大家好,OpenAI最新推出的GPT-4o,标志着人工智能语言模型和交互方式迈入了新纪元。最引人注目的是,GPT-4o支持实时互动和流畅的对话切换,让交流更加自然。
本文将对比分析GPT-4o、GPT 4以及谷歌的Gemini和Unicorn模型,分析是基于一个独立创建的英文数据集,对这些模型在分类任务上的表现进行深入比较。
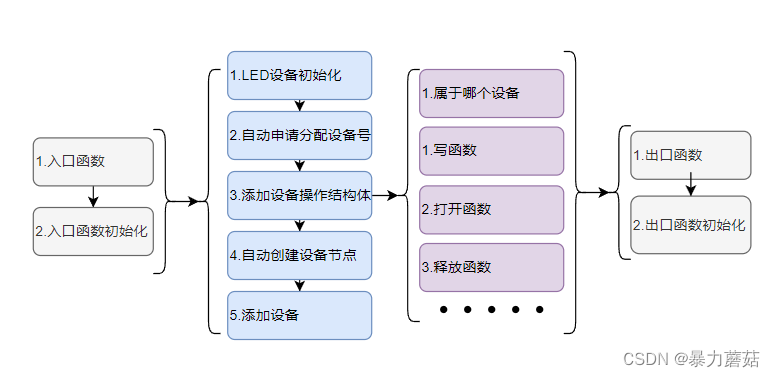
1.GPT-4o新功能
OpenAI最新提出的全知模型理念,旨在实现对文本、音频和视频的无缝理解和处理,标志着人工智能领域的新突破。
OpenAI似乎已经把重心放在了普及GPT-4级别的智能技术上,让免费用户同样能够体验到高端的语言模型智能。这一行动有望推进AI技术的普及化,让更多人受益于先进的AI技术。
OpenAI 还宣布,GPT-4o包括50多种语言的增强质量和速度,承诺将以更亲民的价格,为全球用户提供一个更包容、更易访问的AI体验。
对于付费用户,OpenAI将提供是非付费用户五倍的容量,以满足不同用户的需求。
此外,他们还将发布桌面版 ChatGPT,以方便大众在音频、视觉和文本界面上进行实时推理。
2.如何使用GPT-4o API
新的GPT-4o模型遵循了OpenAI现有的聊天完成API,能够与旧版本相互兼容且易于使用。
from openai import OpenAI
OPENAI_API_KEY = "<your-api-key>"
def openai_chat_resolve(response: dict, strip_tokens = None) -> str:
if strip_tokens is None:
strip_tokens = []
if response and response.choices and len(response.choices) > 0:
content = response.choices[0].message.content.strip()
if content is not None or content != '':
if strip_tokens:
for token in strip_tokens:
content = content.replace(token, '')
return content
raise Exception(f'Cannot resolve response: {response}')
def openai_chat_request(prompt: str, model_name: str, temperature=0.0):
message = {'role': 'user', 'content': prompt}
client = OpenAI(api_key=OPENAI_API_KEY)
return client.chat.completions.create(
model=model_name,
messages=[message],
temperature=temperature,
)
response = openai_chat_request(prompt="Hello!", model_name="gpt-4o-2024-05-13")
