一、Kafka是什么
1.定义
Apache Kafka 是一款开源的消息引擎系统。
消息引擎系统是一组规范。企业利用这组规范在不同系统之间传递语义准确的消息,实现松耦合的异步式数据传递。
二、消息队列的使用场景
传统消息队列的应用场景包括 缓存/削峰、解耦、异步通信
1.缓存/削峰
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
2.解耦
允许独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
3.异步通信
允许用户把一个消息放入队列,但并不立即处理它,然后在需要的时候再去处理它们。
三、Kafka的使用场景
- 日志收集:可以用Kafka收集各种服务的log,通过kafka以统一接口服务的方式开放给各种 consumer,例如hadoop、Hbase、Solr等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反 馈,比如报警和报告。
四、消息队列的模式
1.点对点模型
也叫消息队列模型。消费者主动拉取数据,消息收到后清除消息。
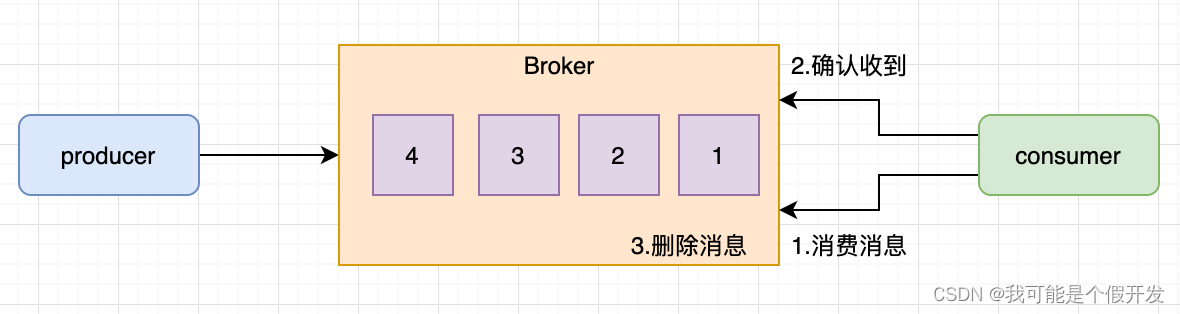
系统 A 发送的消息只能被系统 B 接收,其他任何系统都不能读取 A 发送的消息。日常生活的例子比如电话客服就属于这种模型:同一个客户呼入电话只能被一位客服人员处理,第二个客服人员不能为该客户服务。
2.发布 / 订阅模型
