前言
最近还是衔接着之前的学习记录,这次打算开始学习模仿学习的相关原理,参考的开源资料为
TeaPearce/Counter-Strike_Behavioural_Cloning: IEEE CoG & NeurIPS workshop paper ‘Counter-Strike Deathmatch with Large-Scale Behavioural Cloning’ (github.com)
[2104.04258] Counter-Strike Deathmatch with Large-Scale Behavioural Cloning (arxiv.org)
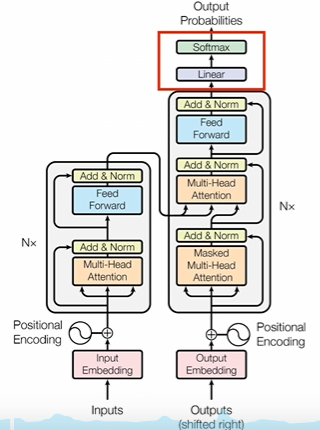
简单来说,行为克隆就是利用已有的人为示范数据作为输入来训练出一个策略,策略就会输出指定的动作,然而,行为克隆只能学习到专家的行为,而无法进行探索和自主学习。这意味着行为克隆的性能受限于专家的行为水平,并且可能无法适应新的、未在专家演示中出现过的情况。通过引入奖励函数,可以在行为克隆中加入一定的探索和自主学习能力。奖励函数可以根据当前状态和采取的动作来评估行为的好坏,并为模型提供反馈信号。通过优化奖励函数,可以使模型学习到更好的策略,并且能够适应新的情况和环境。奖励函数在行为克隆中起到了指导和调整模型学习的作用。其中,文章用到的例程的网络结构如下

本文打算从数据获取、模型训练、效果展示三个部分展开介绍
数据获取
在这个过程中作者使用了Game State Integration(GSI)技术来获取在线数据。通过GSI,作者可以从游戏中获取实时的游戏状态信息,包括玩家、队伍、武器、位置等各种数据。具体来说,作者可能使用了Valve提供的GSI接口来获取游戏状态信息。这些信息可以用于后续的行为克隆和分析工作。
这个过程中的核心代码如下
# now find the requried process and where two modules (dll files) are in RAM
hwin_csgo = win32gui.FindWindow(0, ('counter-Strike: Global Offensive'))
if(hwin_csgo):
pid=win32process.GetWindowThreadProcessId(hwin_csgo)
handle = pymem.Pymem()
handle.open_process_from_id(pid[1])
csgo_entry = handle.process_base
else:
print('CSGO wasnt found')
os.system('pause')
sys.exit()
# now find two dll files needed
list_of_modules=handle.list_modules()
while(list_of_modules!=None):
tmp=next(list_of_modules)
# used to be client_panorama.dll, moved to client.dll during 2020
if(tmp.name=="client.dll"):
print('found client.dll')
off_clientdll=tmp.lpBaseOfDll
break
list_of_modules=handle.list_modules()
while(list_of_modules!=None):
tmp=next(list_of_modules)
