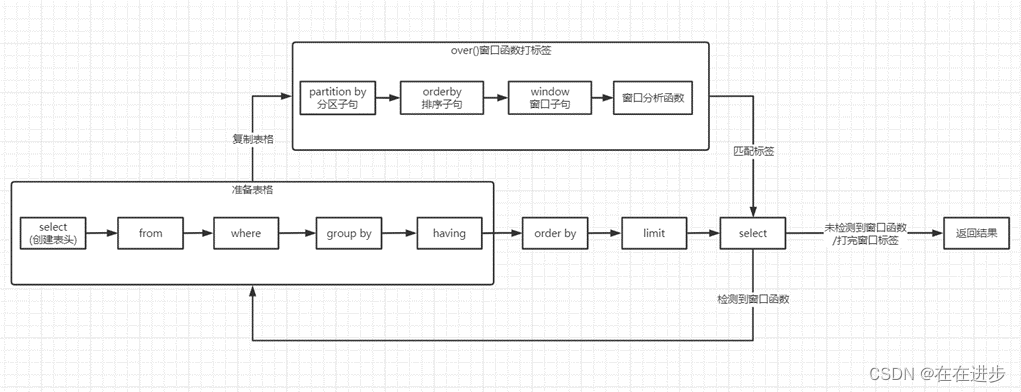
主知识点八:窗口函数
新开窗口,不影响原数据的排序。且子句必须有order by。窗口结果返回到
且窗口函数必须写在select后面!
● 【排序窗口函数】
● rank()over()——1,1,3,4
● dense_rank()over()——1,1,2,3
● row_number()over()——1,2,3,4
【例题29】查询每一年S14000021选区中所有候选人所在的团体(party)和得票数(votes),并对每一年中的所有候选人根据选票数的高低赋予名次,选票数最高则为1,第二名则为2,后续以此类推,最后根据团体(party)和年份(yr)排序。
分析:
(1)查询团体(party)和得票数(votes)
(2)每一年的,S14000021选区的
(3)每一年中的所有候选人根据选票数的高低赋予名次——窗口函数rank()over(partition by yr order by votes desc)
(4)根据团体(party)和年份(yr)排序。
代码:
select yr,party,votes,rank()over(partition by yr order by votes desc)as posn
from ge
where constituency='S14000021'
order by party,yr● 【偏移分析函数】
● lag(字段名,偏移量[,默认值])over()——当前行向上取值“偏移量”行
● lead(字段名,偏移量[,默认值])over()——当前行向下取值“偏移量”行
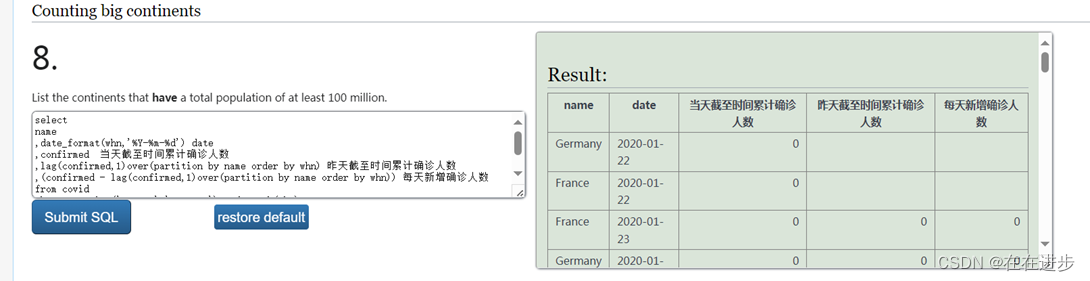
● 【例题30】查询法国和德国1月每天新增确诊人数,最后显示国家名、标准日期(2020-01-27)、当天截至时间累计确诊人数、昨天截至时间累计确诊人数、每天新增确诊人数,按照截至时间排序
分析:
(1)法国和德国1月每天新增确诊人数——where name in ('France','Germany') and month(whn) = 1
(2)最后显示国家名、标准日期(2020-01-27)、——date_format(whn,'%Y-%m-%d') date
当天截至时间累计确诊人数、——原表中的confirmed
昨天截至时间累计确诊人数、——,lag(confirmed,1)over(partition by name order by whn),当前行往上取1行,再取这一行的confirmed的值,
每天新增确诊人数
(3)按照截至时间排序
