目录
- 第一章:熟悉Objective-C
- 第1条:了解Objective-C语言的起源
- 第2条:在类的头文件中尽量少引入其他头文件
- 第3条:多用字面量语法,少用与之等价的方法
- 第4条:多用类型常量,少用#define预处理指令
- 第5条:用枚举表示状态、选项、状态码
第一章:熟悉Objective-C
Objective-C在C语言基础上添加了面向对象特性,代码十分易读,但仍有许多微妙细节需要注意,而且还有许多容易为人所忽视的特性。
另一方面,有些开发者并未完全理解或是容易滥用某些特性,导致写出来的代码难于维护且不易调试。
第1条:了解Objective-C语言的起源
作为一种面向对象语言,若是用过其他面向对象语言,入门Objective-C(下面简称OC)更为容易。
Smalltalk:20世纪70年代出现的一种面向对象语言,是消息型语言的鼻祖。
OC由Smalltalk演化而来,使用“消息结构”(messaging structure)而非“函数调用”(function calling),是一门动态运行时语言。消息结构与函数调用之间的区别看上去就像这样:
// Messaging(Objective-C)
Object* obj = [Object new];
[obj performWith: parameter1 and: parameter2];
// Function calling(C++)
Object* obj = new Object;
obj->perform(parameter1, parameter2);
关键区别在于:
-
使用函数调用的语言(编译时语言),其运行时所应执行的代码由编译器决定。如果代码中调用的函数是多态的,那么在运行时就要按照“虚方法表”(virtual table)来查出到底应该执行那个函数实现。
virtual method table是编程语言为实现“动态派发”(dynamic dispatch)或“运行时方法绑定”(runtime method binding)而采用的一种机制
-
使用消息结构的语言(动态运行时语言),其运行时所应执行的代码由运行环境来决定;不论代码中调用的函数是否多态,总是在运行时才会去查找所要执行的方法。实际上,
编译器甚至不关心接收消息的对象是何种类型,接收消息的对象问题也要在运行时处理,其过程叫“动态绑定”(dynamic binding),确定一个对象类型后,进而去确定调用方法是所属于哪个类的过程,第11条会详述其细节。通过一个例子来理解动态运行时语言:
对于
NSString* string = [[NSMutableArray alloc] init];- 编译时:编译器进行类型检查的时候,由于给一个
NSString类型的指针赋值的是一个NSMutableArray对象,所以编译器会给出类型不匹配的警告。但是编译器会将string当作NSString的实例,所以string调用NSString的方法stringByAppendingString:,编译器无任何问题,而调用NSMutableArray的方法addObject:,编译器会直接报错。

- 运行时:由于
string实际指向的是一个NSMutableArray对象,NSMutableArray对象没有stringByAppendingString方法,所以会导致崩溃。

- 编译时:编译器进行类型检查的时候,由于给一个
OC的动态性都是由“运行期组件”(runtime component)而非编译器来实现的。使用OC的全部数据结构及函数都在运行期组件里面,比如全部内存管理方法等。
运行期组件本质上就是一种与开发者所编代码相链接的“动态库”(dynamic library),其代码能把开发者编写的所有程序粘合起来,所以只需更新运行期组件,即可提升应用程序性能。
而那种许多工作都在“编译期”(compile time)完成的语言,若想获得类似的性能提升,则要重新编译应用程序代码。
