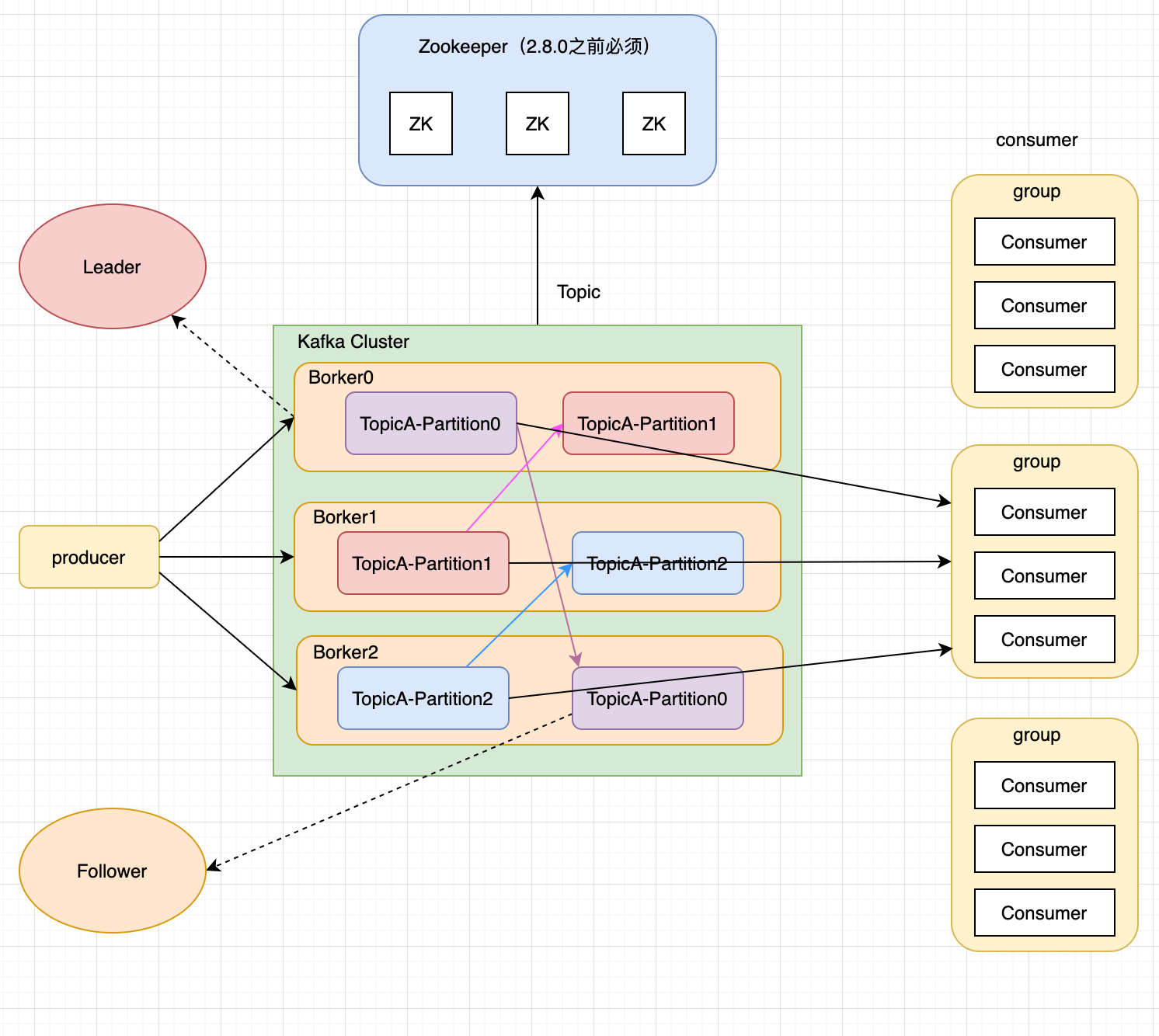
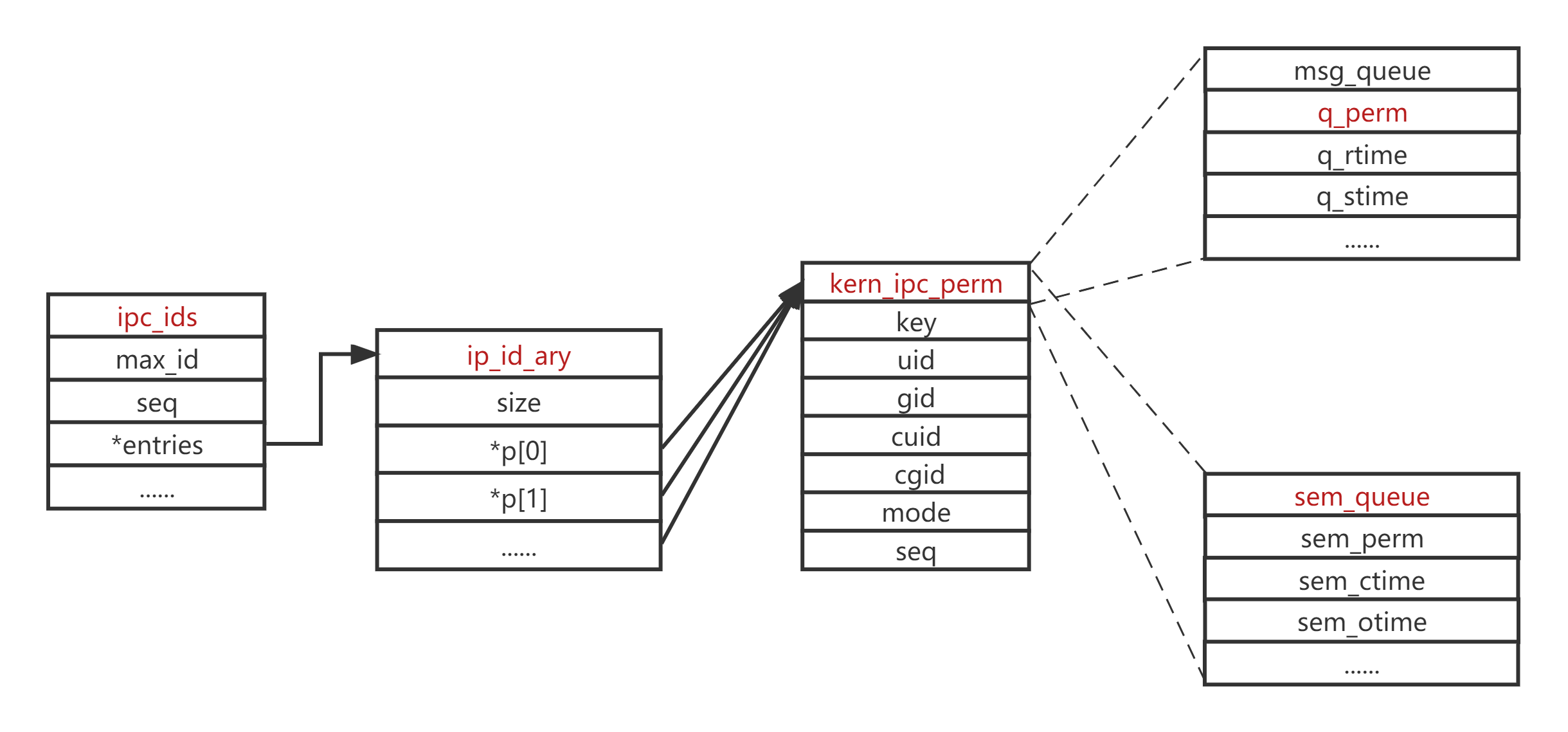
4.1 简介
本章主要介绍sed、awk、grep、cut等命令,这些工具可以相互结合以满足文本处理需求。
正则表达式是一种基础的模式匹配技术。
4.2 使用正则表达式
正则表达式是由字面文本和具有特殊意义的符号组成的。
1)位置标记
位置标记锚点是标识字符串位置的正则表达式。
| 正则表达式 | 描述 | 示例 |
| ^ | 指定了匹配正则表达式的文本必须起始于字符串的首部 | ^tux能够匹配以tux起始的行 |
| $ | 指定了匹配正则表达式的文本必须结束语目标字符串的尾部 | tux$能够匹配以tux结尾的行 |
2)标识符
标识符是正则表达式的基础组成部分。
| 正则表达式 | 描述 |
| A | 正则表达式必须匹配该字符 |
| . | 匹配任意一个字符 |
| [] | 匹配括号中的任意一个字符 |
| [^] | 匹配不在括号中的任意一个字符 |
3)数量修饰符
一个标识符可以出现一次、多次或者不出现,数量修饰符定义了模式可以出现的次数。
| 正则表达式 | 描述 |
| ? | 匹配之前的项1次或者0次 |
| + | 匹配之前的项1次或者多次 |
| * | 匹配之前的项0次或者多次 |
| {n} | 匹配之前的项n次 |
| {n,} | 之前的项至少需要匹配n次 |
| {n,m} | 之前的项所匹配的最小次数和最多次数 |
4)其他
| 正则表达式 | 描述 |
| () | 将括号中的内容视为一个整体 |
| | | 选择结构,可以匹配|两边的任意一项 |
| \ | 转义字符 |
5)示例

