1.概念
lambda表达式实际上是一个匿名类的成员函数,该类由编译器为lambda创建,该函数被隐式地定义为内联。因此,调用lambda表达式相当于直接调用匿名类的operator()函数,这个函数可以被编译器内联优化(建议)。
编译器为每个 lambda 表达式创建一个唯一的类型,该类型具有一个重载的 operator() 函数,其参数和返回类型与 lambda 表达式的参数和返回类型相匹配。
例如快速排序算法,STL允许用户自定义比较方式,在C++11之前,通常使用仿函数实现。但是代码一旦很长,使用之处和仿函数实现的地方相隔甚远,而且如果仿函数的命名不规范,很容易造成使用上的困难。
仿函数,又叫做函数对象(functor,function object),因为实现仿函数的方式就是重载一个类的
operator(),只是用起来跟函数一样,其本质依然是一个对象。
2.语法
C++11的lambda表达式是一种允许内联函数的特性,它可以用于不需要重用和命名的代码片段。lambda表达式的一般形式是:
[capture clause] (parameters) mutable -> return-type { function body }
- [captureclause]:捕捉列表。该列表总是出现在lambda函数的开始位置,编译器根据
[]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda函数使用。- (parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起省略。
- mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空)。
- ->return-type:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可以省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推导。
- {statement}:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量。
以一个简单的例子理解lambda表达式的语法:
[]
{
cout << "hello lambda" << endl;
}
这一大坨就表示它是一个类型/对象(type、class),我们知道,在类型后加上(),就表示调用这个对象的构造函数,而lambda的语法有些不同,在它后面加上括号,就表示调用它。如下所示:
#include <iostream>
using namespace std;
int main()
{
[]
{
cout << "hello lambda" << endl;
}();
return 0;
}
输出:
hello lambda
l在这里是任意取的名字(实际上要根据含义),刚才提到,方括号和后面一坨东西,就相当于一个对象,一般情况下我们是不知道它的类型的,所以通常用auto接收。
现在,最简形式的lambda表达式就写出来了,试着调用它:
#include <iostream>
using namespace std;
int main()
{
auto l = []
{
cout << "hello lambda" << endl;
};
l();
return 0;
}
输出:
hello lambda
注意:
- 上面的例子和概念中的“内联”属性并没有关系。
- lambda表达式在main函数之外定义也不影响结果。