OC顾名思义,为面向对象的C语言,是C的“超集”(superset),所以OC兼容C语言,也就意味着OC也有编译时类型检查和错误提示等编译时语言的特性。OC的指针是用来指示对象的,想要声明一个变量,令其指代某个对象,可用如下语法:
NSString* someString = @"The string";
上面这行代码声明了一个名为someString、类型为NSString*的变量(即此变量为指向NSString的一个指针)。所有OC对象都必须这样声明,因为对象所占内存总是分配在“堆空间”(heap space)中,而绝不会分配在“栈”(stack)上。
不能在栈中分配OC对象:NSString stackString;。someString变量指向分配在堆里的某块内存,其中含有一个NSString对象。如果再创建一个变量,令其指向同一地址,那么并不拷贝该对象,只是这两个变量(指针)会同时指向该对象:
NSString* someString = @"The string";
NSString* anotherString = someString;
两个NSString*型的变量指向仅有的NSString实例,这说明“栈帧”(stack frame)里分配了两块内存,每块内存的大小都能容下一枚指针(在32位架构的计算机上是4字节,64位计算机上是8字节),这两块内存的值(指针指向)一样,都是NSString实例的地址。下图为此时的内存布局:
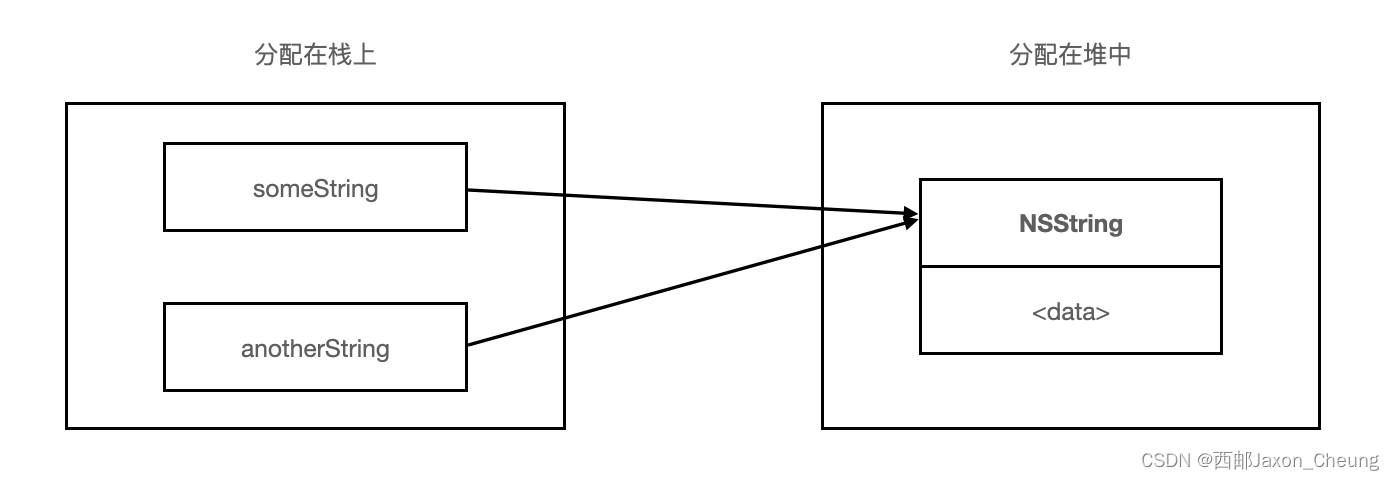
分配在堆中的内存必须直接管理,而分配在栈上用于保存变量的内存则会在其栈帧弹出时自动清理。
OC运行期环境把“需用malloc及free来分配或释放对象所占内存”等工作抽象为一套名叫“引用计数”的内存管理架构,但是需要注意的是真正实现分配和释放的操作是malloc和free,而非alloc和dealloc。
与创建结构体相比,创建对象还需要额外开销,例如分配及释放堆内存等,性能会受影响。若只需保存int、float、double、char等“非对象类型”(nonobject type),那么通常使用CoreGraphics框架中的CGRect这种结构体就可以了:
// C风格结构体
struct CGRect {
CGPoint origin;
CGSize size;
};
typedef struct CGRect CGRect;
第2条:在类的头文件中尽量少引入其他头文件
OC编写“类”的标准方式为:以类名做文件名,分别创建头文件(.h)和实现文件(.m)两个文件。
OC编写任何类几乎都需要引入Foundation.h,如果不在该类本身引入这个文件的话,那么就要与其超类所属框架相对应的“基本头文件”(base header file)。例如在创建iOS应用程序时,通常会继承UIViewController类,这些子类的头文件需要引入UIKit.h。
超类:类的父类,也就是被继承的类。
基类:位于继承层次结构的最顶层的类是其他类的父类,但它自身不继承任何其他类,也被称为根类。
在类的头文件中尽量少引入其他头文件,将引入头文件的时机尽量延后,只在确有需要时才引入,这样可以:
- 缩减编译时间,减少类的使用者所实际引入的头文件数量。假设把
Aaa.h引入到Bbb.h之后,那么只要在其他类头文件中引入Bbb.h,就会一并引入Aaa.h的所有内容,此过程若持续下去,则要引入许多根本用不到的内容,这当然会增加编译时间。 - 避免因在两个类在头文件中相互引用而导致其中一个类无法编译的问题。如果两个类在各自头文件中引入对方的头文件,则会导致循环引用(chicken-and-egg situation)。使用
#import而非#include指令虽然不会导致死循环,但是会让其中一个类无法被编译Cannot find interface declaration for 'Class'。#include可能会因为多次引用造成重复定义的问题, 使用#import保证每个头文件只会被引用一次 - 降低彼此依赖程度,降低类之间的耦合,避免因依赖关系太复杂而导致维护困难的问题。