4.3 使用grep在文件中搜索文本
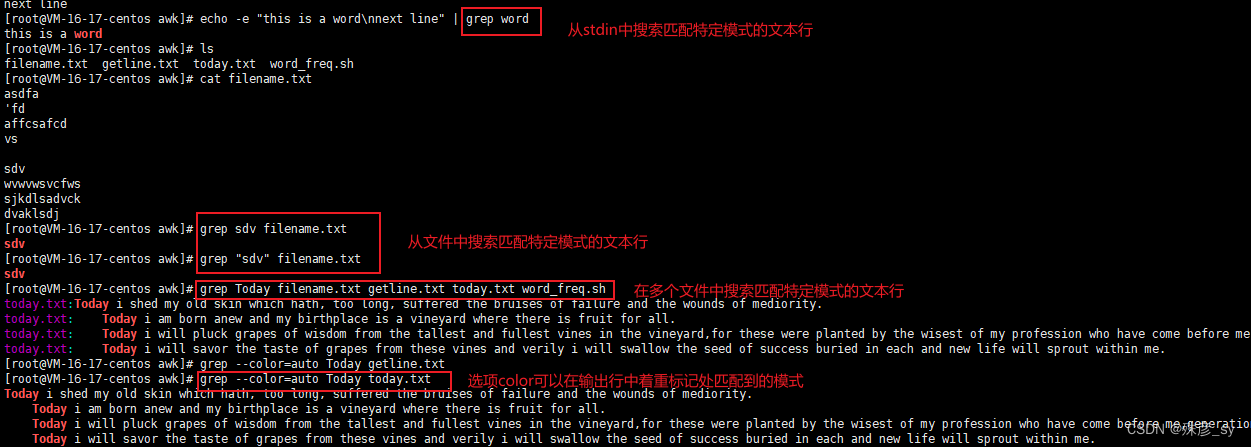
1)grep的用法
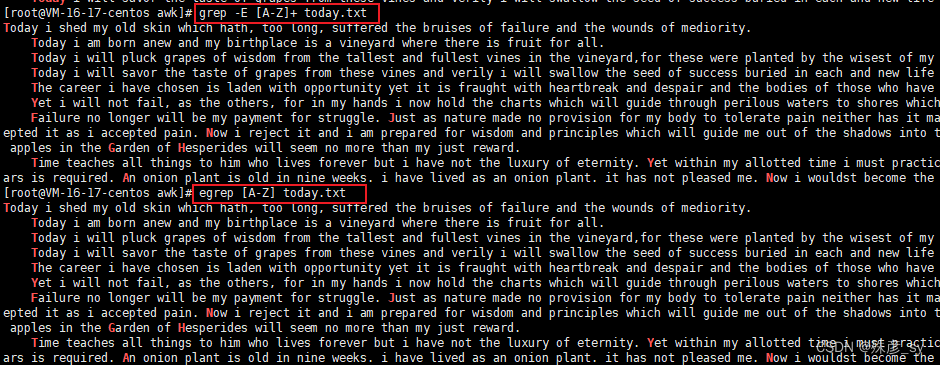