代码:
select
name
,date_format(whn,'%Y-%m-%d') date
,confirmed 当天截至时间累计确诊人数
,lag(confirmed,1)over(partition by name order by whn) 昨天截至时间累计确诊人数
,(confirmed - lag(confirmed,1)over(partition by name order by whn)) 每天新增确诊人数
from covid
where name in ('France','Germany') and month(whn) = 1
order by whn结果:
● 【总结】
● 【排序窗口函数语法】
● rank()over([partition by 字段名] order by 字段名 asc|desc)
● dense_rank()over([partition by 字段名] order by 字段名 asc|desc)
● row_number()over([partition by 字段名] order by 字段名 asc|desc)
● 【偏移分析函数语法】
● lag(字段名,偏移量[,默认值])over([partition by 字段名] order by 字段名 asc|desc)
● lead(字段名,偏移量[,默认值])over([partition by 字段名] order by 字段名 asc|desc)
● 【题目】查询2017年选区为 'S14000024' 的所有候选人所在团体(party)和其选票数(votes)、还有候选人得票数在选区内对应的的排名,结果按团队party排序。
分析:
(1)查询候选人所在团体(party)和其选票数(votes)、
还有候选人得票数在选区内对应的的排名,
(2)2017年选区为 'S14000024' 的 ——where yr=2017 and constituency='S14000024'
(3)结果按团队party排序——order by party
代码:
select party,votes,rank()over(partition by constituency order by votes desc)as sort
from ge
where yr=2017 and constituency='S14000024'
order by party
● 【题目】查询截至时间为2020年4月20日的国家名,确诊人数,确诊人数排名,死亡人数,死亡人数排名,按照确诊人数降序排名。
分析:
(1)查询国家名,确诊人数,确诊人数排名,死亡人数,死亡人数排名,
