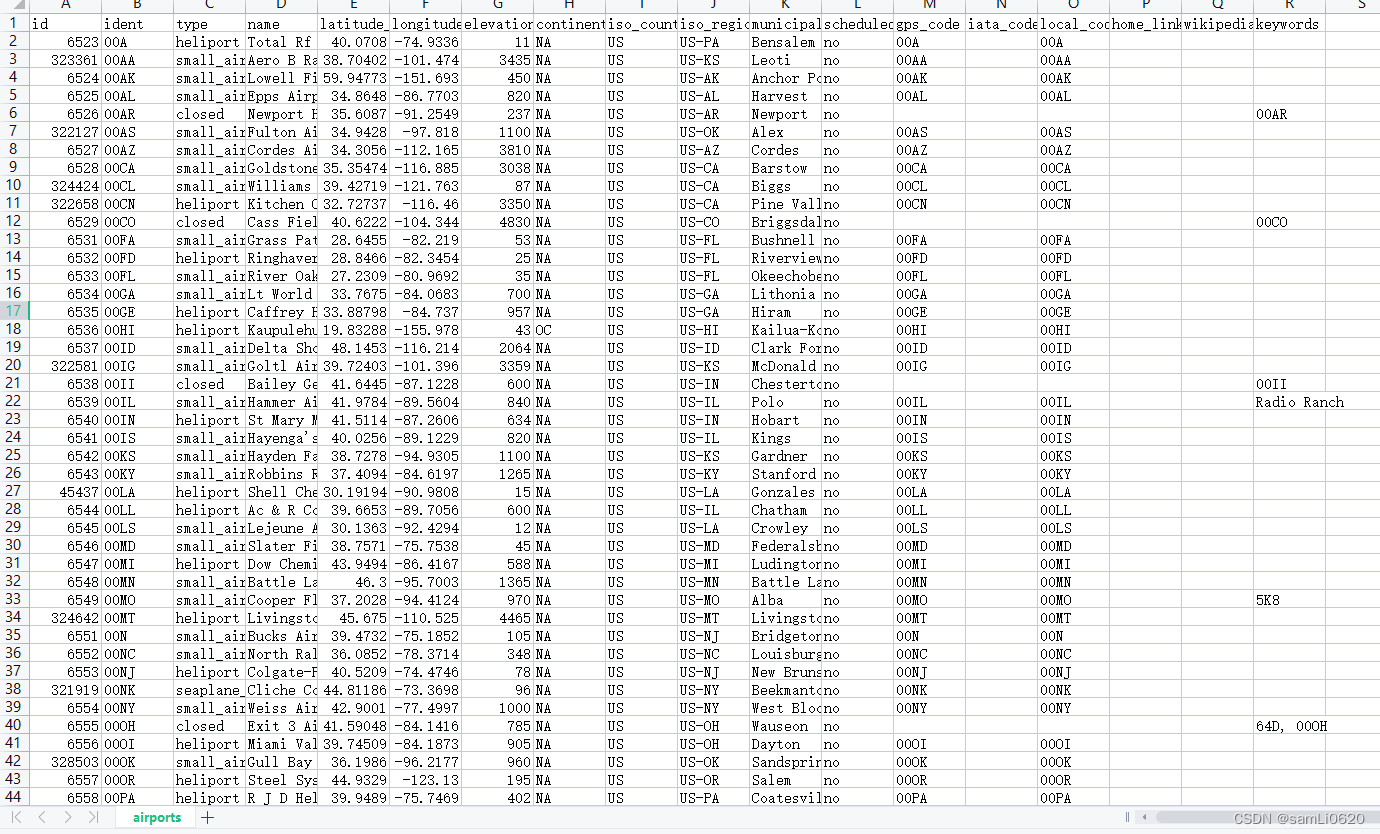
目录:
(1)自动补全-安装品分词器
(2)自动补全-自定义分词器
(3)自动补全-DSL实现自动补全查询
(4) 自动补全-修改酒店索引库结构
(5)自动补全-RestAPI实现自动补全查询
(6)自动补全-实现搜索框自动补全
(1)自动补全-安装品分词器



https://github.com/medcl/elasticsearch-analysis-pinyin