2)递归搜索多个文件

3)忽略模式中的大小写

4)使用grep匹配多个模式

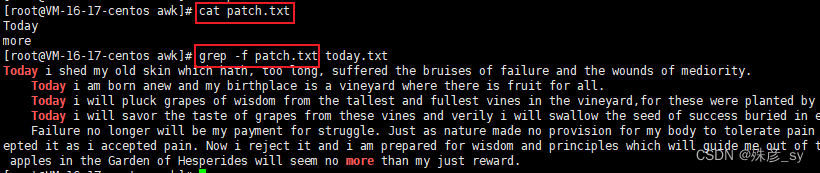
5)在grep搜索中指定或者排除文件

6)使用0值字节后缀的xargs和grep

-l告诉grep只输出有匹配出现的文件名;-Z使得grep使用0值字节作为文件的终结符
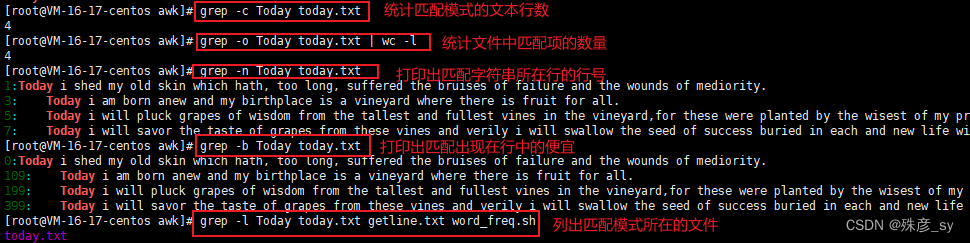
7)grep的静默输出
在静默模式中,grep命令不会输出任何内容。它仅是运行命令,然后根据命令执行成功与否返回退出状态。

8)打印出匹配文本之前或之后的行
-A可以打印出匹配结果之后的行,-B可以打印出匹配结果之前的行,-A-B可以结合使用,等价于-C

4.4 使用cut按列切分文件
cut命令可以按列,而不是按行来切分文件。
1)

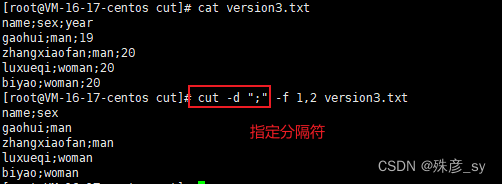
2)cut命令可以根据字节或者字符来指定选择范围
| N- | 从第N个字节、字符或字段开始到行尾 |
| N-M | 从第N个字节、字符或字段开始到第M个(包括第M个在内)字节、字符或字段 |
| -M | 从第1个字节、字符或字段开始到第M个(包括第M个在内)字节、字符或字段 |
-b表示字节,-c表示字符,-f用于定义字段

4.5 使用sed替换文本
sed最常见的用法就是进行文本替换。
![]()
1)


2)之前的例子中只替换了每行中模式首次匹配的内容,g标记可以使sed执行全局替换

/#g标记可以使sed替换第#次出现的匹配
![]()
3)sed命令会将s之后的字符视为命令分隔读。这允许我们更改默认的分隔符/;
如果分隔符的字符出现在模式中,必须使用\对其进行转义。
4)移除空行
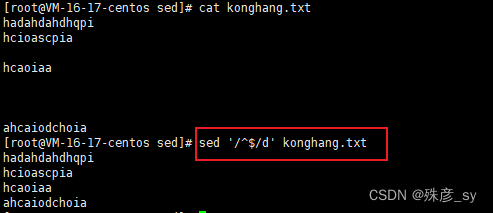
5)直接在文本中替换 sed -i,\b表示单词边界。

