XML
- XML的定义和概述
- 🎶XML的定义
- 🎶XML的最好描述
- 🎶HTML和XML的重要区别
- 🎶XML的文档结构
- 🎶其他一些标记
- XML和优势
- 🎶XML的优势
- XML解析
- 🎶DOM解析
- ❔解析测试
- 🤞解析步骤
- 🤞案例测试
- 🎶SAX解析
- 🎶DOM4J解析
- ❔解析步骤
XML的定义和概述
🎶XML的定义
XML是Extensible Makeup Language的缩写,是指可拓展性标记语言,用来传输和存储数据的一种标记语言。类似于HTML,XML弥补了HTML不能指定文档结构的不足,XML被设计为具有自我描述性,其宗旨是传输数据。HTML和XML同宗同源于SGML(标准通用标记语言)。
🎶XML的最好描述
独立于软件和硬件的信息传输工具。
🎶HTML和XML的重要区别
- XML被设计来传输和存储数据,焦点是数据的内容,而HTML被设计来显示数据,焦点是数据的外观。
- XML中区分大小写。例如:
<setting>和<Setting>是不同的标签。 - XML中的结束标志是绝对不能省略的,即使是没有结束标签也要以
'/'结尾。 - XML中属性值必须要用引号括起来,单引号双引号都行。
- XML中属性名不能没有值。例如:HTML中
<input type="text" name="username" checked />在XML中是不合法的。 - XML可以自定义标签和文档结构。
🎶XML的文档结构
第一步:使用文档头,文档头是可选的,但强烈建议使用。
<?xml version="1.0" ?>
或
<?xml version="1.0" encoding="UTF-8" ?>
第二步:使用 文档类型定义(Document Type Definition),用来确保文档正确的一个重要机制,非必须。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration...>
<configuration>
...
</configuration>
第三步:写出根节点,即其内部内容(子节点,内容,属性...)元素的属性值一般是对元素内容的解释。
🎶其他一些标记
- 处理指令,是那些专门在处理XML文档的应用程序中使用的指令,它们由
<?和?>来限定其界限。
<?xml-stylesheet href="mystyle.css" type="text/css"?>
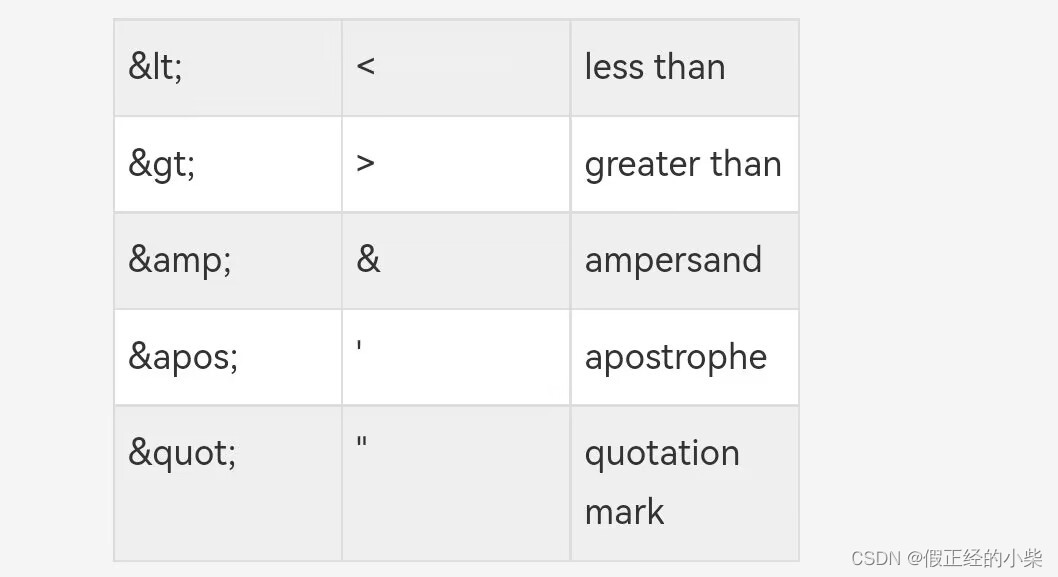
- 实体引用,使用实体引用代替一些字符是一种好习惯。
XML和优势
🎶XML的优势
1. 解决了属性文件的局限性,属性文件是一种平面表结构,而XML可以表示层次结构;
// 属性文件内容
title.fontname=hhh
title.fontsize=12
menu.item.1=x
menu.item.2=y
// 对应的XML文件内容
<configuration>
<title>
<font>
<name>hhh</name>
<size>12</size>
</font>
</title>
<menu>
<item>x</item>
<item>y</item>
</menu>
</configuration>
XML解析
🎶DOM解析
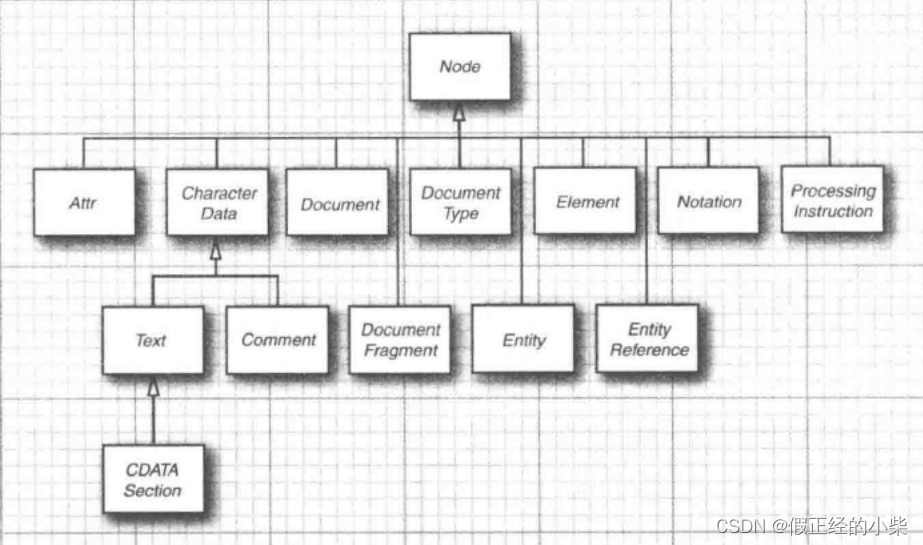
DOM解析器可以把 xml 文档转换成树结构,对其树结构上的各个元素进行读取。
DOM解析器的接口已被W3C标准化了,org.w3c.dom包中包含了这些接口的定义。(Document、Element等)。
这是各个子接口的层次结构:
❔解析测试
🤞解析步骤
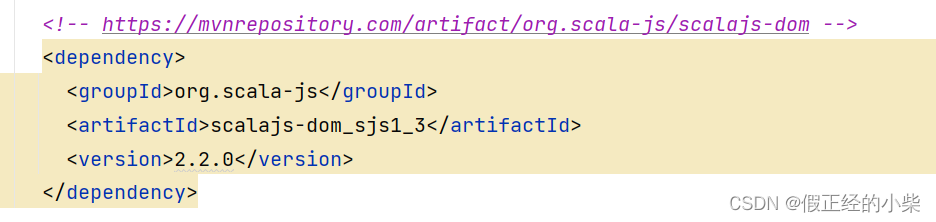
- 导入dom依赖(本地库没有,可以去中央仓库找找)
- 读入一个XML文档,需要一个
DocumentBuilder对象。
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
- 然后开始读入文档(可以是File、URL或者某输入流)
// File(项目根路径)