下载解压
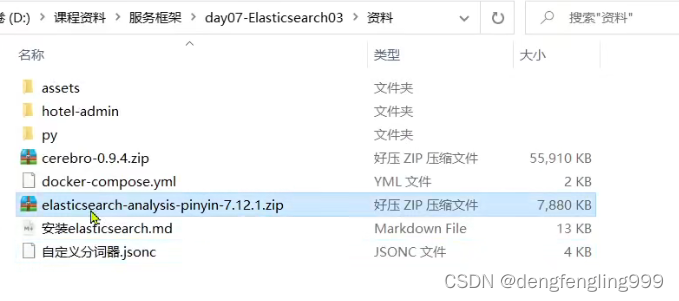
将解压后的py,上传到ES的挂载的插件目录:

重启ES:

测试分词查询 :使用ik_max_word:进行分词 :它分的词语比ik_smart:分的词语更多
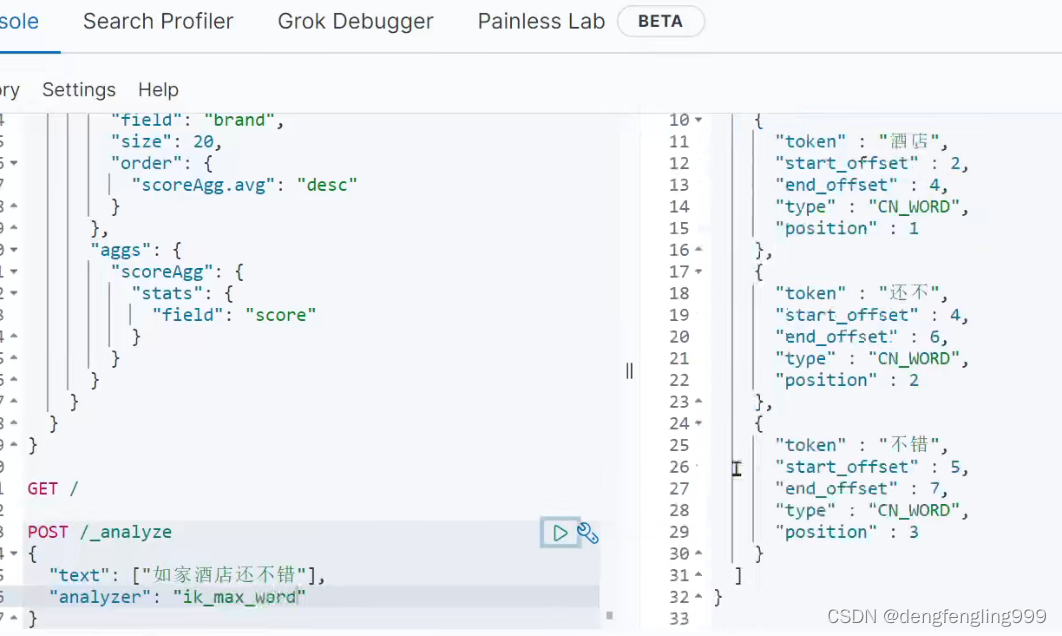
使用拼音分词:
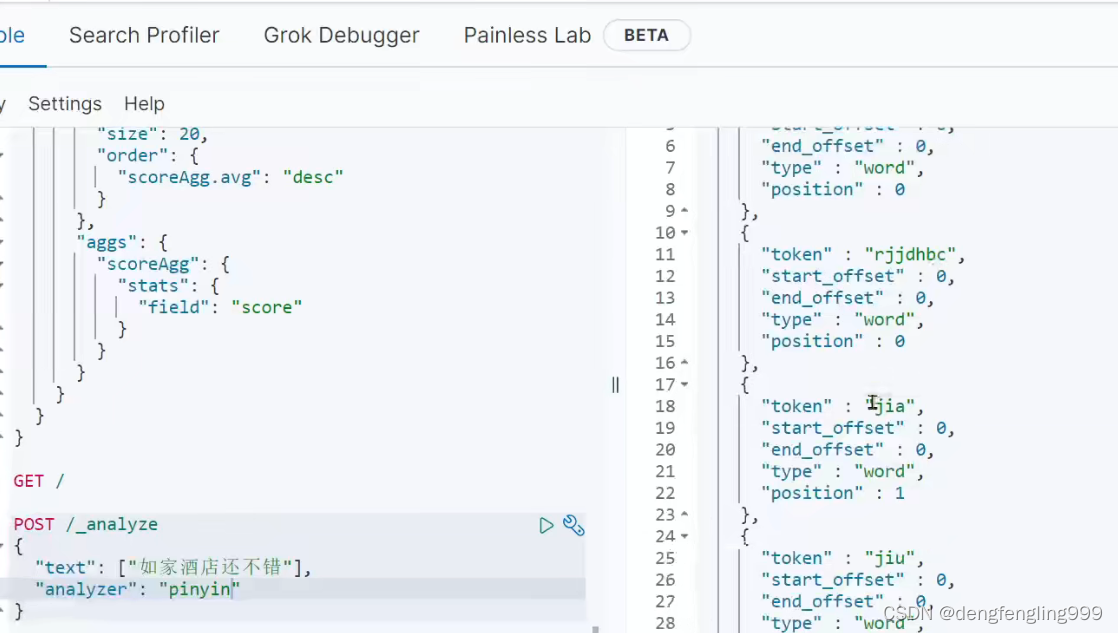

这就是拼音分词器的用法,以后我们在创建拼音分词器的时候可以mapping映射去定义拼音分词器,作为我们的分词器了
(2)自动补全-自定义分词器
上面的拼音分词器,还有一些问题,这里把拼音的首字母放到这里,也说明了这句话没有被分词,而是作为一个整体出现的
还把每一个字都形成了一个拼音,这也没什么用
这里只剩下了拼音,我们用拼音搜索的情况占少数的,大多数情况下我们想用中文搜索