将引入头文件的时机延后,非必要情况下,在.h文件中使用@class来向前声明(forward declaring)某个类,只需知道有一个这样的类就好;在需要知道该类所有接口细节的.m文件中使用#import Xxx.h:
@class AClass
有时必须要在.h中引入其他文件:
- 继承,子类的头文件中必须引入定义其父类的头文件。
- 遵从某个协议,使用
@protocol向前声明只能告诉编译器有某个协议,而此时编译器却要知道该协议中定义的方法和属性:
— 1. 这是难免的,鉴于此,最好是把协议单独放在一个头文件中。如果将协议放在了某个比较大的头文件里,那么只要#import此协议,就必定会引入那个头文件中的全部内容,这样也就增加了编译时间,甚至产生上面的相互引用问题。
— 2. 而“委托协议”(delegate protocol)就不用单独写一个头文件了,委托协议只有与接受协议委托的类放在一起才有意义。这种情况下,代理类应该将“该类遵从某协议”的这条声明转移至类扩展(参见🚩第27条),这样只要在.m中引入包含委托协议的头文件即可,而不需要放在.h中。
这样做不仅可以缩减编译时间,而且还能降低彼此依赖程度。若是依赖关系过于复杂,则会给维护带来麻烦,而且,如果只想把代码的某个部分开放为公共API的话,太复杂的依赖关系也会出现问题。
每次在头文件#import其他头文件之前,都要想想是否有必要。
第3条:多用字面量语法,少用与之等价的方法
一般情况下,是用alloc及init方法来分配并初始化对象的。
不过对于Foundation框架中NSString、NSNumber、NSArray、NSDictionary这几个表示数据结构的类,可以使用字面量语法(literal syntax)来声明实例,这样可以缩减源代码长度,使其更为易读。
NSString* someString = @"Effective Objective-C 2.0";
//NSNumber* someNumber = [NSNumber numberWithInt: 1];
NSNumber* someNumber = @1; //只包含数值,没有多余的语法成分
//NSArray* animals = [NSArray arrayWithObjects: @"cat", @"dog", @"mouse", @"badger", nil];
//NSString* dog = [animals objectAtIndex: 1];
NSArray* animals = @[@"cat", @"dog", @"mouse", @"badger"];
NSString* dog = animals[1]; //“取下标” 操作更为简洁,更易理解,与其他语言语法类似
//NSDictionary* personData = [NSDictionary dictionaryWithObjectsAndKeys: @"Matt", @"firstName", @"Galloway", @"lastName", [NSNumber numberWithInt: 28], @"age", nil];
//NSString* lastName = [personData objectForKey: @"lastName"];
NSDictionary* personData = @{@"firstName" : @"Matt", @"lastName" : @"Galloway", @"age" : @28};// <key> : <Value>,比使用方法创建的写法 <Value>, <key> 更易读
NSString* lastName = personData[@"lastName"];
