目录
一、str函数的常见应用场景
二、str函数使用注意事项
三、如何用好str函数?
1、str函数:
1-1、Python:
1-2、VBA:
2、推荐阅读:
个人主页: https://myelsa1024.blog.csdn.net/



一、str函数的常见应用场景
str函数在Python中有着广泛的应用场景,主要用于将非字符串类型的对象转换为字符串类型,常见的应用场景有:
1、数据类型转换:当你需要将一个非字符串类型(如整数、浮点数、列表、元组、字典等)与字符串进行拼接或者需要以字符串的形式展示该对象时,可以使用str()函数。
2、日志记录:在程序运行时,你可能需要记录一些信息以便调试或追踪问题,使用str()函数可以将复杂的对象转换为字符串,然后写入日志文件中。
3、文件操作:当需要将数据写入文件时,通常需要先将数据转换为字符串。
4、网络编程:在网络编程中,发送和接收的数据通常是字节串(bytes),但在处理这些数据之前,可能需要先将它们转换为字符串。
5、数据库操作:在数据库操作中,经常需要将对象序列化为字符串,以便作为查询参数或存储到数据库中。
6、GUI编程:在图形用户界面(GUI)编程中,通常需要将对象的值以字符串的形式显示在标签、按钮或其他控件上。
7、JSON序列化:在将Python对象转换为JSON格式时,通常需要将对象转换为字符串,虽然直接使用json.dumps()更常见,但在某些情况下,你可能需要先使用str()函数将对象转换为字符串。
总之,str()函数在Python中几乎无处不在,是数据处理和交互中不可或缺的工具。

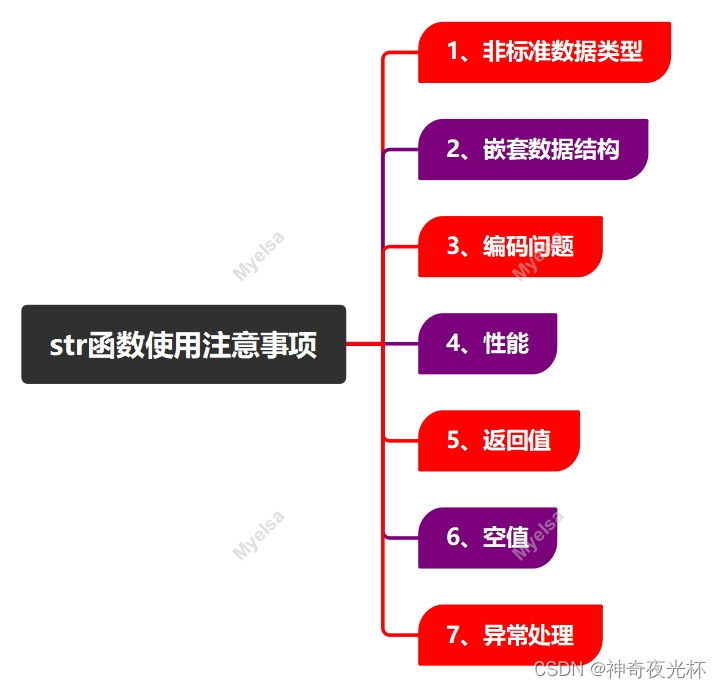
二、str函数使用注意事项
在Python中,str()函数用于将其他数据类型(如整数、浮点数、列表、元组、字典等)转换为字符串类型,然而,在使用str()函数时,需注意以下事项:
1、非标准数据类型:对于自定义的数据类型,Python不会自动知道如何将其转换为字符串,在这种情况下,你需要为该类型实现一个 `__str__()` 方法,该方法应返回一个表示该对象的字符串。
2、嵌套数据结构:当尝试将嵌套的数据结构(如包含其他列表或字典的列表)转换为字符串时,str()函数将返回一个表示该数据结构的字符串,但可能不是人类可读的。例如,列表将显示为[item1, item2, ...],字典将显示为{key1: value1, key2: value2, ...},如果你需要更详细的表示,可能需要使用其他方法(如json.dumps()来处理字典)。
3、编码问题:当处理包含非ASCII字符的字符串时,你需要确保你的代码环境(如文件编码、终端编码等)可以正确处理这些字符,否则,你可能会遇到编码错误或乱码。
4、性能:虽然str()函数通常很快,但如果你在处理大量数据或进行频繁的字符串转换,那么性能可能会成为一个问题,在这种情况下,你可能需要考虑使用其他方法来优化你的代码。
5、返回值:str()函数总是返回一个字符串,无论输入是什么,但是,这个字符串可能并不总是你期望的。例如,如果你期望得到一个表示日期的字符串,但你的输入是一个整数,那么str()函数将返回一个表示该整数的字符串,而不是日期。
6、空值:如果你尝试将None或其他空值(如空列表或空字典)转换为字符串,str()函数将返回一个表示该空值的字符串(如None、[]或 {})。
7、异常处理:尽管str()函数通常不会引发异常,但如果你尝试将其应用于不支持转换为字符串的对象(如文件对象或网络连接),那么可能会引发异常,在这种情况下,你应该使用适当的异常处理机制(如 `try/except` 块)来捕获和处理这些异常。
三、如何用好str函数?