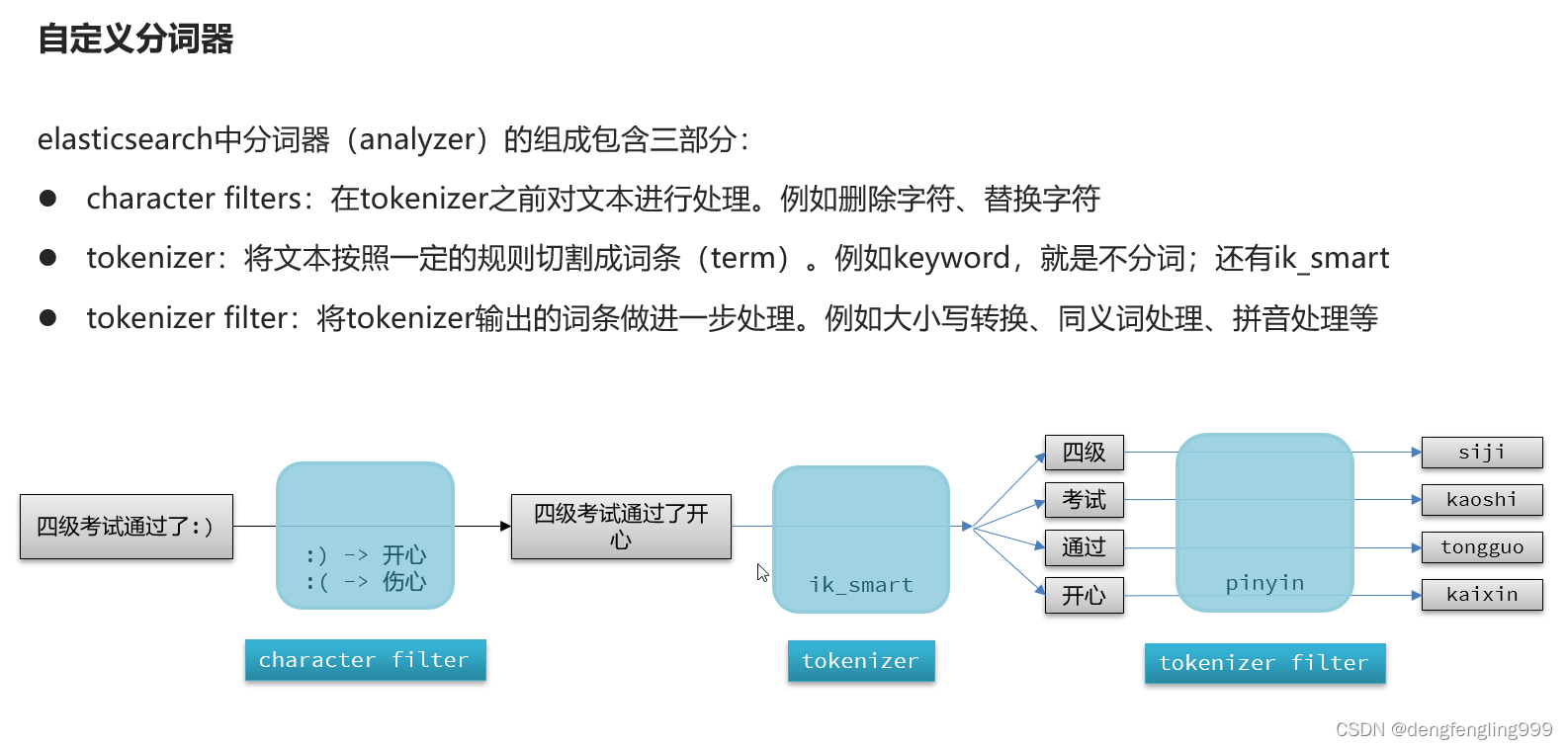
上面的自定义分词器例子就解决了拼音分词器不能分词的问题

tokenizer:进行分词
keep_joined_full_pinyin:分词全拼
Keep_original:要不要保持中文
解决其他的问题:可以参照官网的内容


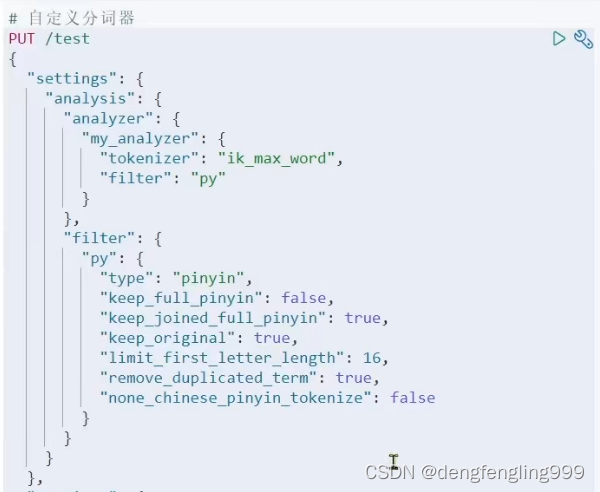

运行新建索引库添加自定义分词器