NSMutableArray* mutableArray = animals.mutableCopy;
NSMutableDictionary* mutableDictionary = personData.mutableCopy;
//[mutableArray replaceObjectAtIndex: 1 withObject: @"dog"];
//[mutableDictionary setObject: @"Galloway" forKey: @"lastName"];
mutableArray[1] = @"dogee"; // 对于可变数组或字典,可以通过下标修改其中的元素值
mutableDictionary[@"lastName"] = @"Gallowayee";
字面量语法实际上只是一种语法糖(syntactic sugar),其效果等于是先创建了一个数据结构对象,然后把括号内的所有对象都加到这个数据结构中。
语法糖,也称“糖衣语法”,是指计算机语言中与另外一套语法等效但是开发者用起来却更加方便的语法。语法糖可令程序更易读,减少代码出错几率。
对于数组和字典来说,使用字面量语法更安全。如果数组中存在值为nil的对象,则会抛出异常。而如果使用arrayWithObjects:的话,数组元素个数会在你不知道的情况下减少,且难以排查该错误。
//NSArray* arrayA = [[NSArray alloc] initWithObjects: object1, object2, object3, nil];
//[arrayA release]; 此方式初始化需要手动管理内存(使用完数组后自行释放内存)
//此方法返回的数组对象已经被放入了自动释放池,无需手动管理内存
NSArray* arrayA = [NSArray arrayWithObjects: object1, object2, object3, nil]; //@[object1]
NSLog(@"%ld", [arrayA count]); //1
NSArray* arrayB = @[object1, object2, object3];
arrayWithObjects:方法会依次处理各个参数,直到发现nil为止,由于object2是nil,所以该方法会提前结束,数组个数也为1。
正如上面提到的,使用字面量方式创建数组实际上是先创建好数组,在把方括号内的对象依次加进去,也就是addObject:,使用此方法往数组添加nil则会抛出异常,因此,如果使用字面量语法创建的数组数值元素对象中有nil也会抛出异常。

这个微妙的差别表明,使用字面量语法更为安全。抛出异常令应用程序终止执行忙着比创建好数组之后才发现元素个数少了要好。向数组中插入nil通常说明程序有错,而通过异常可以更快地发现这个错误。
与数组一样,用字面量语法创建字典,一旦有值为nil,便会抛出异常,有助于差错。dictionaryWithObjectsAndKeys:方法就会在首个nil之前停下,但不会报错。

字面量语法有个小小的局限性,除NSString外,如果是自定义的Foundation框架中那些类的子类,则无法使用字面量语法创建其实例,必须采用非字面量语法。然而,由于NSNumber、NSArray、NSDictionary都是业已定型的“子族”(class cluster,参见🚩第9条),所以很少有人会从其中自定义子类。创建字符串时可以使用自定义的子类,然而必须要修改编译器的选项才行。
使用字面量语法创建出来的都是不可变对象,若想要可变对象则需要调用mutableCopy方法:
//NSMutableArray* mutableArray = [@[@1, @2, @3] mutableCopy];
NSMutableArray* mutableArray = @[@1, @2, @3].mutableCopy;
这么做会多调用一个方法,而且还要再创建一个对象,不过使用字面量语法所带来的好处还是多于上述缺点的。