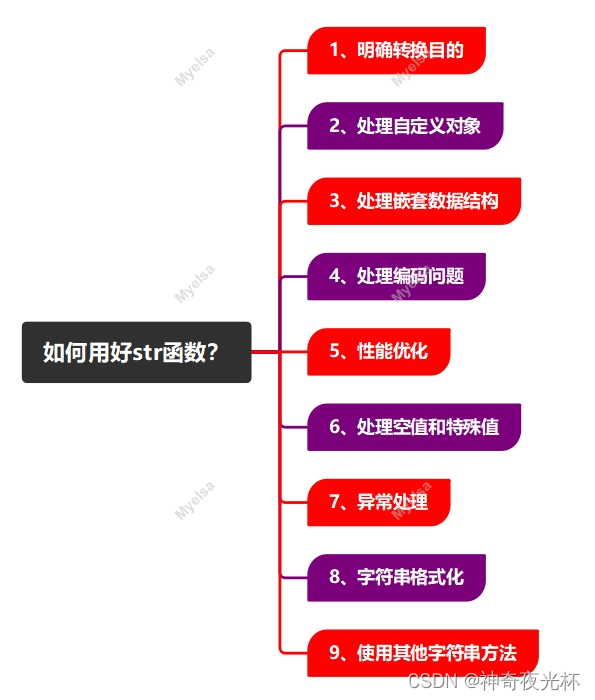
在Python中,str()函数是一个内置函数,用于将其他数据类型转换为字符串。为了用好str()函数,你应遵循以下建议:
1、明确转换目的:在调用str()函数之前,明确你为何需要将数据转换为字符串?是为了打印、日志记录、存储还是其他目的?这将有助于你选择最合适的转换方式。
2、处理自定义对象:如果你的代码中有自定义对象,并且你需要将它们转换为字符串,确保你已经为这些对象定义了`__str__()`方法,这样,当你调用str()函数时,它将返回由`__str__()`方法定义的字符串表示。
3、处理嵌套数据结构:当处理嵌套的数据结构(如列表、元组、字典等)时,str()函数将返回一个表示这些结构的字符串,如果你需要更详细或更易读的输出,可以考虑使用json.dumps()(对于字典和列表)或其他库来格式化输出。
4、处理编码问题:如果你的代码需要处理包含非ASCII字符的字符串,确保你的代码环境(如文件编码、终端编码等)可以正确处理这些字符,这可以通过在文件顶部指定编码(如`# -*- coding: utf-8 -*-`)或在读取和写入文件时使用正确的编码来实现。
5、性能优化:虽然str()函数通常很快,但在处理大量数据或进行频繁的字符串转换时,性能可能会成为问题,在这种情况下,你可以考虑使用其他方法来优化你的代码,如缓存已转换的字符串或避免不必要的转换。
6、处理空值和特殊值:当使用str()函数转换空值(如None、空列表或空字典)时,请注意返回的字符串表示(如None、[]或{}),确保你的代码可以正确处理这些值。
7、异常处理:虽然str()函数通常不会引发异常,但当应用于不支持转换为字符串的对象时,可能会引发异常,使用`try/except`块来捕获和处理这些异常,以确保你的代码可以优雅地处理错误情况。
8、字符串格式化:除了简单的类型转换外,str()函数还可以与字符串格式化结合使用,你可以使用格式化字符串字面值(f-strings,从Python 3.6开始支持)来嵌入变量和表达式,并使用str()函数来转换非字符串值。
9、使用其他字符串方法:一旦你将数据转换为字符串,你就可以使用Python中丰富的字符串方法来处理它,如split()、replace()、upper()、lower()等,这些方法可以帮助你进一步处理和操作字符串数据。
1、str函数:
1-1、Python:
# 1.函数:str
# 2.功能:
# 2-1、用于将整数、浮点数、列表、元组、字典和集合等转换为字符串类型
# 2-2、用于将字节类型转换为字符串类型
# 3.语法:
# 3-1、str([object=''])
# 3-2、str(object=b''[, encoding='utf-8', errors='strict'])
# 4.参数:
# 4-1、object:表示被转换成字符串的参数,可省略
# 4-2、参数说明如下:
# 4-2-1、object=b'':表示要进行转换的字节型(bytes)数据
# 4-2-2、encoding:表示进行转换时所采用的编码方式,默认为UTF-8
# 4-2-3、errors(可选):表示读写文件时遇到错误的报错级别
# 4-2-3-1、strict:严格级别,字符编码有报错即抛出异常,默认级别,errors传入None即按此级别处理
# 4-2-3-2、ignore:忽略级别,字符编码有错误,忽略掉
# 4-2-3-3、replace:替换级别,字符编码有错的,替换成符号“?”
# 5.返回值:返回一个object对象的字符串形式;若省略参数,则返回空字符串,常用来创建空字符串或初始化字符串变量
# 6.说明:
# 7.示例:
# 用dir()函数获取该函数内置的属性和方法
print(dir(str))
# ['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__',
# '__getattribute__', '__getitem__', '__getnewargs__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__',
# '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__',
# '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold',
# 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha',
# 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper',
# 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'removeprefix', 'removesuffix', 'replace', 'rfind', 'rindex',
# 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
# 用help()函数获取该函数的文档信息
help(str)
# 应用一:数据类型转换
# 示例1: 将整数转换为字符串
# 定义一个整数
num = 1024
# 使用str()函数将整数转换为字符串
str_num = str(num)
# 打印结果
print(type(num))
print("整数:", num)
print(type(str_num))
print("字符串:", str_num)
# <class 'int'>
# 整数: 1024
# <class 'str'>
# 字符串: 1024
# 示例2: 将浮点数转换为字符串
# 定义一个浮点数
float_num = 3.14159
# 使用str()函数将浮点数转换为字符串
str_float_num = str(float_num)
# 打印结果
print(type(float_num))
print("浮点数:", float_num)
print(type(str_float_num))
print("字符串:", str_float_num)
# <class 'float'>
# 浮点数: 3.14159
# <class 'str'>
# 字符串: 3.14159
# 示例3: 将列表转换为字符串(默认表示)
# 定义一个列表
my_list = [1, 2, 3, 'four']
# 使用str()函数将列表转换为字符串(默认表示)
str_list = str(my_list)
# 打印结果
print(type(my_list))
print("列表:", my_list)
print(type(str_list))
print("字符串:", str_list) # 注意,这里会得到类似'[1, 2, 3, "four"]'的结果
# <class 'list'>
# 列表: [1, 2, 3, 'four']
# <class 'str'>
# 字符串: [1, 2, 3, 'four']
# 示例4: 将字典转换为字符串(默认表示)
# 定义一个字典
my_dict = {'name': 'Myelsa', 'age': 18}
# 使用str()函数将字典转换为字符串(默认表示)
str_dict = str(my_dict)
# 打印结果
print(type(my_dict))
print("字典:", my_dict)
print(type(str_dict))
print("字符串:", str_dict) # 注意,这里会得到类似'{"name": "Myelsa", "age": 18}'的结果
# <class 'dict'>
# 字典: {'name': 'Myelsa', 'age': 18}
# <class 'str'>
# 字符串: {'name': 'Myelsa', 'age': 18}
# 示例5: 将自定义对象转换为字符串(需要定义__str__方法)
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return f"Person(name={self.name}, age={self.age})"
# 创建一个自定义对象
p = Person("Bruce", 6)
# 使用str()函数将自定义对象转换为字符串
str_person = str(p)
# 打印结果
print(type(p))
print("Person对象:", p) # 这里Python会调用__str__方法返回字符串
print(type(str_person))
print("字符串:", str_person)
# <class '__main__.Person'>
# Person对象: Person(name=Bruce, age=6)
# <class 'str'>
# 字符串: Person(name=Bruce, age=6)
# 示例6: 使用str()和格式化字符串(f-string)
# 定义一个整数和一个字符串
num = 42
text = "answer"
# 使用f-string和str()函数将整数和字符串组合
combined_str = f"The {text} is {str(num)}."