if(tmp.name=="engine.dll"):
print('found engine.dll')
off_enginedll=tmp.lpBaseOfDll
break
大致逻辑为:
-
查找CSGO进程:
- 使用
win32gui.FindWindow查找名为’counter-Strike: Global Offensive’的窗口句柄。 - 如果找到窗口句柄,则通过
win32process.GetWindowThreadProcessId获取与该窗口关联的进程ID。 - 使用
pymem.Pymem()创建一个进程内存访问对象,并通过open_process_from_id方法打开该进程。 - 如果CSGO进程未找到,则打印消息并退出程序。
- 使用
-
查找client.dll和engine.dll:
- 使用
handle.list_modules()获取进程中的所有模块列表。 - 遍历模块列表,查找名为"client.dll"的模块,并获取动态链接库的基地址(
lpBaseOfDll)。 - 注意:这里使用了两次
handle.list_modules()来分别查找两个DLL文件,但实际上你可以只调用一次并将结果存储在列表中,然后遍历这个列表来查找两个DLL。 - 类似地,代码还查找名为"engine.dll"的模块,并获取其基地址。
- 使用
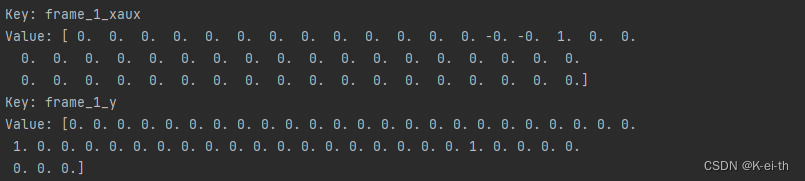
找到窗口和动态链接库以后就可以开始录像并通过GSI或者RAM来访问键位等游戏信息,得到的数据类型大致为
- frame_i_x: 图像信息
- frame_i_xaux: 包含在前一个时间步骤中应用的动作,以及血量、弹药和团队。用于更好地帮助智能体寻找敌人以及适应当前情况
- frame_i_y: 对应键盘以及鼠标的动作
- frame_i_helperarr: 在格式kill_flag, death_flag中,每个变量都是二元变量,例如[[1,0]],意味着玩家击杀一次,但在该时间步内没有死亡
其中,具体的键位信息如下:
# how many slots were used for each action type?
n_keys = 11 # number of keyboard outputs, w,s,a,d,space,ctrl,shift,1,2,3,r
n_clicks = 2 # number of mouse buttons, left, right
n_mouse_x = len(mouse_x_possibles) # number of outputs on mouse x axis
n_mouse_y = len(mouse_y_possibles) # number of outputs on mouse y axis
n_extras = 3 # number of extra aux inputs, eg health, ammo, team. others could be weapon, kills, deaths
aux_input_length = n_keys+n_clicks+1+1+n_extras # aux uses continuous input for mouse this is multiplied by ACTIONS_PREV elsewhere
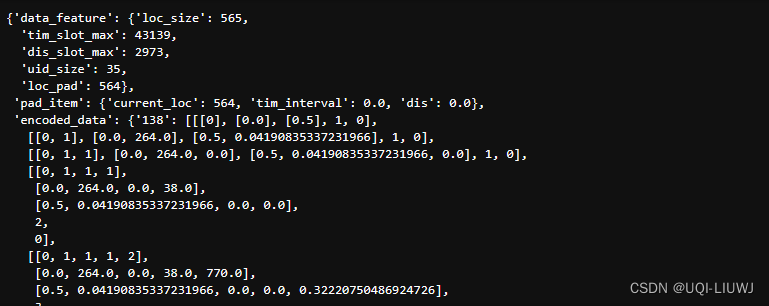
一个帧所包含的具体信息值如下:

模型训练
网络结构
输入先进入一个预训练好的EfficientNetB0模型,该模型在ImageNet数据集上进行了训练。并加上了时间序列信息,接下来将提取好的特征输入进一个带有时序信息的ConvLSTM网络