第4条:多用类型常量,少用#define预处理指令
定义常量使用类型常量,不建议使用预处理指令。
预处理指令:
#define ANIMATION_DURATION 0.3
预处理指令会把源代码中的ANIMATION_DURATION都替换为0.3,假设此命令声明在某个头文件中,那么所有引入此头文件的代码,其ANIMATION_DURATION在编译时都会被替换为0.3。
类型常量:
static const NSTimeInterval kAnimationDuration = 0.3
该常量kAnimationDuration包含类型信息(NSTimeInterval类型),static修饰符意味着该常量(静态变量)只定义在它的.m文件内可见(设置了其使用范围)且保证了其在整个程序运行期间保持存在不会被销毁,const修饰符意味着该常量不可修改。
预处理指令和类型常量的区别:
| 预处理指令 | 类型常量 | |
|---|---|---|
| 简单的文本替换 | ||
| 不包括类型信息 | 包括类型信息(可以清除描述常量的含义,有助于编写开发文档) | |
| 可被任意修改 | 不可被修改 | |
| 可以设置其使用范围 | ||
| 编译时刻 | 预编译 | 编译 |
| 编译检查 | 无 | 有 |
注意类型常量的命名:若常量局限于某 “编译单元”(translation unit,OC语境下通常指每个类的.m实现文件),则在命名前面加字母k,比如kAnimationDuration;若常量在类之外可见,定义成全局常量,则通常以类名作为前缀,比如EOCViewClassAnimationDuration(🚩第19条详解了命名习惯naming convention)。
常量不应该定义在头文件中,这样做等于声明了一个名叫kAnimationDuration的全局变量,此名称应该加上前缀,以表明其所属的类。
对于局部类型常量,一定要同时使用static和const来声明,这样编译器就不会创建符号,而是会像#define预处理指令一样,把所有遇到的变量都替换为常值:static const NSTimeInterval kAnimationDuration = 0.3。
如果试图修改由const修饰符所声明的变量,那么编译器就会报错。
如果不加static,则编译器就会为它创建一个 “外部符号”(external symbol)。此时若是另一个编译单元中也声明了同名变量,那么编译器就会抛出“重复定义符号”错误信息:

对于全局类型常量,需放在 “全局符号表”(global symbol table),以便可以在定义该常量的编译单元之外使用:
// In the header file
extern NSString* _Nullable const EOCStringConstant;
// In the implementation file
NSString* const EOCStringConstant = @"VALUE";
const位置不同则常量类型不同,以上例子表示EOCStringConstant是一个常量指针,且其值(指向的地址)不可变,即不会再指向另一个NSString对象,但仍可修改该指针所指向的字符串内容。如果将const写在NSString*前面,则表示EOCStringConstant是一个指向不可变NSString对象的指针,指针本身可以变化指向其他NSString对象,但是无法修改该指针指向的字符串内容。
extern关键字就是告诉编译器,在“全局符号表”将会有一个名叫EOCStringConstant的符号。也就是说,无需查看此常量的定义,也能允许代码使用此常量。因为它知道,当链接🔗成二进制文件后,肯定能找到这个常量。
全局常量必须要定义,且只能定义一次,通常定义在该常量.h文件对应的.m文件中。