# 打印结果
print(combined_str)
# The answer is 42.
# 应用二:日志记录
# 示例1: 使用Python内置的print()函数进行简单的日志记录
# 假设我们有一些数据
data = {'name': 'Myelsa', 'age': 18, 'score': 98}
# 使用str()函数将字典转换为字符串,并使用print()输出到控制台作为日志
print(f"Processing data: {str(data)}")
# 进行一些操作...
# 假设处理完成,记录结果
result = "Data processed successfully."
print(f"Result: {result}")
# Processing data: {'name': 'Myelsa', 'age': 18, 'score': 98}
# Result: Data processed successfully.
# 示例2: 使用logging模块进行更复杂的日志记录
import logging
# 配置logging模块
logging.basicConfig(filename='app.log', level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# 假设我们有一些数据
data = {'name': 'Jimmy', 'age': 15, 'score': 96.0}
# 使用str()函数将字典转换为字符串,并使用logging模块记录到日志文件中
logging.info(f"Processing data: {str(data)}")
# 进行一些操作...
# 假设处理过程中发生了异常
try:
# 模拟一个可能引发异常的操作
1 / 0
except ZeroDivisionError as e:
# 使用str()函数将异常对象转换为字符串,并记录到日志文件中
logging.error(f"An error occurred: {str(e)}")
# 假设处理完成,记录结果
result = "Data processed with an error."
logging.info(f"Result: {result}")
# 应用三:文件操作
# 示例1: 将非字符串数据写入文件
# 假设我们有一些非字符串数据
numbers = [3, 5, 6, 8, 10, 10, 11, 24]
# 将列表转换为字符串(这里使用join方法将列表元素连接成字符串)
numbers_str = ', '.join(map(str, numbers))
# 将字符串写入文件
with open('numbers.txt', 'w') as file:
file.write(numbers_str)
# 示例2: 从文件中读取并处理非字符串数据
# 打开文件并读取内容
with open('numbers.txt', 'r') as file:
content = file.read() # 读取整个文件内容,此时是一个字符串
# 使用split方法将字符串分割成列表(假设数字之间由逗号分隔)
numbers_str_list = content.split(', ')
# 将字符串列表中的每个元素转换为整数,并存储在新的列表中
numbers_list = [int(num) for num in numbers_str_list]
# 输出结果
print(numbers_list)
# [3, 5, 6, 8, 10, 10, 11, 24]
# 示例3: 读取和写入包含多种数据类型的文件(使用JSON)
import json
# 假设我们有一个包含多种数据类型的字典
data = {
'name': 'Myelsa',
'age': 18,
'scores': [85, 90, 95]
}
# 将字典写入JSON文件(自动处理数据类型转换)
with open('data.json', 'w') as file:
json.dump(data, file)
# 从JSON文件中读取数据并转换回Python对象
with open('data.json', 'r') as file:
loaded_data = json.load(file)
# 输出结果
print(loaded_data) # 输出与原始data字典相同的内容
# 应用四:网络编程
# 示例1: 使用socket发送和接收字符串数据
import socket
# 创建socket对象
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 连接到远程服务器
server_address = ('localhost', 12345)
s.connect(server_address)
# 发送数据(先将整数转换为字符串)
data_to_send = str(42)
s.sendall(data_to_send.encode()) # 发送前需要编码为字节串
# 接收数据
data = s.recv(1024) # 接收最多1024字节的数据
print('Received', repr(data.decode())) # 解码为字符串并打印
# 关闭连接
s.close()
# 示例2: 发送和接收字典类型的数据(先转换为JSON字符串)
import socket
import json
# 创建socket对象
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 假设我们有一个字典需要发送
data_dict = {'name': 'Myelsa', 'age': 18}
# 连接到远程服务器
server_address = ('localhost', 12345)
s.connect(server_address)
# 将字典转换为JSON字符串
data_to_send = json.dumps(data_dict)
# 发送JSON字符串(需要先编码为字节串)
s.sendall(data_to_send.encode())
# 接收数据(假设服务器返回的是JSON字符串)
data = s.recv(1024)
# 将接收到的字节串解码为字符串,并使用json.loads()转换为字典
received_dict = json.loads(data.decode())
print('Received:', received_dict)
# 关闭连接
s.close()
# 示例3: 使用requests库发送HTTP请求(自动处理数据类型转换)
import requests
# 发送GET请求
response = requests.get('https://myelsa1024.blog.csdn.net/')
# 假设响应的内容是JSON格式,我们可以直接将其解析为Python字典
data = response.json()
# 打印数据
print(data)
# 应用五:数据库操作
import sqlite3
# 连接到SQLite数据库(如果不存在则创建)
conn = sqlite3.connect('example.db')
c = conn.cursor()
# 创建一个表(如果表已存在,请忽略此步骤)
c.execute('''CREATE TABLE IF NOT EXISTS users
(id INTEGER PRIMARY KEY, name TEXT, age INTEGER, address TEXT)''')
# 假设我们有一些非字符串数据
user_data = {'name': 'Alice', 'age': 30, 'address': '123 Main St'}
# 使用str()函数将非字符串数据转换为字符串(但请注意,这通常不是推荐做法)
# 在实际应用中,应该使用参数化查询
insert_query = "INSERT INTO users (name, age, address) VALUES (?, ?, ?)"