6)已匹配字符串标记&
可以用&指代模式所匹配到的字符串,\w\+匹配每一个单词
![]()
7)子串匹配标记
可以使用\#来指代出现在括号中的部分正则表达式所匹配到的内容。
![]()
8)组合多个表达式
可以利用管道组合多个sed命令,多个模式之间可以用分号分隔,或者使用-e。

9)引用
必须是双引号

4.6 使用awk进行高级文本处理
awk命令可以处理数据流。它支持关联数组、递归函数、条件语句等功能。
![]()
awk以逐行的形式处理文件。BEGIN之后的命令会先于公共语句块执行。对于匹配PATTERN的行,awk会对其执行PATTERN之后的命令。最后,在处理完整个文件之后,awk会执行END之后的命令。
1)输出文件行数

2)最重要的部分就是和pattern关联的语句块。这个语句是可选的,如果不提供,则默认执行{print},即打印所读取到的每一行。

当使用不带参数的print时,他会打印出当前行。print能够接受参数,这些参数以逗号分隔,在打印参数时则以空格作为参数之间的分隔符。在awk的print语句中,双引号被当做拼接操作符使用。

3)awk命令是一个解释器,它能够解释并执行程序,和shell一样,它也包括了一些特殊变量。
| 特殊变量 | 含义 |
| NR | 记录编号 |
| NF | 字段数量 |
| $0 | 该变量包含了当前记录的文本内容 |
| $1 | 该变量包含了第一个字段的文本内容 |
| $2 | 该变量包含了第二个字段的文本内容 |

![]()
4)借助外部变量值传递给awk
![]()

5)从getline读取行
awk默认读取文件中的所有行。如果只想读取某一行,可以使用getline函数。
该函数的语法为:getline var。变量var包含了特定行。

6)使用过滤模式对awk处理的行进行过滤
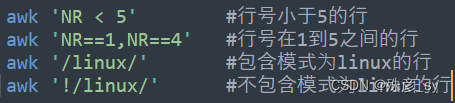
7)设置字段分隔符

8)在awk中使用循环

4.7 统计特定文件中的词频


4.8 压缩和解压缩JavaScript

4.9 按列合并多个文件
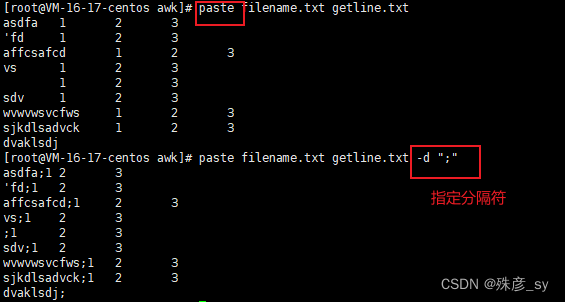
4.10 打印文件或行中的第n个单词或列

4.11 打印指定行或者模式之间的文本


4.12 以逆序形式打印行
最简单的形式就是使用tac命令,当然也可以用awk来搞定。
1)tac
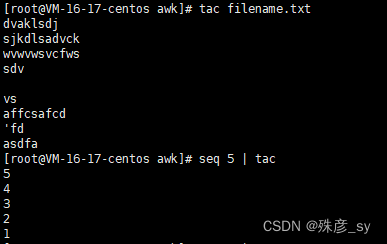
tac默认使用\n作为分隔符,但是我们也可以使用选项-s指定其他分隔符

2)awk
![]()

4.13 解析文本中的电子邮件地址和URL
1)能够匹配邮件地址的正则表达式:
![]()

2)匹配HTTP URL的正则表达式:
![]()

4.14 删除文件中包含特定单词的句子
sed是进行文本替换的不二之选,我们可以利用sed将匹配的句子替换成空白。

4.15 对目录中的所有文件进行文本替换


4.16 文件切片与参数操作
1)替换变量内容中的部分文本
![]()
2)我们可以通过指定字符串的起始位置和长度来生成子串
${var:M:N}:从第M+1个字符开始,打印N个字符