编译器每收到一个编译单元.m,就会输出一份 “目标文件”(object file)。由实现文件生成目标文件时,编译器会在 “数据段”(data section)为字符串分配存储空间。链接器会把此目标文件与其他目标文件相链接,以生成最终的二进制文件。凡是用到EOCStringConstant这个全局符号的地方,链接器都能将其解析。
因为符号要放在全局符号表里,所以命名常量时需谨慎,为避免名称冲突,一般以定义所在的类名作为前缀。
第5条:用枚举表示状态、选项、状态码
系统框架中频繁用到枚举类型(enum,一系列常量)来表示状态机的状态、传递给方法的可组合选项以及状态码等值,且这些值都有着易懂的名称。
枚举是一种常量命名方式,某个对象所经历的各种状态就可以定义为一个简单的枚举集(enumeration set)。比如:
enum EOCConnectionState {
EOCConnectionStateDisconnected, // 0
EOCConnectionStateConnecting, // 1
EOCConnectionStateConnected, // 2
};
//声明变量
enum EOCConnectionState state = EOCConnectionStateConnecting;
简洁写法只需定义一个枚举类型别名,如下:
typedef enum EOCConnectionState EOCConnectionState;
//声明变量
EOCConnectionState state = EOCConnectionStateConnecting;
编译器会为枚举分配一个独有的编号,从0开始,每个枚举递增1。
可以不使用编译器所分配的序号,而是手动指定某个枚举成员所对应的值,接下来几个枚举的值都会在上一个的基础上递增1:
enum EOCConnectionState {
EOCConnectionStateDisconnected = 1,
EOCConnectionStateConnecting, // 2
EOCConnectionStateConnected, // 3
};
实现枚举所用的数据类型取决于编译器,不过其二进制位(bit)的个数必须能完全表示下枚举编号才行。比如以上枚举最大编号为3,所以使用1个字节(1个字节含有8个二进制位,所以至多能表示256,即2的八次方种枚举,编号为0~255的枚举变量)的char类型即可。
C++11标准修订了枚举的某些特性,有一项是:可以指明用何种“底层数据类型”(underlying type)来保存枚举类型的变量。这样做的好处是可以向前声明枚举变量,若不指定底层数据类型,编译器(声明的时候)就不清楚底层数据类型的大小(定义的时候才确定),所以在用到此枚举类型时,也就不知道究竟该给变量分配多少空间。

向前声明:在某个类、结构体、函数、变量等实体实际实现之前提供一个简单的声明,以便在引用该实体的地方编译通过。这种方式可以在不暴露实体详细信息的情况下,在需要的地方提前声明它们,从而避免循环依赖或加快编译速度等问题。
枚举可以定义选项,选项之间可以通过“按位或操作符”(bitwise OR operator)来彼此组合。
以iOS UIKit框架中的一个枚举类型为例: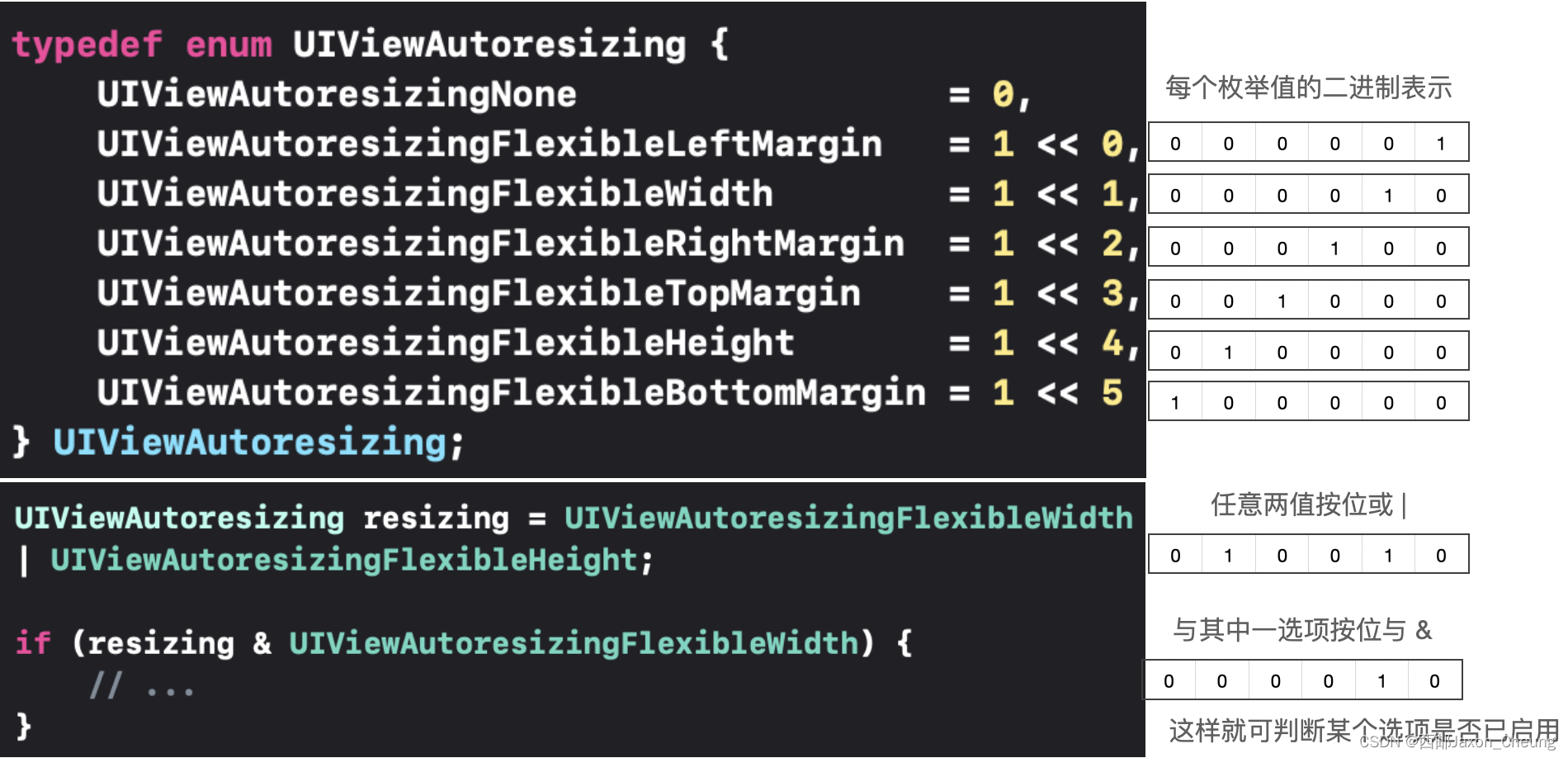
该枚举类型的选项组合起来用于表示某个视图应该如何在水平或垂直方向上调整大小。
Foundation框架中定义了一些关于枚举的辅助宏,可以指定用于保存枚举值的底层数据类型。
这些宏具备向后兼容(backward compatibility)能力 —— 如果目标平台的编译器支持新标准,那就使用新式语法,否则改用旧式。
这些宏使用#define预编译指令来定义的,其中一个用于定义“状态”枚举类型,另一个用于定义“选项”枚举类型。
typedef NS_ENUM(NSUInteger, EOCConnectionState) {
EOCConnectionStateDisconnected,
