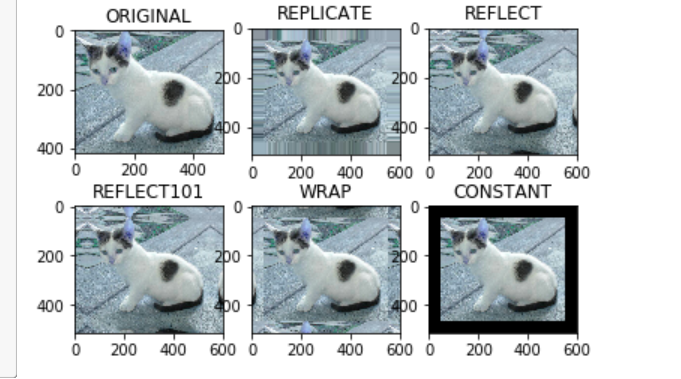
前言
Stacking堆叠法基础知识:http://t.csdn.cn/dzAna
1、Blending的基本思想与流程👿
Blending融合是在Stacking融合的基础上改进过后的算法。在之前的课程中我们提到,堆叠法stacking在level 1上使用算法,这可以令融合本身向着损失函数最小化的方向进行,同时stacking使用自带的内部交叉验证来生成数据,可以深度使用训练数据,让模型整体的效果更好。但在这些操作的背后,存在两个巨大的问题:
Stacking融合需要巨大的计算量,需要的时间和算力成本较高,以及
Stacking融合在数据和算法上都过于复杂,因此融合模型过拟合的可能性太高。
Blending直译为“混合”,但它的核心思路其实与Stacking完全一致:使用两层算法串联,level 0上存在多个强学习器,level 1上有且只有一个元学习器,且level 0上的强学习器负责拟合数据与真实标签之间的关系、并输出预测结果、组成新的特征矩阵,然后让level 1上的元学习器在新的特征矩阵上学习并预测。

然而,与Stacking不同的是,为了降低计算量、降低融合模型过拟合风险,Blending取消了K折交叉验证、并且大大地降低了元学习器所需要训练的数据量,其具体流程如下:
Blending的训练
- 将数据分割为训练集、验证集与测试集,其中训练集上的样本为𝑀𝑡𝑟𝑎𝑖𝑛,验证集上的样本为𝑀𝑣,测试集上的样本量为𝑀𝑡𝑒𝑠𝑡
- 将训练集输入level 0的个体学习器,分别在每个个体学习器上训练。训练完毕后,在验证集上进行验证,输出验证集上的预测结果。假设预测结果为概率值,当融合模型执行回归或二分类任务时,该预测结果的结构为(𝑀𝑣,1),当融合模型执行K分类任务时(K>2),该预测结果的结构为(𝑀𝑣,𝐾)。此时此刻,所有个体学习器都被训练完毕了。
- 将所有个体学习器的验证结果横向拼接,形成新特征矩阵。假设共有N个个体学习器,则新特征矩阵的结构为(𝑀𝑣,𝑁)。
- 将新特征矩阵放入元学习器进行训练。
Blending的测试
- 将测试集输入level 0的个体学习器,分别在每个个体学习器上预测出相应结果。假设测试结果为概率值,当融合模型执行回归或二分类任务时,该测试结果的结构为(𝑀𝑡𝑒𝑠𝑡,1),当融合模型执行K分类任务时(K>2),该测试结果的结构为(𝑀𝑡𝑒𝑠𝑡,𝐾)
- 将所有个体学习器的预测结果横向拼接为新特征矩阵。假设共有N个个体学习器,当融合模型执行回归或二分类任务时,则新特征矩阵的结构为(𝑀𝑡𝑒𝑠𝑡,𝑁),如果是输出多分类的概率,那最终得出的新特征矩阵的结构为(𝑀𝑡𝑒𝑠𝑡,𝑁∗𝐾)
- 将新特征矩阵放入元学习器进行预测。
- 在Stacking时我们提到:在实际进行训练时,验证集肯定是远远小于训练集的,因此只使用一部分验证集进行预测的方法一定会让新特征矩阵的尺寸变得非常小。在大部分时候,这是一个劣势,但在数据量庞大、运算成本极高的场景下,只使用一部分验证集构建新特征矩阵,反而还能提升运算速度、降低运算成本、防止模型过度学习、并提升模型的抗过拟合能力。很显然的,验证集越大,模型抗过拟合能力越强,同时学习能力越弱。
- 在实际应用时,如果数据量较大、且Stacking方法表现出过拟合程度很高,那换Blending融合可以获得更好的结果。相对的,如果Stacking算法没有表现出太强的过拟合,那换Blending融合可能导致模型的学习能力极速下降。
- 有一种场景下,Stacking和Blending都无法发挥效用,即数据量很小、且stacking表现出强烈过拟合的情况。这种状况下,数据或许不适合模型融合场景,或者我们可以更换成规则更简单的融合方式,例如平均、投票等来查看模型的过拟合情况。在实际中,Stacking的应用是远比Blending广泛的。
- 目前,sklearn还不支持Blending方法。
2、实现Blending算法👮
def BlendingClassifier(X,y,estimators,final_estimator,test_size=0.2,vali_size=0.4):
"""
该函数用于实现Blending分类融合
X,y:整体数据集,会被分割为训练集、测试集、验证集三部分
estimators: level0的个体学习器,输入格式形如sklearn中要求的[(名字,算法),(名字,算法)...]