answer = openai_chat_resolve(response)
print(answer)
GPT-4o也可以通过ChatGPT界面使用:
3.官方测评
OpenAI的博客文章包括了诸如MMLU和HumanEval等知名数据集的测评分数。

从图表中可以看出,GPT-4o的性能达到了这一领域的最前沿水平。考虑到新模型在成本和速度上的优势,这一成绩无疑令人充满期待。
然而在过去一年内,市场上出现了多款模型,它们在已知数据集上声称具有领先的语言表现。值得注意的是,部分模型可能在这些公开数据集上进行了过度训练,导致其在排行榜上的高分可能并不能完全反映实际应用中的表现。
因此,对这些模型在鲜为人知的数据集上进行性能分析非常重要。使用特定创建的数据集进行评估,可以提供更加客观和全面的视角。
4.数据集
为了衡量不同大型语言模型(LLMs)的分类性能,开发了一个主题数据集。该数据集包含200个句子,分布在50个主题之下。设计时特意使一些主题紧密相关,以增加分类任务的难度。
整个数据集的英文版本是通过手动创建和标记完成的。之后,利用GPT4(gpt-4–0613)将数据集翻译成多种语言,以扩展其应用范围。
在本次评估中,仅对数据集的英文版本进行了测试。这种选择确保了评估过程的公正性,避免了因使用同一语言模型进行数据集创建和主题预测可能引入的偏见。
5.性能结果
对以下模型进行评测:
-
GPT-4o: gpt-4o-2024-05-13
-
GPT-4: gpt-4-0613
-
GPT-4-Turbo: gpt-4-turbo-2024-04-09
-
Gemini 1.5 Pro: gemini-1.5-pro-preview-0409
-
Gemini 1.0: gemini-1.0-pro-002
-
Palm 2 Unicorn: text-unicorn@001
给语言模型的任务是将数据集中的每个句子准确匹配到相应的主题。
通过这一过程,可以计算每种语言模型的准确率以及错误率。由于模型们大多数情况下都能正确分类,因此我们专注于绘制每个模型的错误率。
错误率越低,意味着模型的性能越好。
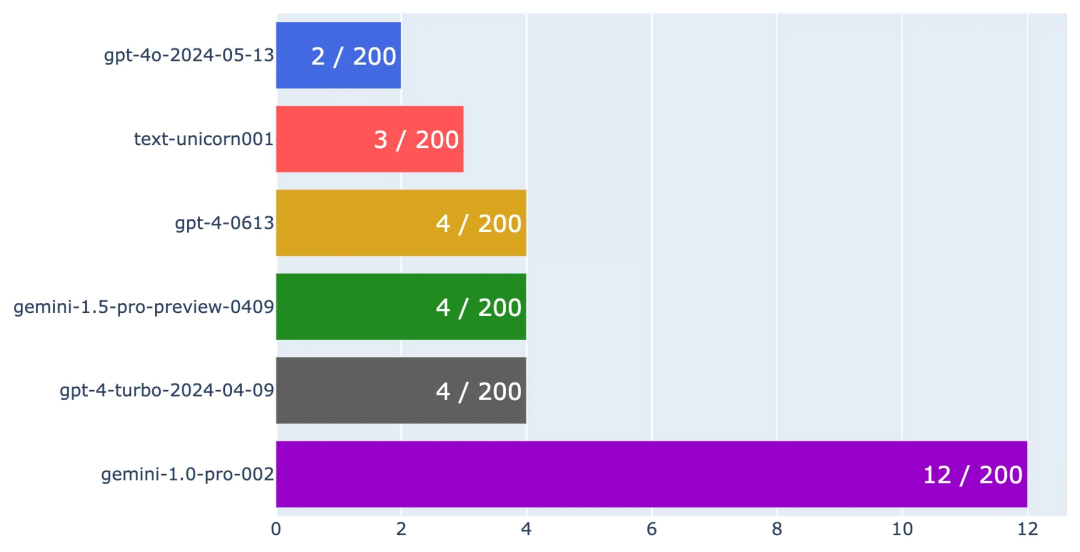
不同LLMs错误率的横向柱状图
从图表中可以明显看出,GPT-4o在所有模型中具有最低的错误率,仅出现了2次错误。还可以看到,Palm 2 Unicorn、GPT-4和Gemini 1.5的错误率与GPT-4o非常接近,表明它们也具有出色的性能。
此外,GPT-4 Turbo的表现与GPT-4–0613相似,这可能与它们的设计和优化有关。有兴趣的读者可以访问OpenAI的模型页面(https://platform.openai.com/docs/models),获取更多关于这些模型的详细信息。
Gemini 1.0的表现稍显逊色,但考虑到其定位和价格范围,这一结果在预料之中。



![【CTF Web】NSSCTF 3868 [LitCTF 2023]这是什么?SQL !注一下 !Writeup(SQL注入+报错注入+括号闭合+DIOS)](https://img-blog.csdnimg.cn/direct/71c8c6ac12a04c00be3b090839564565.png)