# 注意:这里我们使用?作为占位符,而不是直接将字符串插入查询中
c.execute(insert_query, (str(user_data['name']), str(user_data['age']), str(user_data['address'])))
# 注意:将整数转换为字符串并插入到INTEGER列中是不正确的。这里仅为了演示str()的使用。
# 使用参数化查询插入数据(推荐做法)
# insert_query = "INSERT INTO users (name, age, address) VALUES (?, ?, ?)"
# c.execute(insert_query, (user_data['name'], user_data['age'], user_data['address']))
# 在实际应用中,应该直接插入整数,而不是字符串化的整数。
# 提交事务
conn.commit()
# 关闭连接
conn.close()
# 应用六:GUI编程
import tkinter as tk
def show_data(data):
# 使用str()函数将非字符串数据转换为字符串
label_text = str(data)
# 更新标签的文本
label.config(text=label_text)
# 创建主窗口
root = tk.Tk()
root.title("str() in GUI Programming")
# 创建一个标签用于显示数据
label = tk.Label(root, text="Initial Text")
label.pack(pady=20)
# 创建一个按钮,点击时调用show_data函数并传递一个非字符串数据
button = tk.Button(root, text="Show Data", command=lambda: show_data(42))
button.pack(pady=20)
# 启动主循环
root.mainloop()
# 应用七:JSON序列化
import json
# 假设我们有一个包含非字符串类型数据的字典
data = {
'name': 'Jimmy',
'age': 15, # 整数
'is_student': False, # 布尔值
'scores': [92, 96, 98], # 列表包含整数
'info': {'hobby': 'reading', 'city': 'Foshan'} # 嵌套字典
}
# 使用json.dumps()进行JSON序列化
json_string = json.dumps(data)
# 打印序列化后的JSON字符串
print(type(json_string))
print(json_string)
# 注意:在上面的过程中,json.dumps()会自动处理数据类型,将整数、布尔值等转换为JSON字符串中的相应表示形式。
# 这并不是直接使用str()函数,但你可以看到类似的效果,因为json.dumps()内部可能会使用到str()的类似功能。
# 如果你尝试直接使用str()来序列化字典,你会得到一个不同的结果,因为str()只是将对象转换为字符串的“表示形式”,而不是有效的JSON:
print(type(data))
print(str(data)) # 这将打印字典的Python字符串表示,而不是JSON格式
# <class 'str'>
# {"name": "Jimmy", "age": 15, "is_student": false, "scores": [92, 96, 98], "info": {"hobby": "reading", "city": "Foshan"}}
# <class 'dict'>
# {'name': 'Jimmy', 'age': 15, 'is_student': False, 'scores': [92, 96, 98], 'info': {'hobby': 'reading', 'city': 'Foshan'}}1-2、VBA:
略,待后补。2、推荐阅读:
2-1、Python-VBA函数之旅-format()函数
Python算法之旅:Algorithms
Python函数之旅:Functions


![[单机]成吉思汗3_GM工具_VM虚拟机](https://img-blog.csdnimg.cn/img_convert/ee9be78a18d7d5bc082500017469ba5b.webp?x-oss-process=image/format,png)