EOCConnectionStateConnecting,
EOCConnectionStateConnected,
};
typedef NS_OPTIONS(NSUInteger, EOCPermittedDirection) {
EOCPermittedDirectionUp = 1 << 0,
EOCPermittedDirectionDown = 1 << 1,
EOCPermittedDirectionLeft = 1 << 2,
EOCPermittedDirectionRight = 1 << 3
};
这些宏的定义如下:

由于需要分别处理不同情况,所以上述代码用多种方式来定义这两个宏。第一个#if用于判断编译器是否支持新式枚举。其中所用的布尔逻辑看上去相当复杂,不过其意思就是想判断编译器是否支持新的枚举特性,如果不支持,那么就用老式语法定义枚举。
如果支持新特性,那么用NS_ENUM宏所定义的枚举类型展开之后就是:
typedef enum EOCConnectionState : NSUInteger {
EOCConnectionStateDisconnected,
EOCConnectionStateConnecting,
EOCConnectionStateConnected,
};
NS_OPTIONS宏的定义方式在C++编译模式与非C++模式下有所不同:
在非C++模式下,其展开方式和NS_ENUM相同。
在C++模式(或Objective-C++编译模式)下,如果还按NS_ENUM展开就会编译错误。原因是,比如上例,C++认为按位或运操作两个枚举值时,运算结果的数据类型应该是枚举的底层数据类型,即NSUInteger,而C++不允许将这个底层类型“隐式转换”(implicit cast)成枚举类型本身EOCPermittedDirection。
编译错误提示:error:cannot initialize a variable of type ‘EOCPermittedDirection’ with an rvalue of type ‘NSUInteger’,如果想编译通过,就要将按位或操作的结果显式转换(explicit cast)为EOCPermittedDirection,所以在C++模式下应该用另一种方式定义NS_OPTIONS宏,以便省去类型转换操作。
鉴于此,凡是需要以按位或操作来组合的枚举都应使用NS_OPTIONS定义,因为它在C++和非C++模式下的#define是不一样的。若是枚举不需要互相组合,则应使用NS_ENUM来定义。
用辅助宏来定义枚举类型,并指明其底层数据类型。这样可以确保枚举使用开发者所选的底层数据类型实现出来的,而不会采用编译器所选的类型。
枚举还可用在switch中,
typedef NS_ENUM(NSUInteger, EOCConnectionState) {
EOCConnectionStateDisconnected,
EOCConnectionStateConnecting,
EOCConnectionStateConnected,
};
switch (_currentState) {
EOCConnectionStateDisconnected:
// Handle disconnected state
break;
EOCConnectionStateConnecting:
// Handle connecting state
break;
EOCConnectionStateConnected:
// Handle connected state
break;
}
在处理枚举类型的switch语句中不要加default分支。这样的话,如果我们新加了一种枚举类型,那么编译器就会给我们警告,提示新加的枚举类型没在switch中进行处理。而如果写上了default分支,那么它就会处理这个新状态,从而导致编译器不发出警告信息,就不能确保switch语句正确处理所有的枚举类型。