- lambda表达式的最后有分号。
- lambda函数的参数列表和返回值类型不是必要的,但捕捉列表和函数体是不可省略的。习惯上不写返回值,让表达式自动推导。
3.基本语法的应用
现在我们对lambda表达式基本语法有了大致的了解,下面进行详细介绍。
示例1
int main()
{
int id = 0;
auto f = [id]() mutable//捕捉列表没有任何符号 "="、"&",表示以传值方式捕捉变量,
//mutable是使得表达式内部可以修改捕捉到的变量,且捕捉后不再受外界变量id的影响
{
cout << "id:" << id << endl;
++id;//没有mutable修饰,这里将编译错误
};
id = 42;
f();//0
f();//1
f();//2
cout << "id:" << id << endl;//42
return 0;
}输出:
id:0
id:1
id:2
id:42
这与设想的结果应该不同:既然变量id的值已经被更新为42,那么lambda表达式f打印出的值应该是42、43、44,这是为何呢?这个问题会在看完所有例子以后揭晓答案。
通过例1,最重要的是理解lambda的本质是一个仿函数,例1的lambda表达式等价于下面的代码:
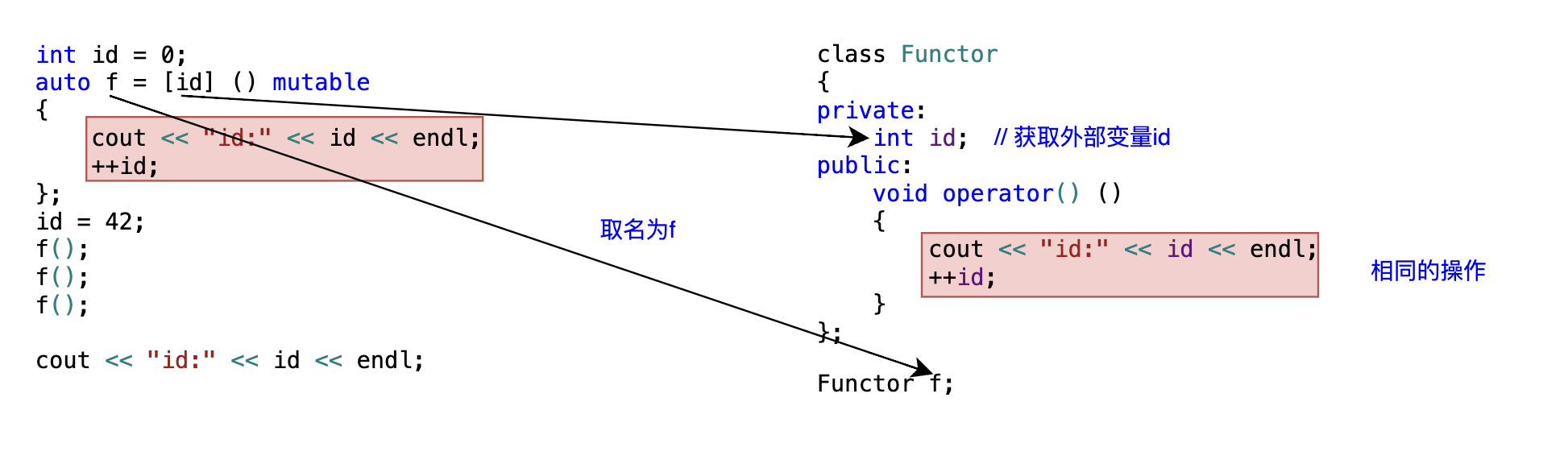
[id]中没有任何特殊符号,表示默认以传值方式捕捉变量,也就相当于拷贝一份变量id的副本到这个匿名函数中,且捕捉后不再受外界变量id的影响mutable表示可以修改捕捉的变量,那么也就可以执行自增语句- 例1按照语句的执行顺序,在执行lambda表达式时,变量
id的值为0时就已经被捕捉了,即使它被更新为42,后续调用lambda表达式时变量id仍然从0开始
但是,即使lambda表达式内部对变量id自增,最终变量id仍然为最后一次修改的值:42。
示例2
int main()
{
int id = 0;
auto f = [&id](int param)//参数param是值传递,每次传值都是一次临时拷贝
{
cout << "id:" << id << ", ";
cout << "param:" << param << endl;
++id;
++param;
};
id = 42;
f(7);// 42 7
f(7);// 43 7
f(7);// 44 7
cout << "id:" << id << endl;// 45
return 0;
}例2和例1的区别:去掉了mutable,以传引用方式捕捉变量,新增参数param。
[&id],表示以引用方式捕捉变量id。那么匿名函数内部和外界处理的变量id就是同一个,函数内部和外部都会互相影响。因此在调用lambda表达式之前变量id被更新为42仍然会影响lambda表达式内部。- 参数param是值传递,每次传值都是一次临时拷贝。
示例3
int main()
{
int id = 0;
auto f = [id]() mutable
{
cout << "id:" << id << endl;
++id;
static int x = 5;
int y = 6;
return id;
};
f();
return 0;
}这说明lambda表达式本质就是一个匿名函数(底层由仿函数实现) ,所有函数的内部都能定义不同类型的变量,也允许有返回值。
4.捕捉方式
基本方式
Lambda表达式的捕捉方式是指它如何访问外部变量,也就是定义在lambda表达式之外的变量。Lambda表达式的最基本的两种捕获方式是:按值捕获(Capture by Value)和按引用捕获(Capture by Reference)。
