aiohttp 是一个基于 asyncio 的异步 HTTP 客户端/服务器库。它提供了一组用于编写高性能异步网络应用程序的工具,包括基于协程的客户端和服务器。
库的安装使用 pip install aiohttp
Python aiohttp 库
- 通过 aiohttp 搭建服务器
- aiohttp 路由
- aiohttp 中间件
- aiohttp 发送异步 HTTP 请求
- aiohttp 发送多个异步 HTTP 请求
通过 aiohttp 搭建服务器
掌握该库的入门案例就是搭建 aiohttp 服务器,示例代码如下:
from aiohttp import web
async def handle(request):
name = request.match_info.get('name', "dream_ca")
text = "你好, " + name
return web.Response(text=text)
app = web.Application()
app.add_routes([web.get('/{name}', handle)])
web.run_app(app)
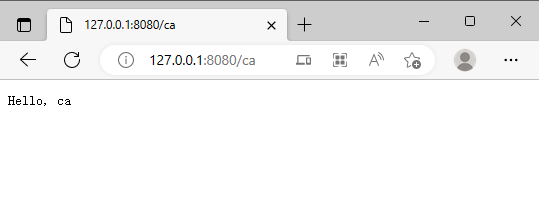
运行之后,该服务器会监听本地 8080 端口,然后访问 127.0.0.1:8080/ca 就可以得到下图所示内容。

继续扩展 aiohttp 库在服务器端的应用。
aiohttp 路由
aiohttp 提供了一个 WebApplication 类来处理路由,它具有一些方法来处理特定的 HTTP 方法,如 GET,POST 和 DELETE。下面是一个示例代码:
from aiohttp import web
# 创建一个处理GET请求的函数
async def handle_get(request):
name = request.match_info.get('name', "梦想橡皮擦")
text = "你好, " + name
return web.Response(text=text)
# 创建一个处理POST请求的函数
async def handle_post(request):
data = await request.json()
text = f"你好, {data['name']}"
return web.Response(text=text)
app = web.Application()
# 使用 app.router.add_get() 方法来处理GET请求
app.router.add_get('/{name}', handle_get)
# 使用 app.router.add_post() 方法来处理POST请求
app.router.add_post('/', handle_post)
web.run_app(app)
在上述代码中,使用 app.router.add_get() 方法来处理 GET 请求,并使用 app.router.add_post() 方法来处理 POST 请求。这两个方法都接受两个参数:一个是路由路径,另一个是处理该路由的函数。如果请求的 URL 匹配路由路径,aiohttp 将调用相应的处理程序来处理请求。
除此之外,request.match_info.get() 函数是 aiohttp 库中用来获取路由中变量部分的值的对象。它是一个字典类型,键是路由中变量的名称,值是请求 URL 中对应的值。
在路由中,变量部分通常用花括号 {} 来表示,如下所示:
app.router.add_get('/users/{user_id}', handle_get_user)
在上述代码中,路由是 '/users/{user_id}' ,其中 {user_id} 是一个变量。当请求 URL 为 '/users/666' 时,request.match_info 就会返回一个字典,其中包含一个键 'user_id' 和值 '666'。
你可以使用 match_info.get(name, default) 来获取路由中变量的值,其中 name 是变量的名称,default 是默认值。如果变量名称不存在,则返回默认值。
在 aiohttp 中还可以使用 app.add_routes() 一次性添加多个路由。
from aiohttp import web
async def handle_index(request):
return web.Response(text="index 页面")
async def handle_about(request):
return web.Response(text="about 页面")
async def handle_i(request):
return web.Response(text="i 页面")
app = web.Application()
app.add_routes([web.get('/', handle_index),
web.get('/about', handle_about),
web.post('/i', handle_i)])
web.run_app(app, host='127.0.0.1')
aiohttp 中间件
aiohttp 的中间件是一种组件,它可以在请求/响应处理过程中插入额外的逻辑。它可以在请求和响应之间插入额外的处理,并允许对请求和响应进行更改。
中间件的工作方式是:在请求到达应用程序之前先经过中间件的处理,再到达应用程序的处理函数,最后响应经过中间件的处理后返回给客户端。
请求->中间件->应用程序处理->中间件->响应
下面演示如何使用中间件添加响应计时功能,代码如下:
from aiohttp import web
import time
async def handle_index(request):
time.sleep(1)
return web.Response(text="index 页面")
async def handle_about(request):
time.sleep(5)
return web.Response(text="about 页面")
async def handle_i(request):
time.sleep(10)
return web.Response(text="i 页面")
# 定义一个中间件
async def timer_middleware(app, handler):
async def middleware_handler(request):
start_time = time.time()
response = await handler(request)
end_time = time.time()
print(f"请求响应时间: {end_time - start_time} ")
return response
return middleware_handler
app = web.Application()
# 使用中间件
app = web.Application(middlewares=[timer_middleware])
app.add_routes([web.get('/', handle_index),
web.get('/about', handle_about),
web.post('/i', handle_i)])
web.run_app(app, host='127.0.0.1')

