DCA(Decision Curve Analysis)临床决策曲线是一种用于评价诊断模型诊断准确性的方法,在2006年由AndrewVickers博士创建,我们通常判断一个疾病喜欢使用ROC曲线的AUC值来判定模型的准确性,但ROC曲线通常是通过特异度和敏感度来评价,实际临床中我们还应该考虑,假阳性和假阴性对病人带来的影响,因此在DCA曲线中引入了阈概率和净获益的概念。
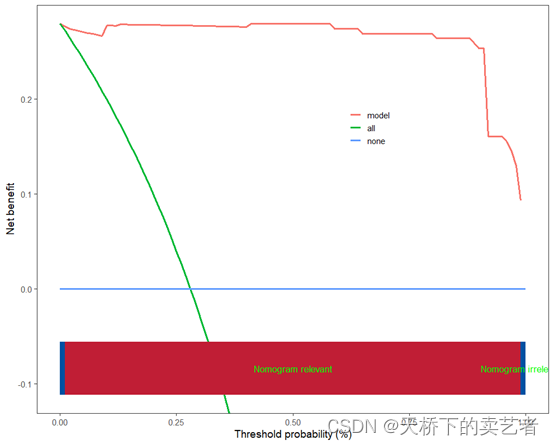
在新版的ggscidca包中,已经可以支持绘制支持向量机的决策曲线了,目前暂时支持kernlab包生成的支持向量机。e1071包的也是支持的,不过最新版本还没上传,下周上传后也是支持的。咱们使用下面代码安装ggscidca包,安装了旧版本的在安装一次就可以更新到新版本。
install.packages("ggscidca")
下面我来演示一下怎么使用ggscidca包进行支持向量机决策曲线绘制,先导入R包和数据
library("kernlab")
library(ggscidca)
bc<-read.csv("E:/r/test/demo.csv",sep=',',header=TRUE)
bc <- na.omit(bc)
names(bc)
做支持向量机最好不要有缺失值,不然容易有各种各样的问题
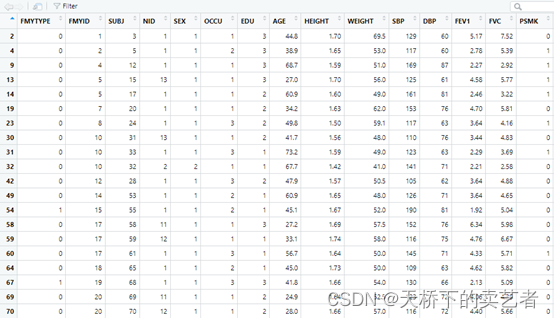
数据变量很多,我解释几个我等下要用的,HBP:是否发生高血压,结局指标,AGE:年龄,是我们的协变量,BMI肥胖指数,FEV1肺活量指标,WEIGHT体重,“SBP”,“DBP”:收缩压和舒张压。公众号回复:体检数据,可以获得数据。
有些变量用不到,我先精简一下,把结局变量变成因子,这个很重要。
bc<-bc[,c("HBP","BMI","AGE","FEV1","WEIGHT","SBP","DBP")]
bc$HBP<-as.factor(bc$HBP)
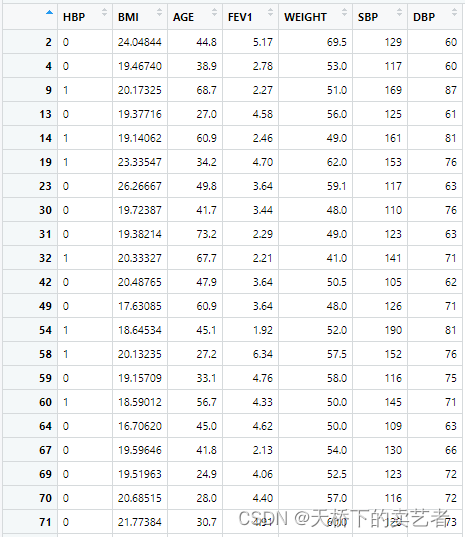
进行分析前还需对数据进行预处理,如果你是多分类的,并且数据差异大,可以使用分层抽样,尽量是数据匹配一下,方法详见我既往文章《R语言两种方法实现随机分层抽样》,我这里是二分类,我就不弄了。
接下来就是对数据进行标准化,这样可以消除数据见的差异。
定义一个标准化的小程序
f1<-function(x){
return((x-min(x)) / (max(x)-min(x)))
}
接下进行标准化,标准化不要放入结局变量