按值捕获是指lambda表达式内部保存一份外部变量的副本,对这个副本进行操作不会影响原来的变量。
按引用捕获是指lambda表达式内部直接使用外部变量的引用,对这个引用进行操作会影响原来的变量。
隐式和混合
除此之外,还有两种方式:隐式捕获和混合方式。它们是两种更简便的捕获方式,它们可以让编译器自动推断需要捕获的外部变量。
隐式捕获:
- [=]表示以值捕获的方式捕获所有外部变量(默认),成员函数包括this指针;
- [&]表示以引用捕获的方式捕获所有外部变量,成员函数包括this指针。
混合方式是指在隐式捕获的基础上,显式地指定某些变量的不同捕获方式。
混合使用时,要求捕获列表中第一个元素必须是隐式捕获(&或=),然后后面可以跟上显式指定的变量名和符号。
混合使用时,若隐式捕获采用引用捕获&,则显式指定的变量必须采用值捕获的方式;若隐式捕获采用值捕获=,则显式指定的变量必须采用引用捕获的方式,即变量名前加&。
int main()
{
int a = 123;
int b = 456;
auto f = [=, &b]() { // 隐式值捕获a,显式引用捕获b
cout << a << endl; // 输出:123
cout << b << endl; // 输出:456
b = 789; // 修改b的值
};
f();
cout << b << endl; // 输出:789
return 0;
}
输出:
123
456
789
补充
[=]以值捕获,是默认状态一般不写。
不允许以相同方式重复捕捉,例如[=, a],前者已经表示以值捕获所有外部变量,后者就重复了。但是[=, &a]是被允许的,因为它们的捕获方式不同。
Lambda表达式的父作用域是指定义lambda表达式的那个作用域,通常是一个函数或者一个类。Lambda表达式的块作用域是指lambda表达式本身的作用域,它是一个匿名函数,可以在其他地方调用。
Lambda表达式可以捕获父作用域中的局部变量,但是不能捕获其他作用域或者非局部变量。Lambda表达式捕获父作用域中的局部变量时,要求这个变量必须是声明为final的,或者实际上是final的(即不会被修改)。Lambda表达式不能在自己的块作用域中声明和父作用域中同名的参数或者局部变量。
Lambda表达式之间不能相互赋值,因为它们的本质是函数对象。即使从文本层面看它们的名字相同,但是底层编译器给它们取的名字是不同的。
5.传递lambda表达式
C++传递lambda表达式的方法有以下几种:
- 将lambda表达式转换为相应的函数指针(如果没有捕获任何变量)。使用std::function作为参数类型,它可以接受任何可调用对象(包括捕获变量的lambda表达式)。
- 将lambda表达式赋值给一个变量,然后将这个变量传递给函数。
- 使用decltype来推导出lambda表达式的类型,然后将这个类型作为模板参数传递给函数。
传递lambda表达式的第一种方法
(将lambda表达式转换为相应的函数指针(如果没有捕获任何变量)。使用std::function作为参数类型,它可以接受任何可调用对象(包括捕获变量的lambda表达式)。)
对于第一种方法:要想将 lambda 表达式转换为函数指针,可以通过显式定义一个函数指针类型,然后用 lambda 表达式赋值给它。
但是,这需要满足两个条件:
1.lambda 表达式必须是静态的(即没有捕获任何变量)。
2.并且函数指针类型必须与 lambda 表达式的签名匹配。
考虑下面的示例:
#include <iostream>
