文章目录
- 2.6 synchronized和Lock有什么区别 ?
- 2.7 死锁产生的条件是什么?
- 2.8 如何进行死锁诊断?
- 2.10 ConcurrentHashMap
- (1) JDK1.7中concurrentHashMap
- (2) JDK1.8中concurrentHashMap
- 2.11 导致并发程序出现问题的根本原因是什么
- (1)原子性
- (3)内存可见性
- (3)有序性
2.6 synchronized和Lock有什么区别 ?
难易程度:☆☆☆☆
出现频率:☆☆☆☆
参考回答
- 语法层面
- synchronized 是关键字,源码在 jvm 中,用 c++ 语言实现
- Lock 是接口,源码由 jdk 提供,用 java 语言实现
- 使用 synchronized 时,退出同步代码块锁会自动释放,而使用 Lock 时,需要手动调用 unlock 方法释放锁
- 功能层面
- 二者均属于悲观锁、都具备基本的互斥、同步、锁重入功能
- Lock 提供了许多 synchronized 不具备的功能,例如获取等待状态、公平锁、可打断、可超时、多条件变量
- Lock 有适合不同场景的实现,如 ReentrantLock, ReentrantReadWriteLock
- 性能层面
- 在没有竞争时,synchronized 做了很多优化,如偏向锁、轻量级锁,性能不赖
- 在竞争激烈时,Lock 的实现通常会提供更好的性能
2.7 死锁产生的条件是什么?
难易程度:☆☆☆☆
出现频率:☆☆☆
死锁:一个线程需要同时获取多把锁,这时就容易发生死锁
例如:
t1 线程获得A对象锁,接下来想获取B对象的锁
t2 线程获得B对象锁,接下来想获取A对象的锁
代码如下:
package com.itheima.basic;
import static java.lang.Thread.sleep;
public class Deadlock {
public static void main(String[] args) {
Object A = new Object();
Object B = new Object();
Thread t1 = new Thread(() -> {
synchronized (A) {
System.out.println("lock A");
try {
sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
synchronized (B) {
System.out.println("lock B");
System.out.println("操作...");
}
}
}, "t1");
Thread t2 = new Thread(() -> {
synchronized (B) {
System.out.println("lock B");
try {
sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
synchronized (A) {
System.out.println("lock A");
System.out.println("操作...");
}
}
}, "t2");
t1.start();
t2.start();
}
}
控制台输出结果
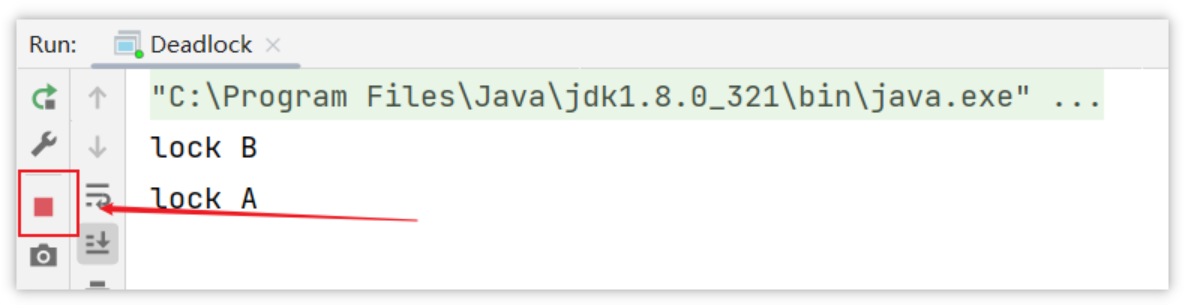
此时程序并没有结束,这种现象就是死锁现象…线程t1持有A的锁等待获取B锁,线程t2持有B的锁等待获取A的锁。
2.8 如何进行死锁诊断?
难易程度:☆☆☆
出现频率:☆☆☆
当程序出现了死锁现象,我们可以使用jdk自带的工具:jps和 jstack
步骤如下:
第一:查看运行的线程
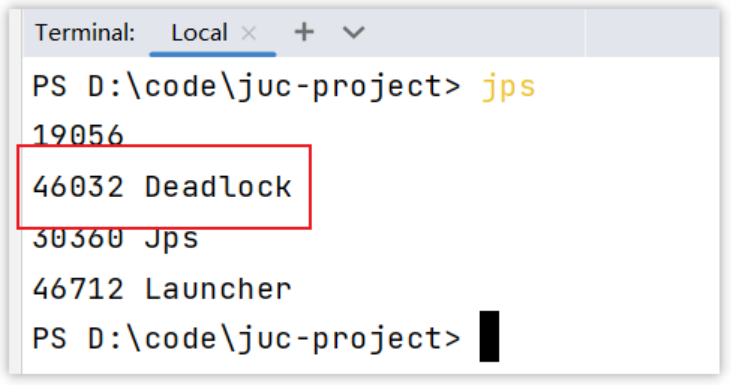
第二:使用jstack查看线程运行的情况,下图是截图的关键信息
运行命令:jstack -l 46032