bc.scale<-as.data.frame(lapply(bc[2:7],f1))
把结局变量加入表转化后数据中,得到新的数据
bc.scale<-cbind(HBP=bc$HBP,bc.scale)
弄好数据之后咱们就可以进行分析了,先把数据分为建模组和验证组
#分成建模和验证组
set.seed(12345)
tr1<- sample(nrow(bc.scale),0.7*nrow(bc.scale))##随机无放抽取
bc_train <- bc.scale[tr1,]#70%数据集
bc_test<- bc.scale[-tr1,]#30%数据集
生成模型,要是调参的话也是在这一步进行,这里注意一下,参数prob.model=TRUE这个一定要有,不然没法做
fit <- ksvm(HBP~.,data=bc_train,type="C-bsvc",
kernel="rbfdot",C=10,prob.model=TRUE)
生成决策曲线,其实很简单就是一句话代码
scidca(fit,newdata =bc_train,legend.position=c(0.65,0.70))
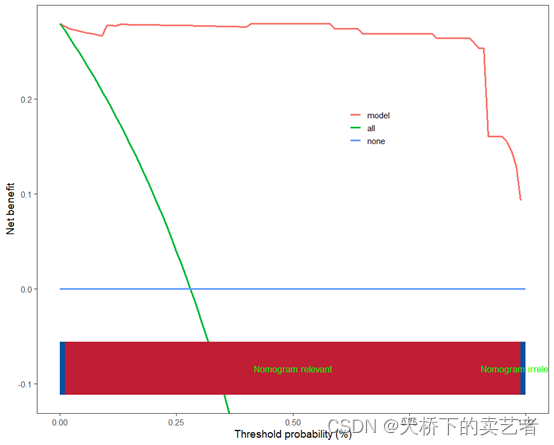
验证集的决策曲线,改个数据就行
scidca(fit,newdata =bc_test,legend.position=c(0.65,0.70))
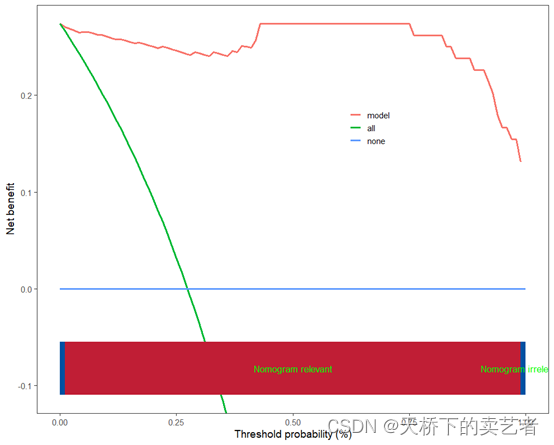
加上阈值
scidca(fit,newdata =bc_train,legend.position=c(0.65,0.70),threshold.line = T,threshold.text = T)
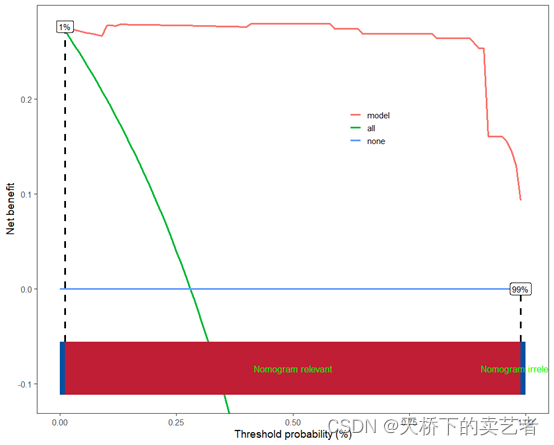
来个普通决策曲线也是可以的
scidca(fit,newdata =bc_train,legend.position=c(0.65,0.70),colbar = F)
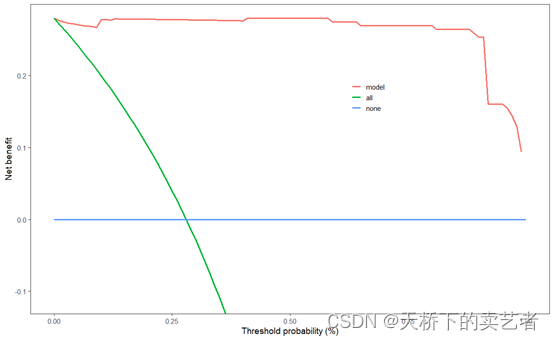
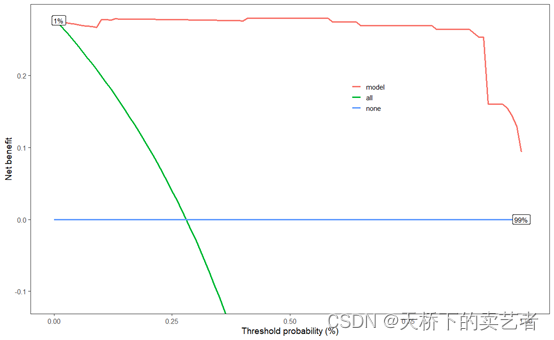
普通的决策曲线也是可以加阈值的
scidca(fit,newdata =bc_train,legend.position=c(0.65,0.70),colbar = F,threshold.text = T)
还有很多细节调整,这里就不介绍了,可以看我既往文章。
最后向大家汇报一下,多模型的决策曲线和混合模型的决策曲线已经写好,下周上传,到时我再出个视频介绍一下。