final_estimator:元学习器
test_size:测试集占全数据集的比例
vali_size:验证集站全数据集的比例
"""
#第一步,分割数据集
#1.分测试集
#2.分训练和验证集,验证集占完整数据集的比例为0.4,因此占排除测试集之后的比例为0.4/(1-0.2)
X_,Xtest,y_,Ytest = train_test_split(X,y,test_size=test_size,random_state=1412)
Xtrain,Xvali,Ytrain,Yvali = train_test_split(X_,y_,test_size=vali_size/(1-test_size),random_state=1412)
#训练
#建立空dataframe用于保存个体学习器上的验证结果,即用于生成新特征矩阵
#新建空列表用于保存训练完毕的个体学习器,以便在测试中使用
NewX_vali = pd.DataFrame()
trained_estimators = []
#循环、训练每个个体学习器、并收集个体学习器在验证集上输出的概率
for clf_id, clf in estimators:
clf = clf.fit(Xtrain,Ytrain)
val_predictions = pd.DataFrame(clf.predict_proba(Xvali))
#保存结果,在循环中逐渐构筑新特征矩阵
NewX_vali = pd.concat([NewX_vali,val_predictions],axis=1)
trained_estimators.append((clf_id,clf))
#元学习器在新特征矩阵上训练、并输出训练分数
final_estimator = final_estimator.fit(NewX_vali,Yvali)
train_score = final_estimator.score(NewX_vali,Yvali)
#测试
#建立空dataframe用于保存个体学习器上的预测结果,即用于生成新特征矩阵
NewX_test = pd.DataFrame()
#循环,在每个训练完毕的个体学习器上进行预测,并收集每个个体学习器上输出的概率
for clf_id,clf in trained_estimators:
test_prediction = pd.DataFrame(clf.predict_proba(Xtest))
#保存结果,在循环中逐渐构筑特征矩阵
NewX_test = pd.concat([NewX_test,test_prediction],axis=1)
#元学习器在新特征矩阵上测试、并输出测试分数
test_score = final_estimator.score(NewX_test,Ytest)
#打印训练分数与测试分数
print(train_score,test_score)#逻辑回归没有增加多样性的选项
clf1 = LogiR(max_iter = 3000, C=0.1, random_state=1412,n_jobs=8)
#增加特征多样性与样本多样性
clf2 = RFC(n_estimators= 100,max_features="sqrt",max_samples=0.9, random_state=1412,n_jobs=8)
#特征多样性,稍微上调特征数量
clf3 = GBC(n_estimators= 100,max_features=16,random_state=1412)
#增加算法多样性,新增决策树与KNN
clf4 = DTC(max_depth=8,random_state=1412)
clf5 = KNNC(n_neighbors=10,n_jobs=8)
clf6 = GaussianNB()
#新增随机多样性,相同的算法更换随机数种子
clf7 = RFC(n_estimators= 100,max_features="sqrt",max_samples=0.9, random_state=4869,n_jobs=8)
clf8 = GBC(n_estimators= 100,max_features=16,random_state=4869)
estimators = [("Logistic Regression",clf1), ("RandomForest", clf2)
, ("GBDT",clf3), ("Decision Tree", clf4), ("KNN",clf5)
#, ("Bayes",clf6)
#, ("RandomForest2", clf7), ("GBDT2", clf8)
]final_estimator = RFC(n_estimators= 100
#, max_depth = 8
, min_impurity_decrease=0.0025
, random_state= 420, n_jobs=8)
从结果来看,投票法表现最稳定和优异,这与我们选择的数据集是较为简单的数据集有关,同时投票法也是我们调整最多、最到位的算法。在大型数据集上运行时,Stacking和Blending会展现出更多的优势。






![[杂记]算法:前缀和与差分数组](https://img-blog.csdnimg.cn/6cc1aac1b545428f929eb0da1ba90050.png)