Document doc = builder.parse(new File("src/main/....");
// InputStream (类的根路径)
Document doc = builder.parse(ClassLoader.getSystemClassLoader().getResourceAsStream(...);
- 开始解析
一些解析可用的方法:
Document接口:
Element getDocumentElement() 返回文档的根元素。
Element接口:
String getTagName() 返回元素名字
String getAttribute(String name) 返回给定名字的属性值,没有该属性是返回空字符串。
Node接口:
NodeList getChildNodes() 返回包含该节点所有子元素的节点列表
Node getFirstChild()
Node getLastChild()
CharacterData接口:
String getData() 返回存储在节点中的文本。返回的是一个CharacterData和Text存在继承关系,而CharacterData继承于Node,一般取文本内容,是将Node向下转型为Text,再去getData()获取文本内容。
NodeList接口:
int getLength() 返回列表中的节点数
Node item(int index) 返回索引值处的节点
🤞案例测试
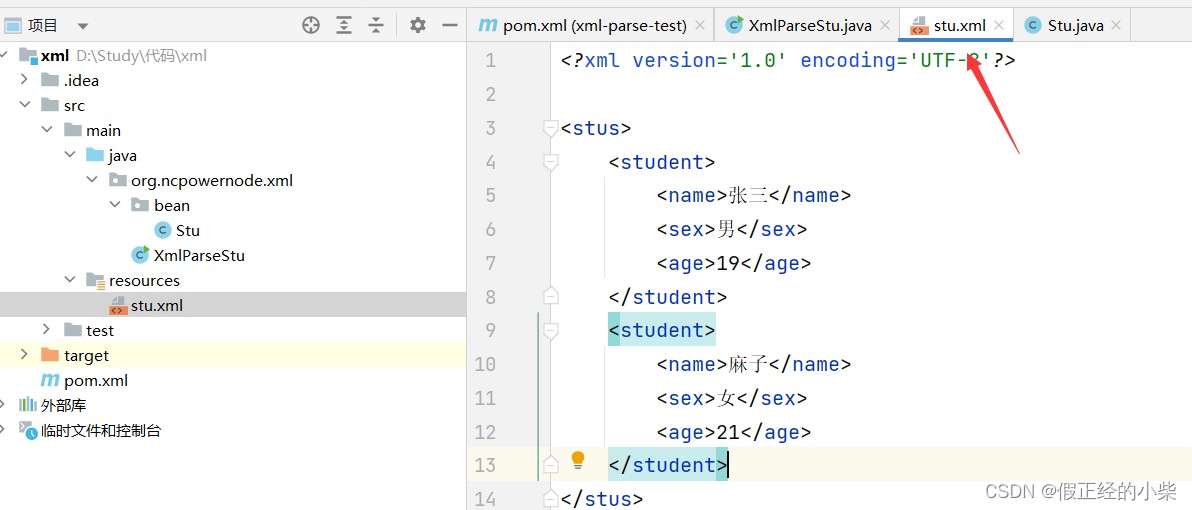
一、创建个xml文件,下面是文件内容:
二、预期把这些信息都解析成Javabean Stu对象,下面是Stu类中的代码:
import java.util.Objects;
public class Stu {
private String name;
private String sex;
private int age;
public Stu(){}
public Stu(String name, String sex, int age) {
this.name = name;
this.sex = sex;
this.age = age;
}
@Override
public String toString() {
return "Stu{" +
"name='" + name + '\'' +
", sex='" + sex + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
Stu stu = (Stu) o;
return age == stu.age && Objects.equals(name, stu.name) && Objects.equals(sex, stu.sex);
}
@Override
public int hashCode() {
return Objects.hash(name, sex, age);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
三、通过上面认识到的接口方法,对该xml文件进行解析:
import org.ncpowernode.xml.bean.Stu;
import org.w3c.dom.*;
import org.xml.sax.SAXException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
public class XmlParseStu {
private static File f = new File("src/main/resources/stu.xml");
private static InputStream in = ClassLoader.getSystemClassLoader().getResourceAsStream("stu.xml");
private static List<Stu> stuList = new ArrayList<>();
public static void main(String[] args)