(2)截至时间为2020年4月20日的
(3)按照确诊人数降序排名。
代码:
select name,confirmed,
rank()over(order by confirmed desc) cr,
deaths,rank()over(order by deaths desc) dr
from covid
where whn='2020-4-20'
order by confirmed desc● 【题目】查询意大利每周新增确诊数(显示每周一的数值 weekday(whn) = 0),最后显示国家名,标准日期(2020-01-27),每周新增人数,按照截至时间排序。
分析:
(1)查询意大利每周新增确诊数——每周,两个相邻周一的数据相减就是这周的确诊数
(2)显示每周一的数值 weekday(whn) = 0,
(3)最后显示国家名,标准日期(2020-01-27),每周新增人数,
(4)按照截至时间排序。
代码:
select name,date_format(whn,'%Y-%m-%d') date,
(confirmed-lag(confirmed,1)over(partition by name order by whn))
from covid
where weekday(whn)=0 and name = 'Italy'
order by whn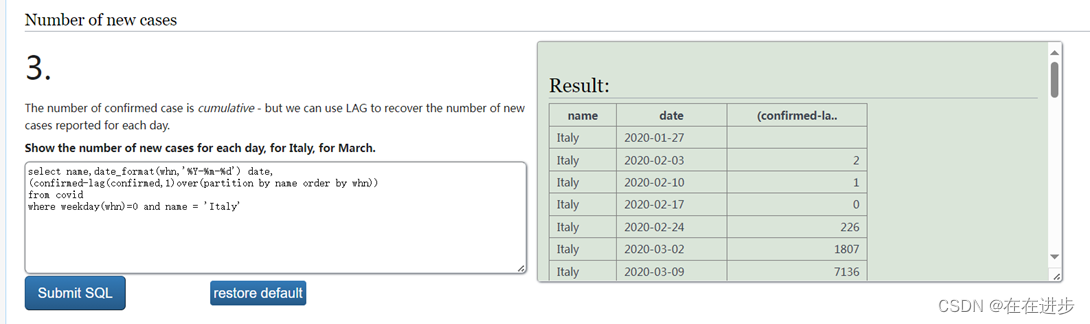
主知识点九:表链接
表链接:把表连接在一起(3种方式)
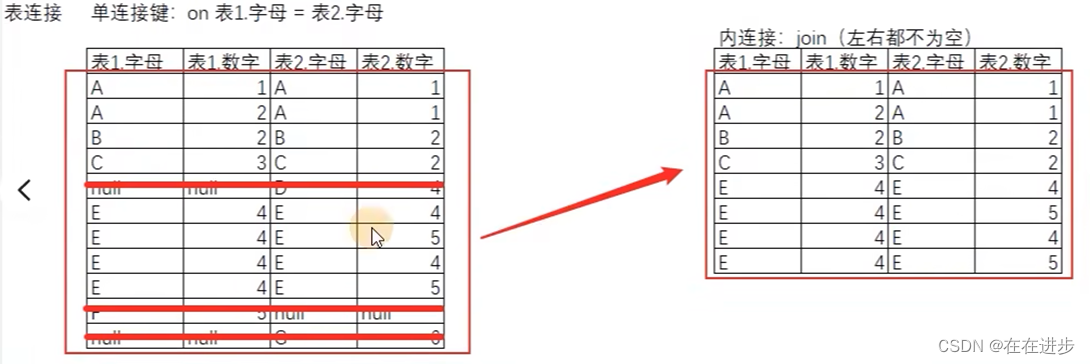
(1)内连接:只两个表保留相同的
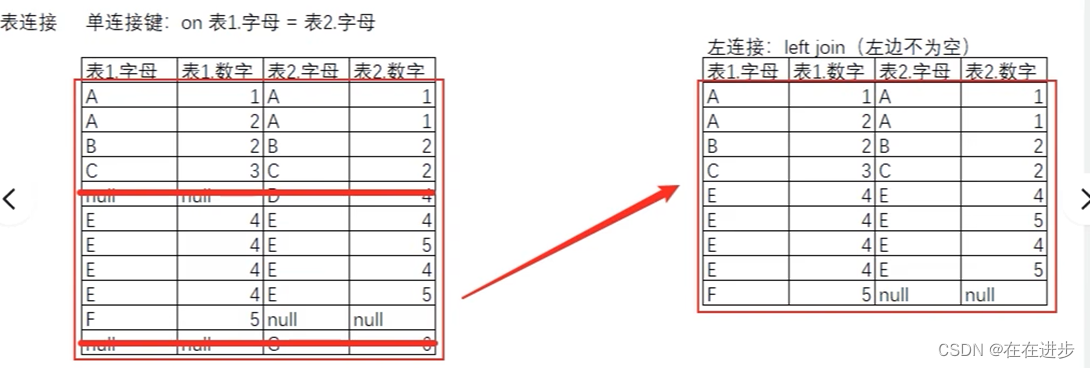
(2)左连接:合并后左边的表所有行都保留,若左边的表有空值则删除(即删除右边没有匹配上的)
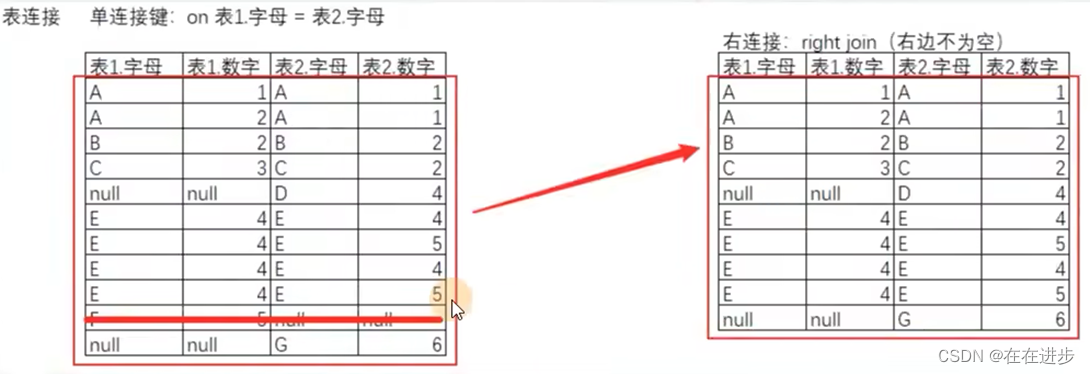
(3)右连接:与左相反
● 【基础语法】
● 内连接
select 字段名
from 表名1 inner join 表名2 on 表名1.字段名 = 表名2.字段名
注意内连接inner可以省略,直接使用join默认为内连接
● 左连接
select 字段名
from 表名1 left join 表名2 on 表名1.字段名 = 表名2.字段名
● 右连接
select 字段名
from 表名1 right join 表名2 on 表名1.字段名 = 表名2.字段名
● 【例题31】查询有球员名叫Mario进球的队伍1(team1),队伍2(team2)及球员姓名.