- 可以有多个topic主题(浏览、点赞、收藏、评论等)
- 消费者消费数据之后,不删除数据
- 每个消费者相互独立,都可以消费到数据
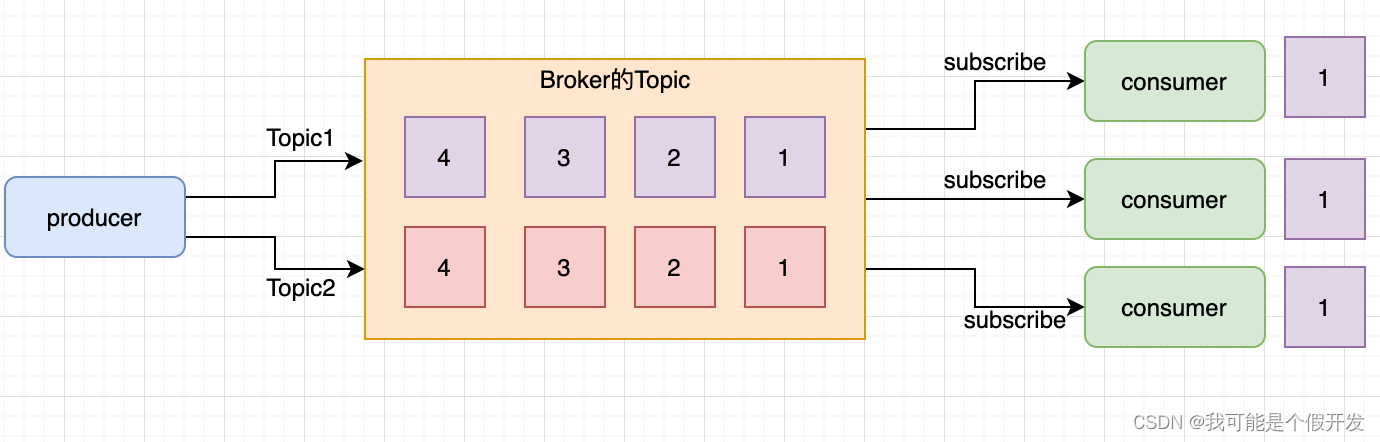
与上面不同的是,它有一个主题(Topic)的概念,你可以理解成逻辑语义相近的消息容器。该模型也有发送方和接收方,只不过提法不同。发送方也称为发布者(Publisher),接收方称为订阅者(Subscriber)。和点对点模型不同的是,这个模型可能存在多个发布者向相同的主题发送消息,而订阅者也可能存在多个,它们都能接收到相同主题的消息。生活中的报纸订阅就是一种典型的发布 / 订阅模型。
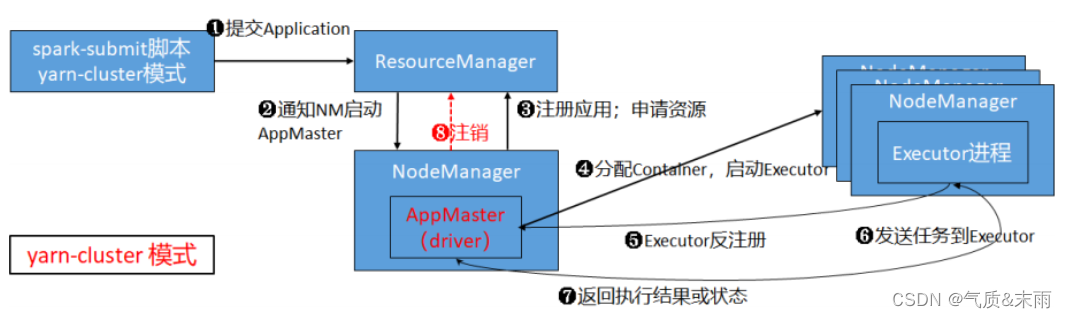
五、Kafka基础架构
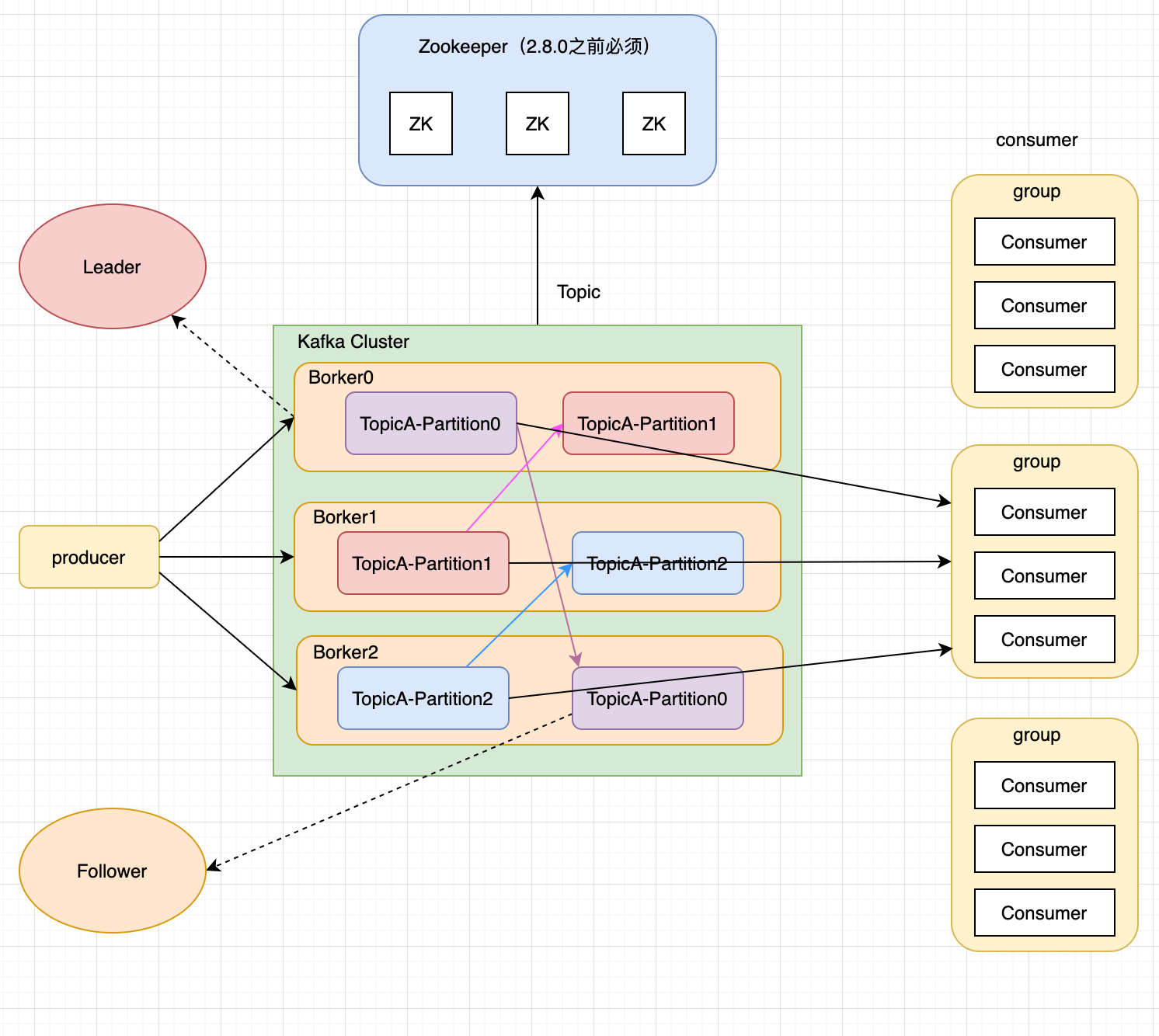
1.为方便扩展,并提高吞吐量,一个topic分为多个partition
2.配合分区的设计,提出消费者组的概念,组内每个消费者并行消费
3.为提高可用性,为每个partition增加若干副本,类似NameNode HA
4.ZK中记录谁是leader,Kafka2.8.0以后也可以配置不采用ZK
- 消息:Record;Kafka 处理的主要对象。
- 消息生产者:Producer;向 Kafka broker 发消息的客户端。
- 消息消费者:Consumer;向 Kafka broker 取消息的客户端。
- 消费者组:Consumer Group(CG);消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不 影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- Broker:一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个broker 可以容纳多个 topic。
- 主题:Topic;可以理解为一个队列,生产者和消费者面向的都是一个 topic,主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。
- 分区:Partition;一个有序不变的消息序列。每个主题下可以有多个分区,为了实现扩展性,一个非常大的topic 可以分布到多个broker(即服务器)上,一个 topic 可以分为多个partition,每个 partition 是一个有序的队列。
- 副本:Replica;一个topic 的每个分区都有若干个副本,一个 Leader 和若干个Follower。
- Leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数
据的对象都是 Leader。 - Follower: 每个分区多个副本中的 “ 从 ” , 实时从Leader中同步数据,保持和
Leader 数据的同步。Leader 发生故障时,某个 Follower 会成为新的 Leader。
《Kafka 核心技术与实战》学习笔记Day1