上述代码我们定义了一个名为 timer_middleware 的中间件,它接受两个参数:app 和 handler。 app 是 aiohttp 的应用程序实例, handler 是要处理请求的函数。
中间件的逻辑是,在处理请求之前记录当前时间,然后调用传入的处理函数来处理请求,最后记录当前时间并计算请求处理时间。
最后,我们使用 app.middlewares 属性来添加中间件,这样就可以在请求处理之前和之后计算时间了。
中间件可以用于许多其他用途,如:
- 验证身份;
- 添加额外的请求头;
- 捕获和处理异常;
- 记录请求日志;
- 对响应进行处理;
aiohttp 发送异步 HTTP 请求
在爬虫领域使用 aiohttp 更多的是发送异步请求。
import aiohttp
import asyncio
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
async with aiohttp.ClientSession() as session:
html = await fetch(session, 'https://baidu.com')
print(html)
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
如果希望调用 aiohttp 库,还需要配合协程库 asyncio,该库的学习可以阅读橡皮擦的另一篇博客。
《Python 协程学习有点难度?这篇文字值得你去收藏》
aiohttp 发送多个异步 HTTP 请求
如果想要提高爬虫采集速度,可以搭配 asyncio.wait() 进行提速。
import aiohttp
import asyncio
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
async with aiohttp.ClientSession() as session:
tasks = []
tasks.append(asyncio.ensure_future(fetch(session, 'https://baidu.com')))
tasks.append(asyncio.ensure_future(fetch(session, 'https://sogou.com')))
tasks.append(asyncio.ensure_future(fetch(session, 'https://so.com')))
done, pending = await asyncio.wait(tasks)
for task in done:
print(task.result())
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
在这个代码的基础上,我们可以继续使用 aiohttp 库提供的扩展功能来编写异步网络程序。详细的扩展功能如下所示。
- 使用
aiohttp.ClientSession类可以进行异步请求,这个类提供了多种方法来发起请求,如 get、post、put、delete 等。 - 使用
aiohttp.TCPConnector可以连接池管理,这个类允许你控制并发连接的数量,以及重用连接。 - 使用
aiohttp.ClientTimeout类可以设置超时时间,这个类可以设置 connect_timeout、read_timeout 和 total_timeout 三个属性来控制连接和读取超时时间。 - 使用
aiohttp.ClientSession.request()方法可以进行自定义请求,这个方法允许你设置请求的 method、url、headers 等参数。 - 使用
aiohttp.ClientSession.post()方法可以实现文件上传,使用 aiohttp.ClientSession.get() 方法可以实现文件下载。 - 使用
aiohttp.ClientSession.request()方法可以设置请求的高级选项,如请求的身份验证、代理、重定向、请求超时等。 - 使用
aiohttp.ClientSession.ws_connect()方法可以建立 WebSockets 连接,并使用 async for 来接收消息。
📢📢📢📢📢📢
💗 你正在阅读 【梦想橡皮擦】 的博客
👍 阅读完毕,可以点点小手赞一下
🌻 发现错误,直接评论区中指正吧
📆 橡皮擦的第 832 篇原创博客
从订购之日起,案例 5 年内保证更新
- ⭐️ Python 爬虫 120,点击订购 ⭐️
- ⭐️ 爬虫 100 例教程,点击订购 ⭐️






![[杂记]算法:前缀和与差分数组](https://img-blog.csdnimg.cn/6cc1aac1b545428f929eb0da1ba90050.png)