base_model = EfficientNetB0(weights='imagenet',input_shape=(input_shape[1:]),include_top=False,drop_connect_rate=0.2)
if 'drop' in model_name:
if 'big' in model_name:
x = ConvLSTM2D(filters=512,kernel_size=(3,3),stateful=False,return_sequences=True,dropout=0.5, recurrent_dropout=0.5)(x)
else:
x = ConvLSTM2D(filters=256,kernel_size=(3,3),stateful=False,return_sequences=True,dropout=0.5, recurrent_dropout=0.5)(x)
输出的信息为
# set up outputs, sepearate outputs will allow seperate losses to be applied
output_1 = TimeDistributed(Dense(n_keys, activation='sigmoid'))(dense_5)
output_2 = TimeDistributed(Dense(n_clicks, activation='sigmoid'))(dense_5)
output_3 = TimeDistributed(Dense(n_mouse_x, activation='softmax'))(dense_5) # softmax since mouse is mutually exclusive
output_4 = TimeDistributed(Dense(n_mouse_y, activation='softmax'))(dense_5)
output_5 = TimeDistributed(Dense(1, activation='linear'))(dense_5)
# output_all = concatenate([output_1,output_2,output_3,output_4], axis=-1)
output_all = concatenate([output_1,output_2,output_3,output_4,output_5], axis=-1)
损失函数
- 键盘按键损失(
loss1a,loss1b,loss1c,loss1d):loss1a:计算 WASD 键(通常用于游戏中的移动)的二进制交叉熵损失。loss1b:计算空格键的二进制交叉熵损失。loss1c:计算重新加载键(如游戏中的“R”键)的二进制交叉熵损失。loss1d(注释掉的部分):原本可能用于计算其他键盘按键的损失,但在提供的代码中,它被重新定义为武器切换键(1, 2, 3)的损失。
- 鼠标点击损失(
loss2a,loss2b):loss2a:计算鼠标左键点击的二进制交叉熵损失。loss2b:计算鼠标右键点击的二进制交叉熵损失(如果n_clicks大于1的话)。
- 鼠标移动损失(
loss3,loss4):loss3:计算鼠标在 X 轴上的移动损失。由于鼠标移动是互斥的(即鼠标不能同时处于多个位置),因此使用了分类交叉熵损失(categorical_crossentropy)。loss4:计算鼠标在 Y 轴上的移动损失,同样使用了分类交叉熵损失。
