装
cmake .. -GNinja #CMake预处理,生成Ninja构建系统所需的文件
ninja #默认使用系统最大可用cpu核心数进行编译,如果系统cpu有32个核,等效与ninja -j32
sudo ninja install
(2)运行 COLMAP 处理
MIP-Splatting 提供了一个脚本来自动运行 COLMAP 并准备数据格式:
# 返回到 mip-splatting 目录
cd /path/to/mip-splatting
# 运行 COLMAP 数据处理脚本,为相机参数创建必要的文件
python convert.py -s data/3dgsdata/1 --resize
# 参数说明:
# --s: 指定包含图片的数据目录
# --resize: 使用标志时,创建图像的缩小版本(50%、25%、12.5%)
这个脚本会:
- 运行 COLMAP 的特征提取和匹配
- 执行增量式重建
- 转换 COLMAP 输出为 MIP-Splatting 所需的格式
- 生成训练/测试分割
生成的文件夹目录如图所示
/path/to/your/images/
/input # Your original images
/images # Original size images processed by COLMAP
/images_2 # 50% scaled images
/images_4 # 25% scaled images
/images_8 # 12.5% scaled images
/sparse # Camera parameters
8.3 训练模型
1、单尺度训练(STMT)
python train.py -s data/3dgsdata/1 -m output/1 --eval --kernel_size 0.1
## 参数意义
-s data/3dgsdata/1 设置输入数据路径。该目录应包含 images/ 和转换后的 transforms_train.json
-m output/1 设置模型输出路径。训练中会将 checkpoint 和日志保存到该路径下
--eval 每隔一段迭代自动执行一次测试(调用 render()),生成结果图像和指标,如果不添加此参数,后续无法计算指标
--kernel_size 0.1 控制初始高斯点的半径,影响点的体积。值越大表示点云分布越粗,越小越精细。推荐值 0.03~0.1
2、多尺度训练
python train.py -s data/3dgsdata/1 -m output/1 --eval --load_allres --sample_more_highres --kernel_size 0.1
## 参数意义
-s data/3dgsdata/1 设置输入数据路径。该目录应包含 images/ 和转换后的 transforms_train.json
-m output/1 设置模型输出路径。训练中会将 checkpoint 和日志保存到该路径下
--eval 每隔一段迭代自动执行一次测试(调用 render()),生成结果图像和指标,如果不添加此参数,后续无法计算指标
##额外多的参数
--load_allres 加载多分辨率图像(如 images_2, images_4,这些来自 convert.py --resize)
--sample_more_highres 在训练采样中优先选择更高分辨率的图像,以增强高精细区域的学习效果
--kernel_size 0.1 控制初始高斯点的半径,影响点的体积。值越大表示点云分布越粗,越小越精细。推荐值 0.03~0.1
3、训练效果对比
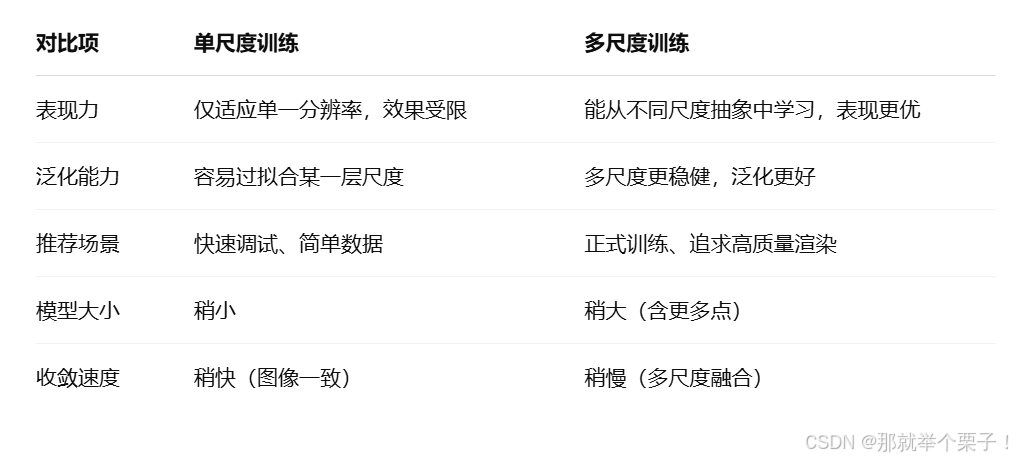
为了更大发挥模型性能,此处采用了多尺度训练方式,如下图所示:


Training progress: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30000/30000 [14:50<00:00, 33.69it/s, Loss=0.0067375]
[ITER 30000] Evaluating test: L1 0.005026974682030933 PSNR 33.37032018389021 [14/04 19:31:06]
[ITER 30000] Evaluating train: L1 0.003797494899481535 PSNR 37.59125595092774 [14/04 19:31:06]
[ITER 30000] Saving Gaussians [14/04 19:31:06]
Training complete. [14/04 19:31:07]
real 15m2.915s
user 15m6.362s
sys 0m17.852s
8.4 模型渲染
# 渲染新视角,生成模型输出图像
python render.py -m output/1 --skip_train
## 参数介绍
python render.py 执行渲染脚本。该脚本读取测试数据 + 已训练模型,输出渲染结果图像
-m output/1 指定模型路径
--skip_train 表示跳过训练集图像的渲染,仅对测试集进行渲染(节省时间和显存)
no --skip_train 对训练集和测试及都会进行渲染
## 代码作用
使用路径 output/1 下保存的模型,执行测试图像的渲染过程,生成预测图像(test_preds)和对应的 GT(ground truth)对齐图像,用于后续评估(如 SSIM、PSNR、LPIPS)
会在 output/1/ 中生成如下内容:
output/1/
├── config.yml ← 模型配置文件
├── checkpoint_30000.pth ← 最终模型权重
└── test/
└── ours_30000/
├── test_preds_1/ ← 渲染预测图像
└── gt_1/ ← 对齐 ground truth 图像(真实图)
输出图像格式说明
每个测试视角图像(如 00001.png, 00002.png)会保存两份:
output/1/test/ours_30000/
├── test_preds_1/ ← 模型预测图像
├── gt_1/ ← 对齐的 Ground Truth 图像
这些将被 metrics.py 用于计算 SSIM / PSNR / LPIPS 等指标
运行代码如下图所示:

8.5 评估模型
# 指标评估
python metrics.py -m output/1
## 参数介绍
-m output/1 指定模型路径
## 可选参数
-r 或 --resolution 默认-1 设置用于评估的分辨率等级:1 表示使用 images;2 表示 images_2;依此类推。-1 为自动匹配 默认优先选 test_preds_1/(即分辨率等级为 1 的图像),会自动查找 ours_30000/ 目录下的 test_preds_* 子文件夹,所以评估的是原始图像分辨率下的结果,对应模型训练时 d0
## 代码作用
使用 output/1 中的测试结果图像(test_preds 与 gt),计算图像质量评估指标:SSIM、PSNR、LPIPS。
这是最终量化模型好坏的关键步骤,常用于论文报告与模型对比。
metrics.py 的工作流程
执行这条命令后会依次完成以下步骤:
(1)加载预测图与 GT 图:
-
从 output/1/test/ours_30000/test_preds_1/ 中读取预测图像
-
从 output/1/test/ours_30000/gt_1/ 中读取对应的 GT 图像
-
每对图像都会被读取为 tensor 并送入指标计算器
(2)计算三种指标:
-
SSIM(结构相似度)
-
PSNR(峰值信噪比)
-
LPIPS(感知图像距离,加载 VGG 特征网络)
各个指标含义详解

输出结果(控制台 + 文件):
-
控制台输出:

Scene: output/1
Method: ours_30000
Metric evaluation progress: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:00<00:00, 11.17it/s]
SSIM : 0.9742036
PSNR : 33.3556633
LPIPS: 0.0743872 -
保存文件:
output/1/results.json:总体指标
output/1/per_view.json:每张图像的指标值
8.6 后处理
(1)创建包含 3D 平滑参数的融合 PLY 文件:

2)使用在线查看器以交互方式浏览您的场景:
- 将融合 PLY 上传到 [Mip-Splatting 在线查看器]
- 或者,如果已设置查看器,则在本地查看