Code for VeLO 1: Training Versatile Learned Optimizers by Scaling Up
这篇文章将介绍一下怎么用VeLO进行训练。
这篇文章基于https://colab.research.google.com/drive/1-ms12IypE-EdDSNjhFMdRdBbMnH94zpH#scrollTo=RQBACAPQZyB-,将介绍使用learned optimizer in the VeLO family:
- 一个简单的图片识别人物
- resetnets 下一篇文章
Accelerator Setup、依赖安装和导入
# 设置Accelerator的类型,一般在实验室中只有GPU
Accelerator_Type = 'GPU' #@param ["GPU", "TPU", "CPU"]
gpu_info = !nvidia-smi
gpu_info = '\n'.join(gpu_info)
if gpu_info.find('failed') >= 0:
print('Not connected to a GPU')
else:
print(gpu_info)
# install lopt
# learned_optimization 这个库中包含了
!pip install git+https://github.com/google/learned_optimization.git
# jax 是 TensorFlow 的一个简化库,名为 JAX,结合 Autograd 和 XLA,可以支持部分 TensorFlow 的功能,但是比 TensorFlow 更加简洁易用。
import jax
if Accelerator_Type == 'TPU':
import jax.tools.colab_tpu
jax.tools.colab_tpu.setup_tpu()
from learned_optimization.tasks.fixed import image_mlp
from learned_optimization.research.general_lopt import prefab
from learned_optimization import eval_training
from matplotlib import pylab as plt
from learned_optimization import notebook_utils as nu
import numpy as onp
from learned_optimization.baselines import utils
import os
# use the precomputed baselines folder from gcp for loading baseline training curves
# 这句话我不是很清楚是什么含义 emm
os.environ["LOPT_BASELINE_ARCHIVES_DIR"] = "gs://gresearch/learned_optimization/opt_archives/"
使用Optax style的优化器
jax有自己的一个示例版优化库optimizers,不过这个库非常的小,都没实现学习率训练计划schedule,当然也可以自己写一个函数,learning_rate_fn(steps),然后作为参数传入optimizers.sgd(step_size=learning_rate_fn)即可。
如果自己写比较麻烦,就可以用optax库。https://zhuanlan.zhihu.com/p/545561011
import optax
# defining an optimizer that targets 1000 training steps
NUM_STEPS = 1000 # 这里是制定优化器要执行的步数
opt = prefab.optax_lopt(NUM_STEPS) # 定义优化器
定义和执行一个简单的训练循环
# Learned_optimization contains a handful of predefined tasks. These tasks
# wrap the model initialization and dataset definitions in one convenient
# object. Here, we initialize a simple MLP for the fashionmnist dataset.
# 一个手动预定义的task,包装了MLP model + fashionmnist dataset
task = image_mlp.ImageMLP_FashionMnist8_Relu32()
# We initialize the underlying MLP and collect its state using its init
# function. Under the hood, this is really just initializing a haiku model
# as seen here (https://github.com/google/learned_optimization/blob/main/learned_optimization/tasks/fixed/image_mlp.py#L58).
# 初始化这个模型
key = jax.random.PRNGKey(0)
params = task.init(key)
# finally, we initialize the optimizer with the model state:
# 使用model的state来初始化优化器
opt_state = opt.init(params)
# 在训练循环中,我们只需要这么一个update函数
# For a training loop, all we need is an update function. This update function
# takes existing optimizer state优化器参数, model params模型参数, training data训练数据, and randomness随机数
# as args, and returns new optimizer state, new model params, and the loss.
# import jax
@jax.jit
def update(opt_state, params, data, key):
"""Simple training update function.
Args:
opt_state: Optimizer state
params: Model parameter weights
data: Training data
key: Jax randomness
Returns:
A tuple of updated optimizer state, model state, and the current loss.
返回一个元组:优化器的参数、模型的参数、还有当前的loss,(训练数据已经用了,不需要返回"""
l, g = jax.value_and_grad(task.loss)(params, key, data)
# 我猜测:这里的优化器应该是默认frozen的,然后
updates, opt_state = opt.update(g, opt_state, params=params, extra_args={"loss": l})
params = optax.apply_updates(params, updates) # 对模型的参数进行更新
return opt_state, params, l
# a simple training loop
losses = []
for i in range(NUM_STEPS):
batch = next(task.datasets.train) # 从训练集中拿出数据出来
key1, key = jax.random.split(key) # 随机数的处理
opt_state, params, l = update(opt_state, params, batch, key1) # 执行update函数
losses.append(l)
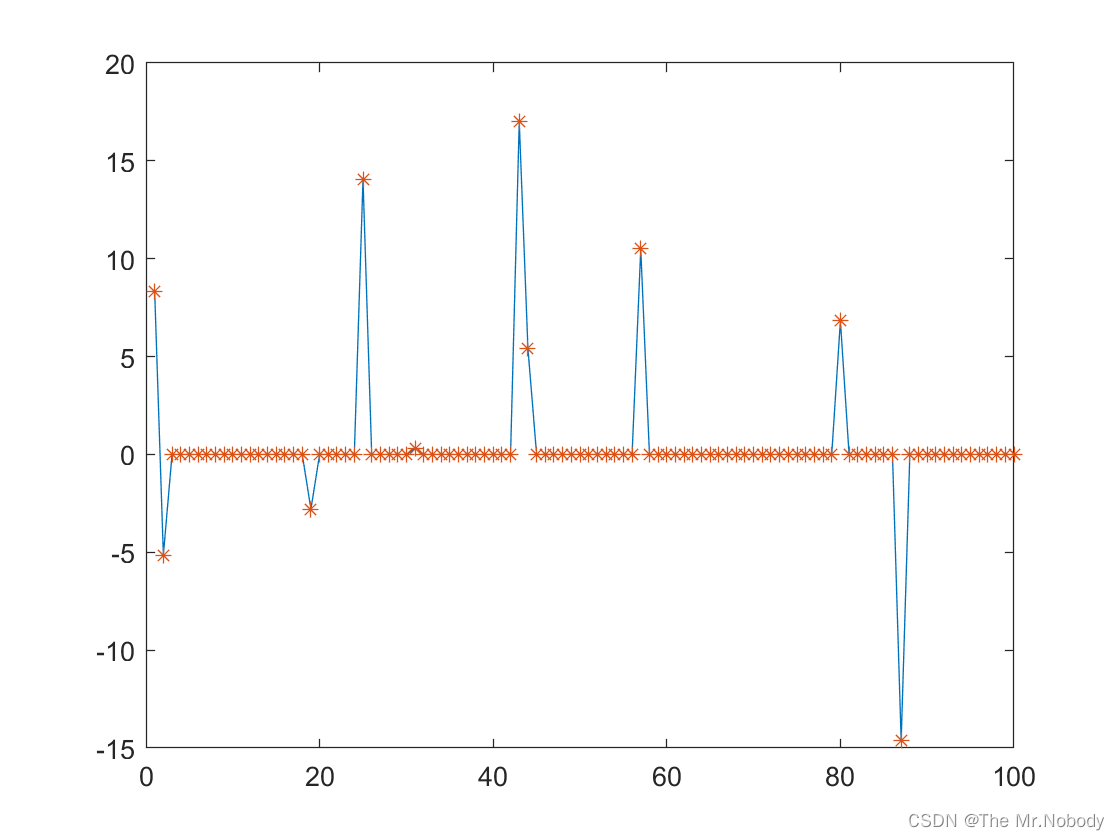
绘制一下loss的图像
# here we visualize the loss during training
plt.plot(losses)