int main() {
auto lambda = []() { std::cout << "Lambda function" << std::endl; };
// 将 lambda 表达式转换为函数指针
void (*funcPtr)() = lambda;
// 调用函数指针
funcPtr();
return 0;
}
输出:
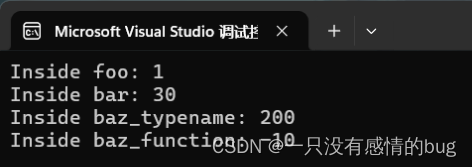
Lambda function三种方法的用例:
#include <iostream>
#include <functional>
void foo(std::function<bool(int)> f)
{
std::cout << "Inside foo: " << f(5) << std::endl;
}
void bar(std::function<int(int, int)> f)
{
std::cout << "Inside bar: " << f(10, 20) << std::endl;
}
void baz(std::function<int(int, int)> f)
{
std::cout << "Inside baz: " << f(10, 20) << std::endl;
}
template<typename F>
void baz(F f)
{
std::cout << "Inside baz: " << f(10, 20) << std::endl;
}
int main() {
// 传递lambda表达式给foo函数,
foo([](int x) { return x > 0; });
// 将lambda表达式赋值给变量add,并传递给bar函数
auto add = [](int a, int b) { return a + b; };
bar(add);
auto mul = [](int a, int b) { return a * b; };
std::function<int(int, int)> sub = [](int p, int q) { return p - q; };
//baz函数被重载,函数会根据类型调用更匹配的函数
baz<decltype(mul)>(mul);// 传递lambda表达式和它的类型给变量baz
baz(sub);//只传递表达式,类型由编译器自行推导
return 0;
}输出:
以set容器为例使用lambda表达式作为模板参数转递
下面以第三种方式为例:
(1).使用lambda 表达式
#include <iostream>
#include <set>
int main() {
auto cmp = [](int a, int b) {
return a > b;
};
std::set<int, decltype(cmp)> s(cmp); // 指定比较函数类型为 decltype(cmp)
// 向 set 容器中插入元素
s.insert(3);
s.insert(1);
s.insert(4);
// 遍历输出 set 容器中的元素
for (const auto& elem : s) {
std::cout << elem << " ";
}
std::cout << std::endl;
return 0;
}
输出:
4 3 1
(2).不指定排序方式,使用默认的排序方式:
std::set<int> s;输出:
1 3 4
(3).调用函数对象
#include <iostream>
#include <set>