测试一下分词:
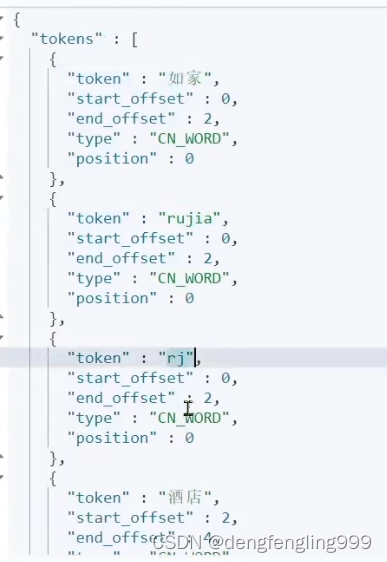
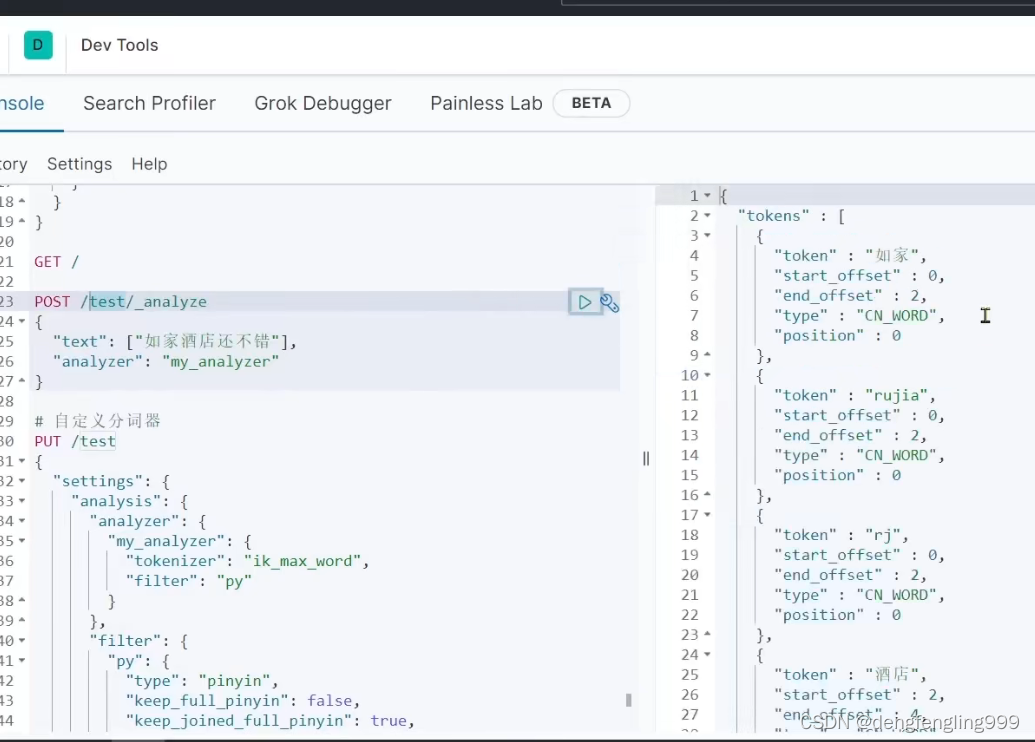 在分词分词的汉字拼音都有,而且还有分词的首字母拼音
在分词分词的汉字拼音都有,而且还有分词的首字母拼音
插入一些文档:

搜索:有点问题搜索拼音,把同音字也搜到了
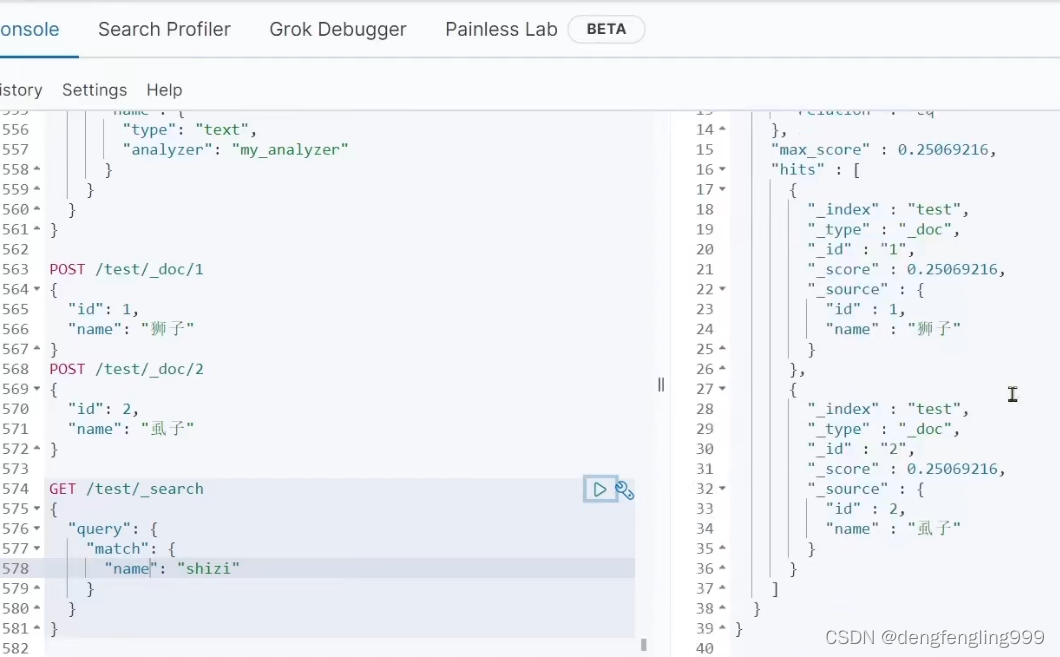
