基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (四)
大家继续看 https://lilianweng.github.io/posts/2023-06-23-agent/的文档内容
第三部分:工具使用
工具的使用是人类的一个显着而显着的特征。我们创造、修改和利用外部物体来完成超出身体和认知极限的事情。为大模型配备外部工具可以显着扩展模型功能。
- 有些动物制造和使用工具的方式简直就是天才。 海獭漂浮在水中时使用岩石敲开贝壳的照片。虽然其他一些动物也可以使用工具,但其复杂性却无法与人类相比。

MRKL
(Karpas et al. 2022)是“模块化推理、知识和语言”的缩写,是一种用于自主代理的神经符号架构。建议 MRKL 系统包含一组“专家”模块,通用 LLM 作为路由器将查询路由到最合适的专家模块。这些模块可以是神经模块(例如深度学习模型)或符号模块(例如数学计算器、货币转换器、天气 API)。
他们做了一个微调 LLM 以调用计算器的实验,使用算术作为测试用例。他们的实验表明,解决口头数学问题比明确表述的数学问题更难,因为大模型(7B Jurassic1-large model)无法可靠地为基本算术提取正确的论据。结果强调了外部符号工具何时可以可靠地工作,知道何时以及如何使用这些工具至关重要,这由大模型的能力决定。
TALM
(工具增强语言模型;Parisi 等人,2022 年)和Toolformer(Schick 等人,2023 年)都对 LM 进行微调,以学习使用外部工具 API。根据新添加的API调用注释是否可以提高模型输出的质量来扩展数据集。请参阅Prompt Engineering 的“外部 API”部分了解更多详细信息。
ChatGPT插件和 OpenAI API 函数调用是大模型在实践中通过工具使用能力增强的好例子。工具API的集合可以由其他开发者提供(如在插件中)或自定义(如在函数调用中)。
HuggingGPT
(Shen et al. 2023)是一个使用 ChatGPT 作为任务规划器的框架,根据模型描述选择 HuggingFace 平台中可用的模型,并根据执行结果总结响应。
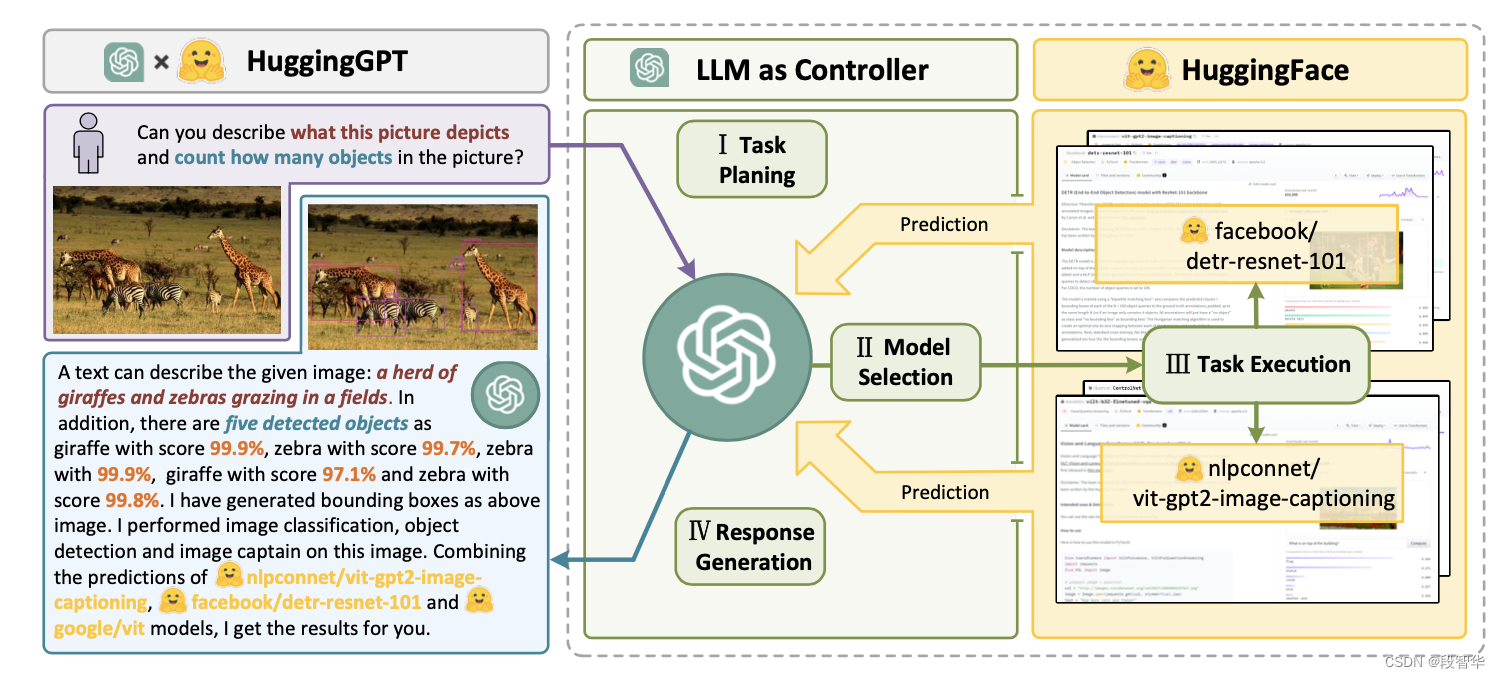
HuggingGPT 工作原理图解
该系统由4个阶段组成:
(1)任务规划:LLM作为大脑,将用户请求解析为多个任务。每个任务有四个关联的属性:任务类型、ID、依赖项和参数。他们使用少量的例子来指导LLM进行任务解析和规划。
指令说明:
The AI assistant can parse user input to several tasks: [{"task": task, "id", task_id, "dep": dependency_task_ids, "args": {"text": text, "image": URL, "audio": URL, "video": URL}}]. The "dep" field denotes the id of the previous task which generates a new resource that the current task relies on. A special tag "-task_id" refers to the generated text image, audio and video in the dependency task with id as task_id. The task MUST be selected from the following options: {{ Available Task List }}. There is a logical relationship between tasks, please note their order. If the user input can't be parsed, you need to reply empty JSON. Here are several cases for your reference: {{ Demonstrations }}. The chat history is recorded as {{ Chat History }}. From this chat history, you can find the path of the user-mentioned resources for your task planning.
AI助手可以将用户输入解析为多个任务:[{“task”:task,“id”,task_id,“dep”:dependency_task_ids,“args”:{“text”:text,“image”:URL,“audio “:网址,“视频”:网址}}]。 “dep”字段表示前一个任务的id,该任务生成当前任务所依赖的新资源。特殊标签“-task_id”是指id为task_id的依赖任务中生成的文本图片、音频和视频。任务必须从以下选项中选择:{{可用任务列表}}。任务之间有逻辑关系,请注意如果无法解析用户输入,则需要回复空 JSON。以下是几种情况供您参考:{{ 演示 }}。聊天记录记录为 {{ Chat History }}。历史记录,您可以找到用户提到的资源的路径,以便您规划任务。
(2) 模型选择:LLM将任务分配给专家模型,其中请求被构建为多项选择题。 LLM 提供了可供选择的模型列表。由于上下文长度有限,需要基于任务类型的过滤。
给定用户请求和调用命令,AI助手帮助用户从模型列表中选择合适的模型来处理用户请求。 AI助手仅输出最合适模型的模型id。输出必须采用严格的 JSON 格式:“id”:“id”,“reason”:“您选择的详细原因”。我们有一个模型列表供您从{{候选模型}}中进行选择。请从列表中选择一种型号。
(3) 任务执行:专家模型执行特定任务并记录结果。
指令说明
有了输入和推理结果,AI助手需要描述过程和结果。前面的阶段可以形成为-用户输入:{{用户输入}},任务规划:{{任务}},模型选择:{{模型分配}},任务执行:{{预测}}。您必须首先以直截了当的方式回答用户的请求。然后描述任务流程,并以第一人称的方式向用户展示你的分析和模型推理结果。如果推理结果包含文件路径,必须告诉用户完整的文件路径。
(4) 响应生成:LLM接收执行结果并向用户提供汇总结果。
为了将 HuggingGPT 投入到现实世界中,需要解决几个挑战:(1)需要提高效率,因为 LLM 推理轮次和与其他模型的交互都会减慢流程; (2) 依赖长上下文窗口来进行复杂任务内容的通信; (3)LLM产出和外部模型服务的稳定性提升。
API-Bank
(Li et al. 2023)是评估工具增强大模型性能的基准。它包含 53 个常用的 API 工具、完整的工具增强的 LLM 工作流程以及涉及 568 个 API 调用的 264 个带注释的对话。 API的选择相当多样化,包括搜索引擎、计算器、日历查询、智能家居控制、日程管理、健康数据管理、账户认证工作流程等等。由于API数量较多,LLM首先要访问API搜索引擎找到合适的API进行调用,然后使用相应的文档进行调用。

在 API-Bank 工作流程中,大模型需要做出几个决定,在每一步我们都可以评估该决定的准确性。决定包括:
- 是否需要API调用。
- 确定要调用的正确 API:如果不够好,大模型需要迭代修改 API 输入(例如,确定搜索引擎 API 的搜索关键字)。
- 基于API结果的响应:如果结果不满意,模型可以选择细化并再次调用。
该基准测试从三个层面评估代理的工具使用能力:
- Level-1评估调用API的能力。给定 API 的描述,模型需要确定是否调用给定的 API、正确调用它并正确响应 API 返回。
- Level-2 检查检索 API 的能力。模型需要搜索可能解决用户需求的API,并通过阅读文档来学习如何使用它们。
- Level-3 评估除了检索和调用之外规划 API 的能力。考虑到不明确的用户请求(例如安排小组会议、预订旅行的航班/酒店/餐厅),模型可能必须进行多个 API 调用来解决它。
大模型技术分享



《企业级生成式人工智能LLM大模型技术、算法及案例实战》线上高级研修讲座
模块一:Generative AI 原理本质、技术内核及工程实践周期详解
模块二:工业级 Prompting 技术内幕及端到端的基于LLM 的会议助理实战
模块三:三大 Llama 2 模型详解及实战构建安全可靠的智能对话系统
模块四:生产环境下 GenAI/LLMs 的五大核心问题及构建健壮的应用实战
模块五:大模型应用开发技术:Agentic-based 应用技术及案例实战
模块六:LLM 大模型微调及模型 Quantization 技术及案例实战
模块七:大模型高效微调 PEFT 算法、技术、流程及代码实战进阶
模块八:LLM 模型对齐技术、流程及进行文本Toxicity 分析实战
模块九:构建安全的 GenAI/LLMs 核心技术Red Teaming 解密实战
模块十:构建可信赖的企业私有安全大模型Responsible AI 实战
Llama3关键技术深度解析与构建Responsible AI、算法及开发落地实战
1、Llama开源模型家族大模型技术、工具和多模态详解:学员将深入了解Meta Llama 3的创新之处,比如其在语言模型技术上的突破,并学习到如何在Llama 3中构建trust and safety AI。他们将详细了解Llama 3的五大技术分支及工具,以及如何在AWS上实战Llama指令微调的案例。
2、解密Llama 3 Foundation Model模型结构特色技术及代码实现:深入了解Llama 3中的各种技术,比如Tiktokenizer、KV Cache、Grouped Multi-Query Attention等。通过项目二逐行剖析Llama 3的源码,加深对技术的理解。
3、解密Llama 3 Foundation Model模型结构核心技术及代码实现:SwiGLU Activation Function、FeedForward Block、Encoder Block等。通过项目三学习Llama 3的推理及Inferencing代码,加强对技术的实践理解。
4、基于LangGraph on Llama 3构建Responsible AI实战体验:通过项目四在Llama 3上实战基于LangGraph的Responsible AI项目。他们将了解到LangGraph的三大核心组件、运行机制和流程步骤,从而加强对Responsible AI的实践能力。
5、Llama模型家族构建技术构建安全可信赖企业级AI应用内幕详解:深入了解构建安全可靠的企业级AI应用所需的关键技术,比如Code Llama、Llama Guard等。项目五实战构建安全可靠的对话智能项目升级版,加强对安全性的实践理解。