// 自定义比较类
struct CustomCompare {
bool operator()(int a, int b) const {
return a > b;
}
};
int main() {
// 使用自定义比较类作为模板参数
std::set<int, CustomCompare> s;
// 向 set 容器中插入元素
s.insert(3);
s.insert(1);
s.insert(4);
// 遍历输出 set 容器中的元素
for (const auto& elem : s) {
std::cout << elem << " ";
}
std::cout << std::endl;
return 0;
}
输出:
4 3 1
(4).调用函数指针
bool compare(int a, int b) {
return a > b;
}
std::set<int, bool(*)(int, int)> s(&compare);
std::set模板需要两个参数:
元素类型 (
Key):指定集合中存储的元素类型。这是指定std::set类型的必需参数。比较函数类型 (
Compare):用于指定元素的排序方式。它可以是一个可调用对象,如函数指针、函数对象或 lambda 表达式。如果未提供该参数,则默认使用std::less<Key>,即默认按照<运算符进行元素比较。
(1)这段代码中使用了decltype是为了推断出lambda表达式的类型。decltype是一个C++11引入的关键字,它可以根据表达式的类型返回一个类型。在这个例子中,decltype(cmp)就是lambda表达式的类型,它被用作set容器的第二个模板参数,指定了set中元素的比较方式。set的第三个模板参数需要一个比较函数类型,而lambda表达式本身没有一个固定的类型,decltype可以根据lambda表达式的operator()来推导出它的函数类型,从而满足set的要求。
如果不使用decltype,就需要显式地写出lambda表达式的类型,但这很麻烦,因为lambda表达式的类型是编译器生成的,并没有一个具体的名字。你就需要自己定义一个比较类或者函数,并将其作为模板参数传递给std::set。
在这里暂不讨论泛型lambda表达式。(C++14引入的新特性)
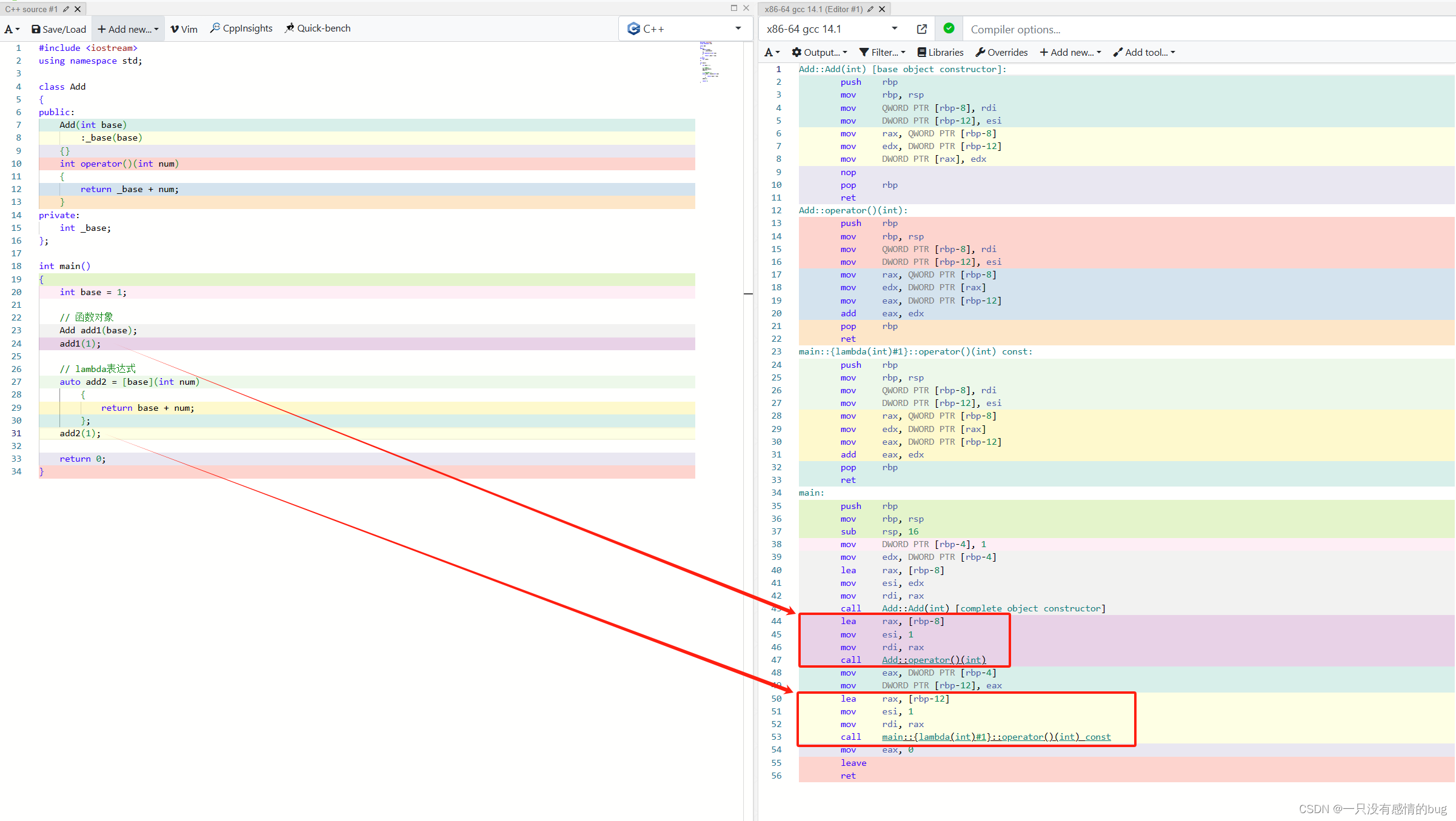
6.原理
class Add
{
public:
Add(int base)
:_base(base)
{}
int operator()(int num)
{
return _base + num;
}
private:
int _base;
};
int main()
{
int base = 1;
// 函数对象
Add add1(base);
add1(1);
// lambda表达式
auto add2 = [base](int num)
{
return base + num;
};
add2(1);
return 0;
}
网站链接:https://godbolt.org/
通过汇编代码,可以看到编译器处理lambda表达式的方式和处理函数对象相同。原因是C++的lambda表达式底层实现是一个类,它重载了operator()运算符,使得它可以像函数一样被调用。这个类还包含了lambda表达式捕获的变量,它们可以是值捕获或引用捕获。
一个lambda表达式产生一个临时对象,它可以用来初始化一个栈上的变量。这个对象有构造函数和析构函数,并且遵循所有C++规则。