其他解决工具,可视化工具
- jconsole
用于对jvm的内存,线程,类 的监控,是一个基于 jmx 的 GUI 性能监控工具
打开方式:java 安装目录 bin目录下 直接启动 jconsole.exe 就行
- VisualVM:故障处理工具
能够监控线程,内存情况,查看方法的CPU时间和内存中的对 象,已被GC的对象,反向查看分配的堆栈
打开方式:java 安装目录 bin目录下 直接启动 jvisualvm.exe就行
2.10 ConcurrentHashMap
难易程度:☆☆☆
出现频率:☆☆☆☆
ConcurrentHashMap 是一种线程安全的高效Map集合
底层数据结构:
-
JDK1.7底层采用分段的数组+链表实现
-
JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。
(1) JDK1.7中concurrentHashMap
数据结构
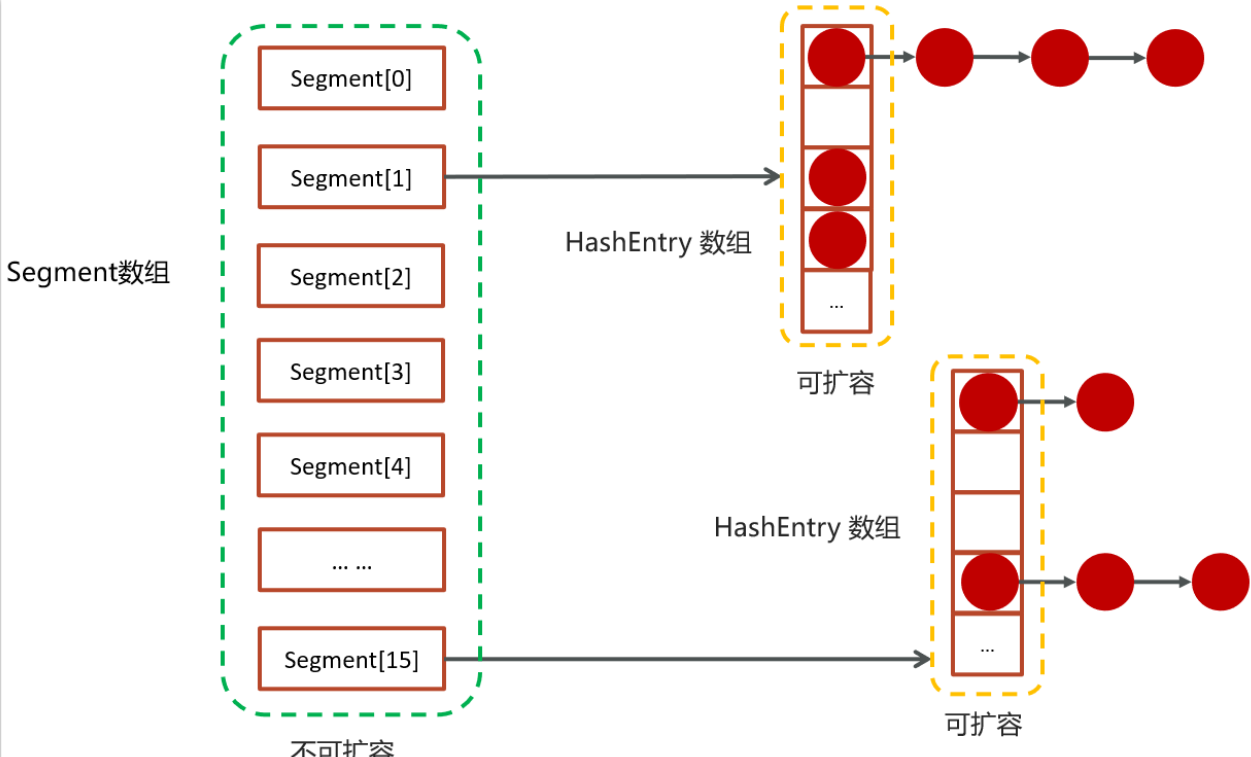
- 提供了一个segment数组,在初始化ConcurrentHashMap 的时候可以指定数组的长度,默认是16,一旦初始化之后中间不可扩容
- 在每个segment中都可以挂一个HashEntry数组,数组里面可以存储具体的元素,HashEntry数组是可以扩容的
- 在HashEntry存储的数组中存储的元素,如果发生冲突,则可以挂单向链表
存储流程
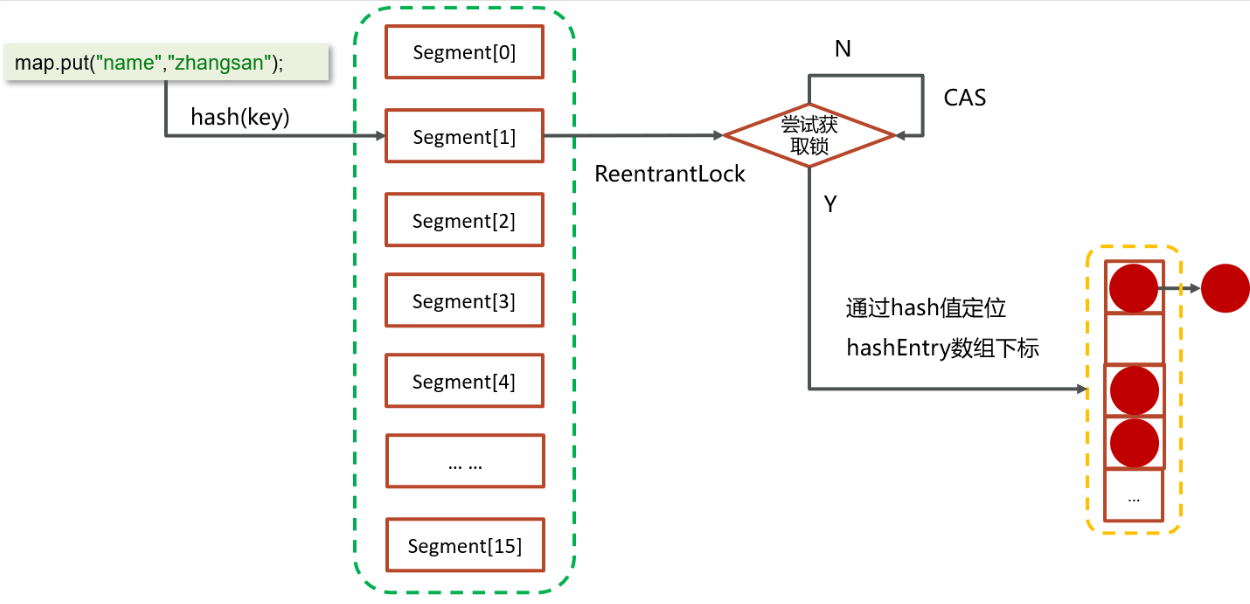
- 先去计算key的hash值,然后确定segment数组下标
- 再通过hash值确定hashEntry数组中的下标存储数据