6、Llama模型家族Fine-tuning技术与算法实战:学员将学习Fine-tuning技术与算法,比如Supervised Fine-Tuning(SFT)、Reward Model技术、PPO算法、DPO算法等。项目六动手实现PPO及DPO算法,加强对算法的理解和应用能力。
7、Llama模型家族基于AI反馈的强化学习技术解密:深入学习Llama模型家族基于AI反馈的强化学习技术,比如RLAIF和RLHF。项目七实战基于RLAIF的Constitutional AI。
8、Llama 3中的DPO原理、算法、组件及具体实现及算法进阶:学习Llama 3中结合使用PPO和DPO算法,剖析DPO的原理和工作机制,详细解析DPO中的关键算法组件,并通过综合项目八从零开始动手实现和测试DPO算法,同时课程将解密DPO进阶技术Iterative DPO及IPO算法。
9、Llama模型家族Safety设计与实现:在这个模块中,学员将学习Llama模型家族的Safety设计与实现,比如Safety in Pretraining、Safety Fine-Tuning等。构建安全可靠的GenAI/LLMs项目开发。
10、Llama 3构建可信赖的企业私有安全大模型Responsible AI系统:构建可信赖的企业私有安全大模型Responsible AI系统,掌握Llama 3的Constitutional AI、Red Teaming。
解码Sora架构、技术及应用
一、为何Sora通往AGI道路的里程碑?
1,探索从大规模语言模型(LLM)到大规模视觉模型(LVM)的关键转变,揭示其在实现通用人工智能(AGI)中的作用。
2,展示Visual Data和Text Data结合的成功案例,解析Sora在此过程中扮演的关键角色。
3,详细介绍Sora如何依据文本指令生成具有三维一致性(3D consistency)的视频内容。 4,解析Sora如何根据图像或视频生成高保真内容的技术路径。
5,探讨Sora在不同应用场景中的实践价值及其面临的挑战和局限性。
二、解码Sora架构原理
1,DiT (Diffusion Transformer)架构详解
2,DiT是如何帮助Sora实现Consistent、Realistic、Imaginative视频内容的?
3,探讨为何选用Transformer作为Diffusion的核心网络,而非技术如U-Net。
4,DiT的Patchification原理及流程,揭示其在处理视频和图像数据中的重要性。
5,Conditional Diffusion过程详解,及其在内容生成过程中的作用。
三、解码Sora关键技术解密
1,Sora如何利用Transformer和Diffusion技术理解物体间的互动,及其对模拟复杂互动场景的重要性。
2,为何说Space-time patches是Sora技术的核心,及其对视频生成能力的提升作用。
3,Spacetime latent patches详解,探讨其在视频压缩和生成中的关键角色。
4,Sora Simulator如何利用Space-time patches构建digital和physical世界,及其对模拟真实世界变化的能力。
5,Sora如何实现faithfully按照用户输入文本而生成内容,探讨背后的技术与创新。
6,Sora为何依据abstract concept而不是依据具体的pixels进行内容生成,及其对模型生成质量与多样性的影响。




![[240512] x-cmd 发布 v0.3.6: (se,wkp,ddgo...)x( kimi,gemini,gpt...)](https://img-blog.csdnimg.cn/direct/f09b4b037c3d4fc69ce82f7278a79382.gif#pic_center)