这就是lambda表达式即使在上层看来名字相同也不能相互赋值的原因,编译器在底层给它们各自的函数对象的类起了不同的名字。例如在VS编译器中,具体类名为:lambda_uuid。
类名的 uuid (Universally Unique Identifier)是一个用于标识类的唯一标识符。
lambda_uuid即lambda表达式的类型。所以lambda表达式的“匿名”属性是对于使用者而言的,对于编译器来说是有名的。
7.内联属性
C++的lambda表达式是一种方便的定义匿名函数对象(Go语言中的闭包)的方法。
它可以在调用或作为参数传递给函数的地方直接定义。通常lambda表达式用于封装一些传递给算法或异步函数的代码。
C++11中引入了λ表达式,它可以用来定义一个**内联 (inline)**的函数,作为一个本地的对象或者一个参数。内联函数是一种编译器优化技术,它可以避免函数调用的开销,提高执行效率。λ表达式可以被编译器自动内联展开,从而减少函数调用的次数。但是,并不是所有的λ表达式都会被内联,这取决于编译器的实现和优化策略。
一般来说,lambda表达式会被内联的条件是:
- lambda表达式作为参数传递给一个内联函数
- lambda表达式没有被保存或者传递到其他地方
- lambda表达式没有从更外层的函数返回
如果不满足这些条件,可以使用noinline关键字来标记lambda参数,表示不要求内联。另外,编译器也会根据实现和优化策略来决定是否内联lambda表达式。
如果一个函数被调用的频率很低,甚至只有一次,那么内联属性使得它在被调用的位置展开,能减少调用函数创建栈帧的开销。lambda表达式的内联属性是默认的,只要编译器认为它可以在某处展开,那么它就像一个内嵌语句一样。
8.应用场景分类
STL 算法:Lambda 表达式经常与标准模板库(STL)中的算法一起使用,例如
std::for_each,std::transform,std::sort等。这些算法接受函数对象作为参数,Lambda 表达式提供了一种轻量级的方式来定义这些函数对象,从而使算法更加灵活和通用。容器操作:Lambda 表达式可以用于容器的各种操作,包括排序、查找、筛选、变换等。例如,使用 Lambda 表达式定义
std::set或std::map的比较函数,或者在范围遍历中使用 Lambda 表达式进行元素的处理。并发编程:在多线程编程中,Lambda 表达式可以用于创建线程函数或者传递任务给线程池。例如,在
std::thread或者std::async的构造函数中使用 Lambda 表达式定义线程函数。回调函数:Lambda 表达式常常用作回调函数,用于处理异步操作或者事件驱动的编程。例如,在 GUI 编程中,可以使用 Lambda 表达式作为按钮点击事件的处理函数。
函数对象的替代:Lambda 表达式可以替代简单的函数对象的定义,使代码更加简洁和易读。例如,在
std::function或者std::bind中使用 Lambda 表达式定义函数对象。延迟执行:Lambda 表达式可以用作延迟执行的一种方式,使得某些操作在需要时才被执行。例如,将 Lambda 表达式存储在
std::function对象中,然后在需要时调用它。
后面我会在不用的应用场景下进行说明。
那么今天的分享就到此结束,下期再见~




![[240512] x-cmd 发布 v0.3.6: (se,wkp,ddgo...)x( kimi,gemini,gpt...)](https://img-blog.csdnimg.cn/direct/f09b4b037c3d4fc69ce82f7278a79382.gif#pic_center)