throws ParserConfigurationException, IOException, SAXException {
DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder documentBuilder = documentBuilderFactory.newDocumentBuilder();
Document stuDocument = documentBuilder.parse(in);
Element beginRoot = stuDocument.getDocumentElement();
NodeList childNodes = beginRoot.getChildNodes();
List<Element> nodeList = new ArrayList<>();
// 将student 节点元素存入到nodelist集合中
for(int i=0;i<childNodes.getLength();++i){
Node node = childNodes.item(i);
if (node instanceof Element) {
Element element = (Element) node;
nodeList.add(element);
}
}
//nodeList.stream().forEach(node->System.out.println(node.getNodeName()));
nodeList.stream()
.forEach(element -> {
NodeList childs = element.getChildNodes();
String name="";
String sex="";
int age=0;
for(int i=0;i<childs.getLength();++i){
Node item = childs.item(i);
if (item instanceof Element) {
Element e = (Element)item;
Text text = (Text)item.getFirstChild();
String data = text.getData().trim();
String tagName = e.getTagName();
if(tagName.equals("name")){
name = data;
}else if(tagName.equals("sex")){
sex = data;
}else if(tagName.equals("age")){
age = Integer.parseInt(data);
}
}
}
Stu stu = new Stu(name,sex,age);
System.out.println(stu);
});
}
}
输出结果:
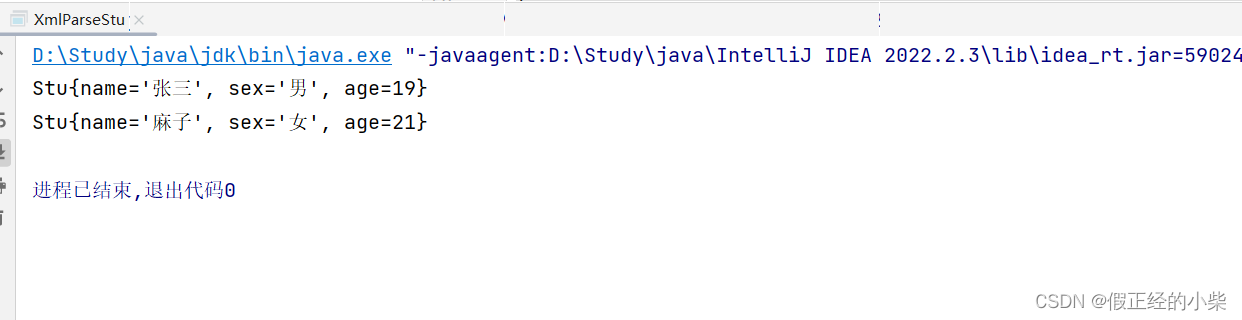
注意:这是自编题自解答,同一问题这个一步一步写的不一定是一最好的解析代码。DOM解析xml不适合元素很多的文档,那样parse成树后会占用很大内存。
🎶SAX解析
SAX解析适合解析较大的xml文档,它是以流的形式进行解析,以开始标签与结束标签作为标志,遇到结束标签后,
执行结束对应的方法后,该元素就会在内存中被清除,不像DOM一样,解析成树结构存放于内存中随时可以访问。
Tomcat服务器中用到的Digester事件驱动型工具,即是对SAX(事件驱动型XML处理工具,已包含到J2SE基础类库当中)的高层次的封装,针对SAX事件提供了更加友好的接口。
缺点:只能读文档,不可写。
🎶DOM4J解析
❔解析步骤
- 一、获取
Document对象(有三种获取方法):
- 创建解析器对象,对XML 文件进行解析,获取Document对象:
SAXReader saxReader = new SAXReader();
Document testDoc = saxReader.read(ClassLoader.getSystemResource("test.xml"));
- 通过DocumentHelper 主动去创建Document 对象:
Document document = DocumentHelper.createDocument();
Element test = document.addElement("test");
- 通过DocumentHelper 去解析文本字符串获取Document 对象:
String text = "<test></test>";
Document textDoc = DocumentHelper.parseText(text);
-
二、通过Document 对象获取标签/元素信息,从而进行解析。(大部分读操作都是和DOM一致的)
一、节点对象操作方法
1. 获取文档的根节点
Element root = document.getRootElement();
2. 获取节点的文本
String text = node.getText();
String textTrim = node.getTextTrim();
3. 获取子节点集
List<Element> nodeList = node.elements("csdn");// 获取名为csdn的子节点的所有子节点
4. 在某个节点下添加节点
Element csdn = node.addElement("csdn");
5. 设置节点文本
csdn.setText("假正经的小柴");
6. 删除某个节点
parendNode.remove(childNode);
二、节点对象属性的方法操作
1.取得某节点下的某属性
Attribute attribute = node.attribute("属性名");
2.设置属性值或者添加某属性值
node.setAttribute(String name,String value);
3.移除某属性值
node.remove(attribute);
4.获取所有属性
NamedNodeMap attributes = node.getAttributes();
5.获取属性的文本
String text = attribute.getText();
6.添加某属性
node.addAttribute(String name,String value);
7.获取所有属性
List<Attribute> attributes = node.attributes();
三、将文档写入XML文件
1.文档中全为英文,不设置编码,直接写入的形式.
XMLWriter writer = new XMLWriter(new FileWriter("ot.xml"));
writer.write(document);
writer.close();
2.文档中含有中文,设置编码格式写入的形式.
OutputFormat format = OutputFormat.createPrettyPrint();// 创建文件输出的时候,自动缩进的格式
format.setEncoding("UTF-8");//设置编码
XMLWriter writer = new XMLWriter(newFileWriter("output.xml"),format);
writer.write(document);
writer.close();
四、字符串和XML的互换
1.将字符串转化为XML
String text = "<csdn> <java>Java班</java></csdn>";
Document document = DocumentHelper.parseText(text);
2.将文档或节点的XML转化为字符串.
SAXReader reader = new SAXReader();
Document document = reader.read(new File("csdn.xml"));
Element root=document.getRootElement();
String docXmlText=document.asXML();
String rootXmlText=root.asXML();
Element memberElm=root.element("csdn");
String memberXmlText=memberElm.asXML();