在pytorch中,tensor的实际数据以一维数组(storage)的形式存储于某个连续的内存中,以“行优先”进行存储。
1. tensor的连续性
tensor连续(contiguous)是指tensor的storage元素排列顺序与其按行优先时的元素排列顺序相同。如下图所示:
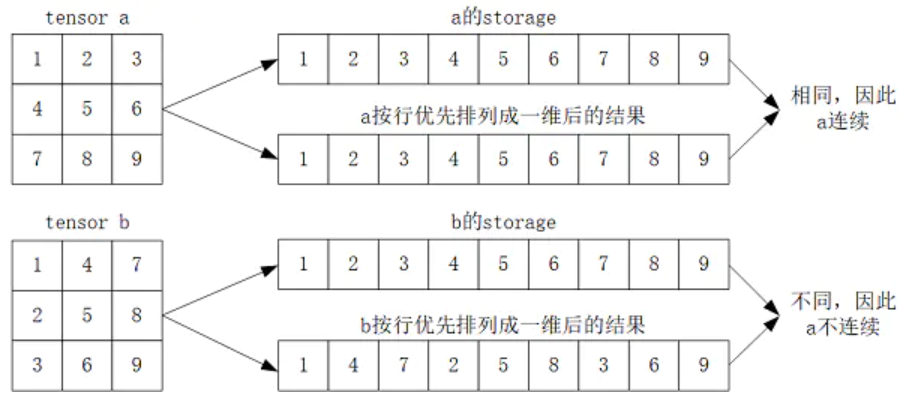
出现不连续现象,本质上是由于pytorch中不同tensor可能共用同一个storage导致的。
pytorch的很多操作都会导致tensor不连续,如tensor.transpose()(tensor.t())、tensor.narrow()、tensor.expand()。
以转置为例,因为转置操作前后共用同一个storage,但显然转置后的tensor按照行优先排列成1维后与原storage不同了,因此转置后结果属于不连续(见下例)。
2. tensor.is_contiguous()
tensor.is_contiguous()用于判断tensor是否连续,以转置为例说明:
>>>a = torch.tensor([[1,2,3],[4,5,6]])
>>>print(a)
tensor([[1, 2, 3],
[4, 5, 6]])
>>>print(a.storage())
1
2
3
4
5
6
[torch.LongStorage of size 6]
>>>print(a.is_contiguous()) #a是连续的
True
>>>b = a.t() #b是a的转置
>>>print(b)
tensor([[1, 4],
[2, 5],
[3, 6]])
>>>print(b.storage())
1
2
3
4
5
6
[torch.LongStorage of size 6]
>>>print(b.is_contiguous()) #b是不连续的
False
# 之所以出现b不连续,是因为转置操作前后是共用同一个storage的
>>>print(a.storage().data_ptr())
>>>print(b.storage().data_ptr())
2638924341056
26389243410563. tensor不连续的后果
tensor不连续会导致某些操作无法进行,比如view()就无法进行。在上面的例子中:由于 b 是不连续的,所以对其进行view()操作会报错;b.view(3,2)没报错,因为b本身的shape就是(3,2)。
>>>b.view(2,3)
RuntimeError Traceback (most recent call last)
>>>b.view(1,6)
RuntimeError Traceback (most recent call last)
>>>b.view(-1)
RuntimeError Traceback (most recent call last)
>>>b.view(3,2)
tensor([[1, 4],
[2, 5],
[3, 6]])4. tensor.contiguous()
tensor.contiguous()返回一个与原始tensor有相同元素的 “连续”tensor,如果原始tensor本身就是连续的,则返回原始tensor。
注意:tensor.contiguous()函数不会对原始数据做任何修改,他不仅返回一个新tensor,还为这个新tensor创建了一个新的storage,在这个storage上,该新的tensor是连续的。
继续使用上面的例子:
>>>c = b.contiguous()
# 形式上两者一样
>>>print(b)
>>>print(c)
tensor([[1, 4],
[2, 5],
[3, 6]])
tensor([[1, 4],
[2, 5],
[3, 6]])
# 显然storage已经不是同一个了
>>>print(b.storage())
>>>print(c.storage())
1
2
3
4
5
6
[torch.LongStorage of size 6]
1
4
2
5
3
6
[torch.LongStorage of size 6]
False
# b不连续,c是连续的
>>>print(b.is_contiguous())
False
>>>print(c.is_contiguous())
True
#此时执行c.view()不会出错
>>>c.view(2,3)
tensor([[1, 4, 2],
[5, 3, 6]])以上原文出自:tensor的连续性、tensor.is_contiguous()、tensor.contiguous() - 简书 (jianshu.com)
5. view()
类似于resize操作,基于前面所说的tensor连续存储,view()函数把原tensor中的数据按照行优先的顺序排成一个一维的数据,然后按照参数组合成其他维度的tensor。
举个例子:
a=torch.Tensor([[[1,2,3],[4,5,6]]])
b=torch.Tensor([1,2,3,4,5,6])
print(a.view(1,6))
print(b.view(1,6))
# 输出结果都是 tensor([[1, 2, 3, 4, 5, 6]]) 再如输出3维向量:
a=torch.Tensor([[[1,2,3],[4,5,6]]])
print(a.view(3,2))
#输出结果为:
#tensor([[1, 2],
# [3, 4],
# [5, 6]])6. nn.Sequential()
一个序列容器,用于搭建神经网络的模块被按照被传入构造器的顺序添加到nn.Sequential()容器中。除此之外,一个包含神经网络模块的OrderedDict也可以被传入nn.Sequential()容器中。利用nn.Sequential()搭建好模型架构,模型前向传播时调用forward()方法,模型接收的输入首先被传入nn.Sequential()包含的第一个网络模块中。然后,第一个网络模块的输出传入第二个网络模块作为输入,按照顺序依次计算并传播,直到nn.Sequential()里的最后一个模块输出结果。
即nn.Sequential()相当于把多个模块封装成一个模块。它与nn.ModuleList()不同,nn.ModuleList()只是存储网络模块的list,其中的网络模块之间没有连接关系和顺序关系
7.permute()
permute()函数将tensor的维度换位,相当于同时操作tensor的若干维度,与transpose()函数不同,transpose()只能同时作用于tensor的两个维度。
如:
>>>torch.randn(2,3,4,5).permute(3,2,0,1).shape
# 输出结果为torch.size([5,4,2,3])
# 上面的结果等价于:
>>>torch.randn(2,3,4,5).transpose(3,0).transpose(2,1).transpose(3,2).shape
# 输出结果为torch.size([5,4,2,3])









![[杂记]算法:前缀和与差分数组](https://img-blog.csdnimg.cn/6cc1aac1b545428f929eb0da1ba90050.png)