- 在进行操作数据的之前,会先判断当前segment对应下标位置是否有线程进行操作,为了线程安全使用的是ReentrantLock进行加锁,如果获取锁是被会使用cas自旋锁进行尝试
(2) JDK1.8中concurrentHashMap
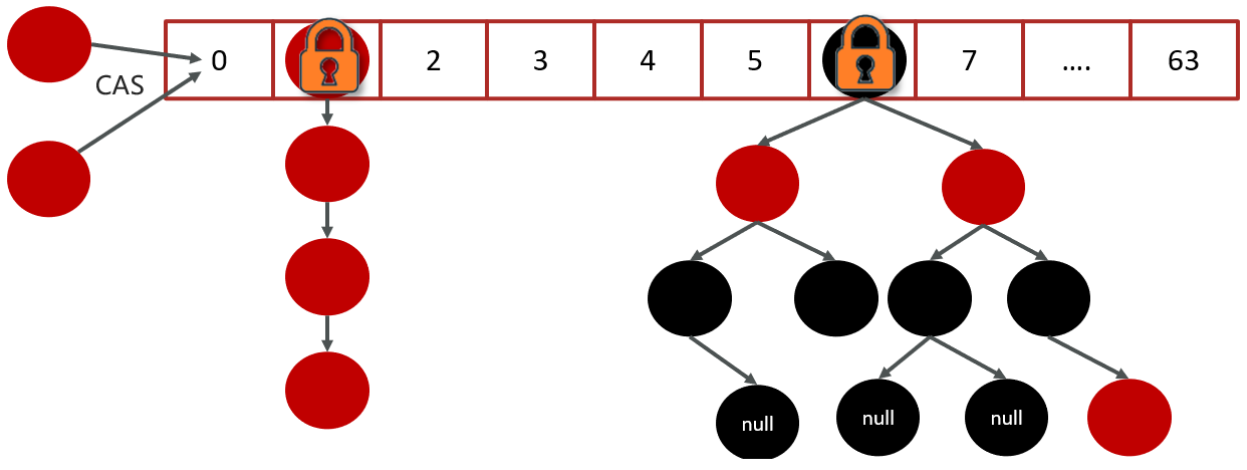
在JDK1.8中,放弃了Segment臃肿的设计,数据结构跟HashMap的数据结构是一样的:数组+红黑树+链表
采用 CAS + Synchronized来保证并发安全进行实现
-
CAS控制数组节点的添加
-
synchronized只锁定当前链表或红黑二叉树的首节点,只要hash不冲突,就不会产生并发的问题 , 效率得到提升
2.11 导致并发程序出现问题的根本原因是什么
难易程度:☆☆☆
出现频率:☆☆☆
Java并发编程三大特性
-
原子性
-
可见性
-
有序性
(1)原子性
一个线程在CPU中操作不可暂停,也不可中断,要不执行完成,要不不执行
比如,如下代码能保证原子性吗?

以上代码会出现超卖或者是一张票卖给同一个人,执行并不是原子性的
解决方案:
1.synchronized:同步加锁
2.JUC里面的lock:加锁

(3)内存可见性
内存可见性:让一个线程对共享变量的修改对另一个线程可见
比如,以下代码不能保证内存可见性

解决方案:
-
synchronized
-
volatile(推荐)
-
LOCK
(3)有序性
指令重排:处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的
还是之前的例子,如下代码:

解决方案:
- volatile