除此之外,还有一个loss_crit损失函数,
loss_crit = 10*losses.MSE(y_true[:,:-1,n_keys+n_clicks+n_mouse_x+n_mouse_y:n_keys+n_clicks+n_mouse_x+n_mouse_y+1]
+ GAMMA*y_pred[:,1:,n_keys+n_clicks+n_mouse_x+n_mouse_y:n_keys+n_clicks+n_mouse_x+n_mouse_y+1]
,y_pred[:,:-1,n_keys+n_clicks+n_mouse_x+n_mouse_y:n_keys+n_clicks+n_mouse_x+n_mouse_y+1])
这是一个基于时序差分(Temporal Difference, TD)的均方误差(Mean Squared Error, MSE)损失函数,用于强化学习中的值函数逼近。它计算了当前时间步的奖励(或值)与下一个时间步的预测奖励(或值)之和(经过折扣因子 GAMMA 调整后)与当前时间步的预测奖励(或值)之间的均方误差。这种损失函数允许神经网络学习如何根据当前状态和环境信息来预测未来的奖励或值,从而优化策略或值函数。在这个特定的实现中,损失还乘以了一个系数(如10),可能是为了调整该损失在总损失中的相对权重。
奖励函数如下,奖励为 R(杀敌数,死亡数,子弹数)
reward_i = kill_i - 0.5*dead_i - 0.01*shoot_i # this is reward function
y[i,j,-2:] = (reward_i,0.) # 0. is a placeholder for original advantage
效果展示
通过e2e.yml文件配置虚拟环境,更改了游戏内的窗口分辨率,设置了一些其他的参数,运行dm_run_agent.py以后在自己的电脑上成功复现
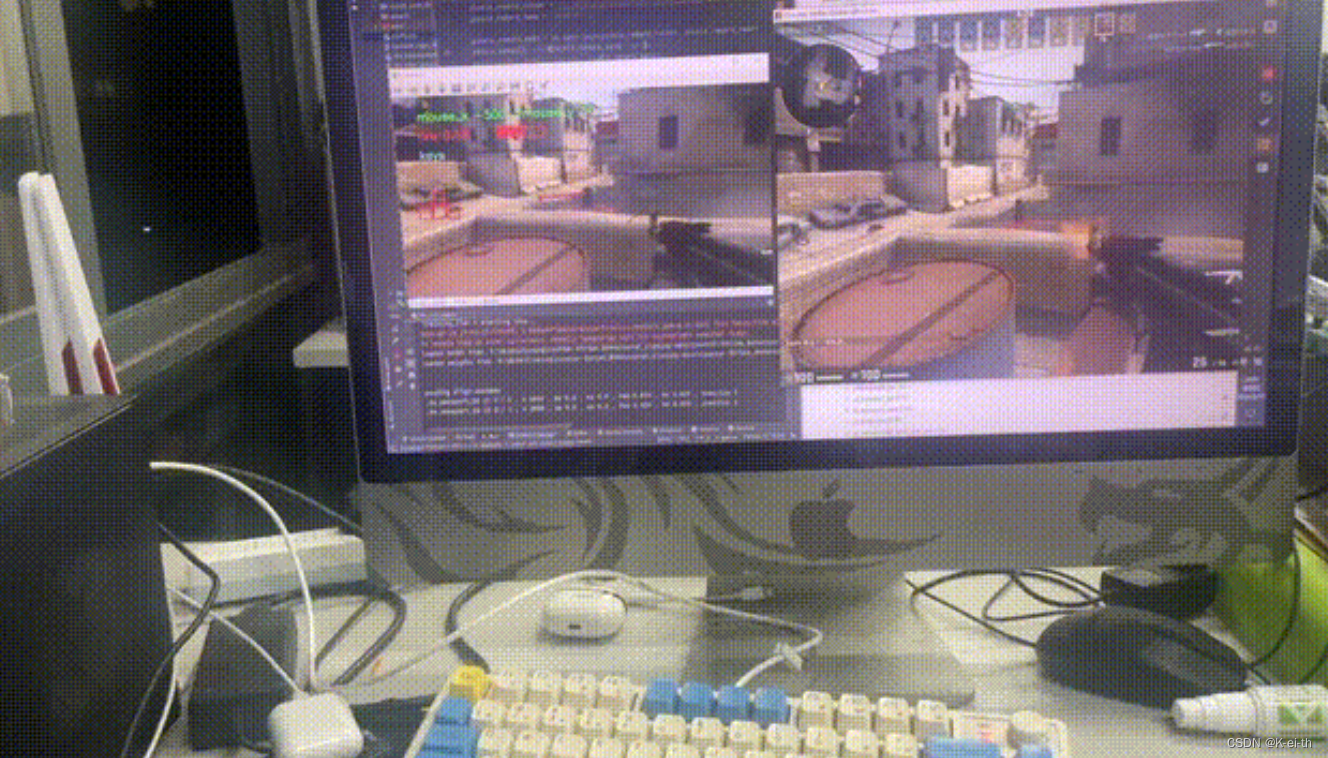
总结
本次基于Counter-Strike Deathmatch with Large-Scale Behavioural Cloning这个开源项目系统地学习了一下行为克隆的基本流程,从数据采集、模型训练以及损失函数的定义到最终复现,拓宽了我对RL的认知,在日后也能够更好地迁移到Robotic,逻辑如下:
- 数据收集:首先,需要收集人类专家在特定任务中的行为数据。这些数据通常包括机器人所处的状态(如位置、姿态、环境信息等)以及对应的人类专家在该状态下所采取的动作(如移动方向、操作指令等)。这些数据构成了行为克隆算法的训练集。
- 模型训练:使用收集到的数据训练一个模型,如神经网络模型。这个模型将学习从状态到动作的映射关系,即根据机器人当前的状态预测应该执行的动作。在训练过程中,模型会不断优化其参数,以最小化预测动作与真实动作之间的差异。
- 模型部署:训练好的模型可以部署到机器人上,用于指导机器人的行为。当机器人遇到新的状态时,它会将当前状态输入到模型中,模型会输出一个预测的动作。机器人将根据这个预测的动作来执行相应的操作。
- 反馈与调整:在机器人执行动作的过程中,可以通过收集反馈信息来进一步调整模型。例如,可以观察机器人执行动作后的效果,如果效果不理想,则可以收集新的数据并重新训练模型,以提高其性能。
![[单机]成吉思汗3_GM工具_VM虚拟机](https://img-blog.csdnimg.cn/img_convert/ee9be78a18d7d5bc082500017469ba5b.webp?x-oss-process=image/format,png)