分析:球员表+比赛表
● 两表连接键分别为id列和matchid列,连接方式为内连接
● from game join goal on game.id = goal.matchid
代码:
SELECT player,team1,team2
FROM goal inner join game
on game.id = goal.matchid //不写on可能是完全连接
where player like '%Mario%'● 【例题32】查询队伍1(team1)的教练是“Fernando Santos”的球队名称(teamname)、比赛日期(mdate)和赛事编号(id)
分析:
要查询的是球队名称(teamname)、比赛日期(mdate)和赛事编号(id)
限制是队伍1(team1),and教练是“Fernando Santos”
代码:
连接键game.team1=eteam.id
SELECT teamname,mdate,game.id //有两个id要区分一下
FROM game join eteam
on game.team1=eteam.id //筛选队伍1中的教练
where coach='Fernando Santos'
● 【例题33】使用合适的连接显示所有教师及其所教授的科目名
分析:
是所有教师,则要左连接,否则有些老师会被清除,因为有些老师没有教课
代码:
select teacher.name,dept.name as dept
from teacher left join dept
on teacher.dept=dept.id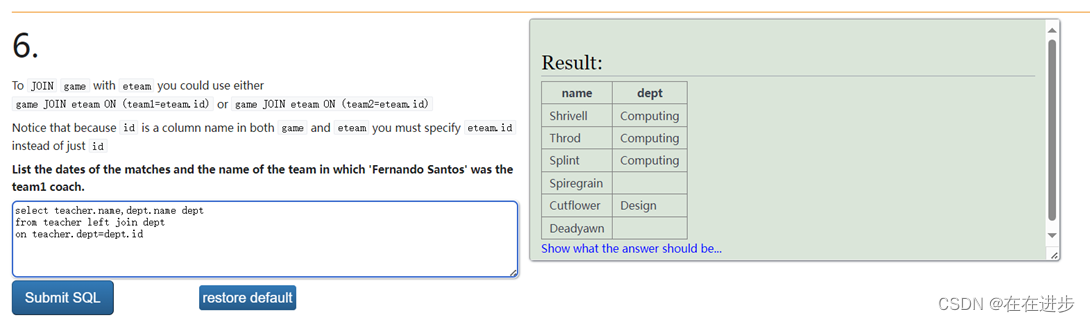
● 【题目1】查询至少出演过第1主角, 30次的演员名
代码:
SELECT name
FROM casting join actor
on casting.actorid=actor.id
where ord=1 //至少出演过第1主角
group by name // 查询的是演员,结果要以演员name 进行分组(group by)
having count(movieid)>=30 注意:group by字段名:规定依据哪个字段分组聚合,使用该子句是为了依据相同字段值分组后进行聚合运算,常和聚合函数联用
● 【题目2】查询在比赛前十分钟有进球记录的球员,他的队伍编号(teamid),教练(coach), 进球时间(gtime)
分析:
查询的是——队伍编号(teamid),教练(coach), 进球时间(gtime)
限制是——比赛前十分钟有进球记录的
代码:
SELECT teamid,coach,gtime
FROM eteam join goal
on eteam.id = goal.teamid //不一定是表第一列作为连接
where gtime<=10● 【题目3】查询每场比赛,每个球队的得分情况,按照以下格式显示。最后按照举办时间(mdate)、赛事编号(matchid)、队伍1(team1)和队伍2(team2)排序。

分析:
(1)得分表goal中出现的teamid就是得分队伍,即出现一次表示得分一次。
(2)每场比赛,每个球队——用group by按照场次、队伍分组
代码:
SELECT mdate,team1,sum(case when ga.team1=go.teamid then 1 else 0 end) score1,
team2,sum(case when ga.team2=go.teamid then 1 else 0 end) score2
FROM game ga
left join goal go
on ga.id = go.matchid
group by mdate,ga.team1,ga.team2
order by mdate,matchid,team1,score1,team2,score2主知识点十:子查询
套娃逻辑
1、【where基于子查询条件筛选(比较运算符&in关键字)】
● 【例题34】查询出gdp高于欧洲每个国家的所有国家名,有一些国家gdp值可能为NULL,请排除这些国家。
分析:
(1)gdp高于欧洲每个国家,即gdp高于欧洲gdp最大的国家
先查出这个GDP最大的国家,然后再大于这个国家就好了
(2)请排除国家gdp值可能为NULL——is not null
代码:
select name
from world
where gdp is not null
and gdp>
( //返回最大gdp给上面的判断
select max(gdp) from world where continent = 'Europe'
)2、【from基于子查询作为数据表】
● 【例题36】查询2017年所有在爱丁堡的选区当选议员所在选区(constituency)及其团队(party),已知爱丁堡选区编号为S14000021至S14000026,当选议员即各选区得票数最高的候选人。
分析:
(1)要查询:当选议员所在选区(constituency)及其团队(party)
(2)限制是:2017年,所有,在爱丁堡的(编号为S14000021至S14000026)
(3)当选议员:各选区得票数最高的候选人
代码1:
select yr,constituency,party,votes,
rank()over(partition by constituency order by votes desc) as pson
from ge
where yr = 2017
and constituency between 'S14000021' and 'S14000026'以上代码可以找到2017年在爱丁堡选区,和票数的排名

再from从上面这个【表】中把pson=1 的筛选出来就好了:先将表另存为,再where 表.pson=1.
select constituency,party
from
(
select yr,constituency,party,votes,
rank()over(partition by constituency order by votes desc) as pson
from ge
where yr = 2017
and constituency between 'S14000021' and 'S14000026'
)data
where data.pson=1● 【总结】
● 子查询本身是一个完整的查询,由括号包裹嵌套在主查询中
● 子查询最后返回查询出的结果给主查询
● 子查询可以在select,from,where,having子句(同where)中使用,但要注意不同子句能接受的子查询种类有差别
● 子查询可以多重嵌套(子查询可以作为主查询再嵌套子查询)