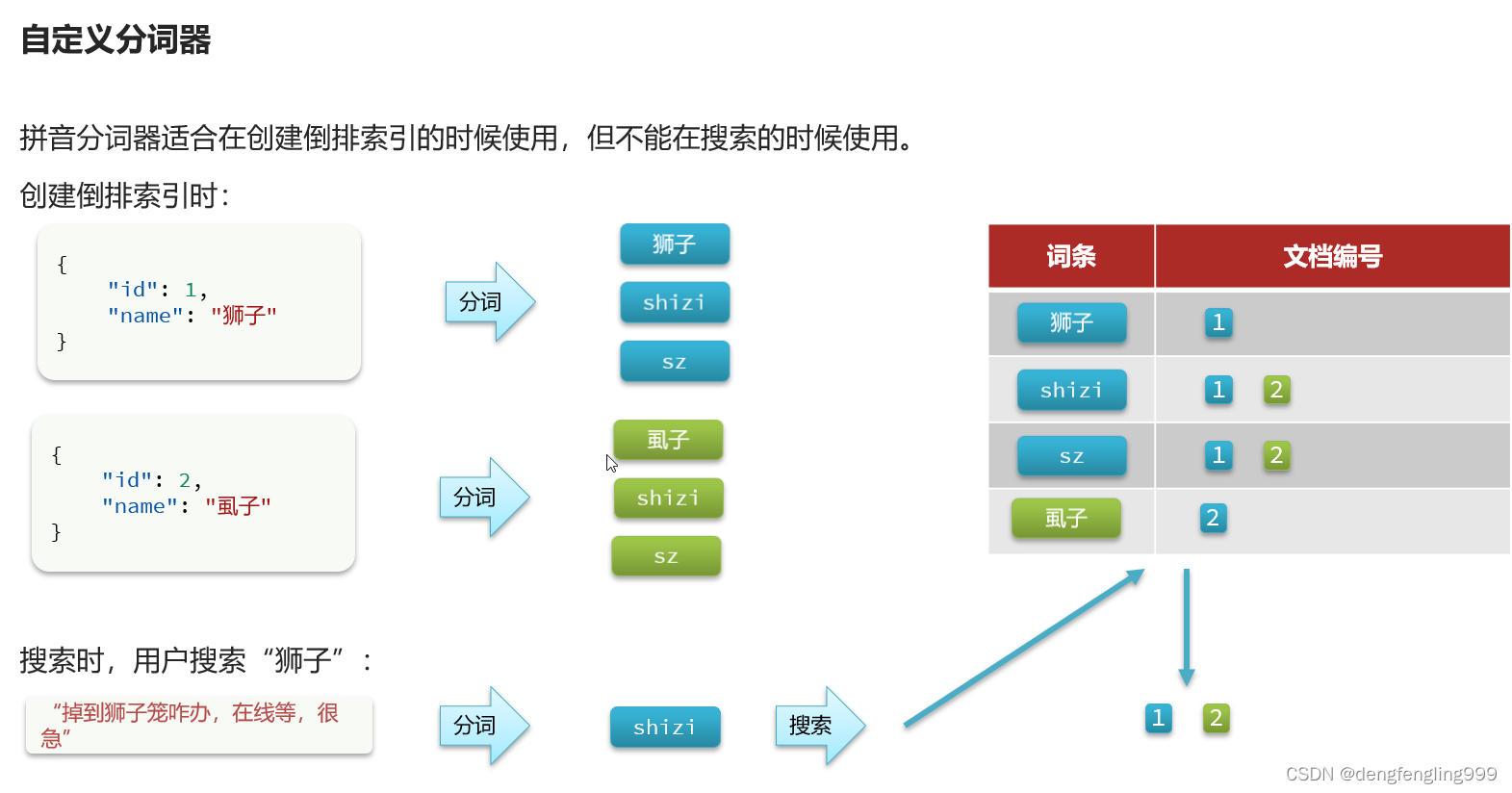
这就是问题的所在,在搜索时也用了拼音选择器,拿拼音去搜,就搜出来2条数据,在创建的时候可以用拼音选择器,在搜索的时候不应该用拼音选择器 ,在搜索是用户输入的是中文,用户用中文去搜,输入的是拼音,才拿拼音去搜
 analyzer:是创建索引时用的
analyzer:是创建索引时用的
search_analyer:是搜索是去用的
先删掉:

修改:

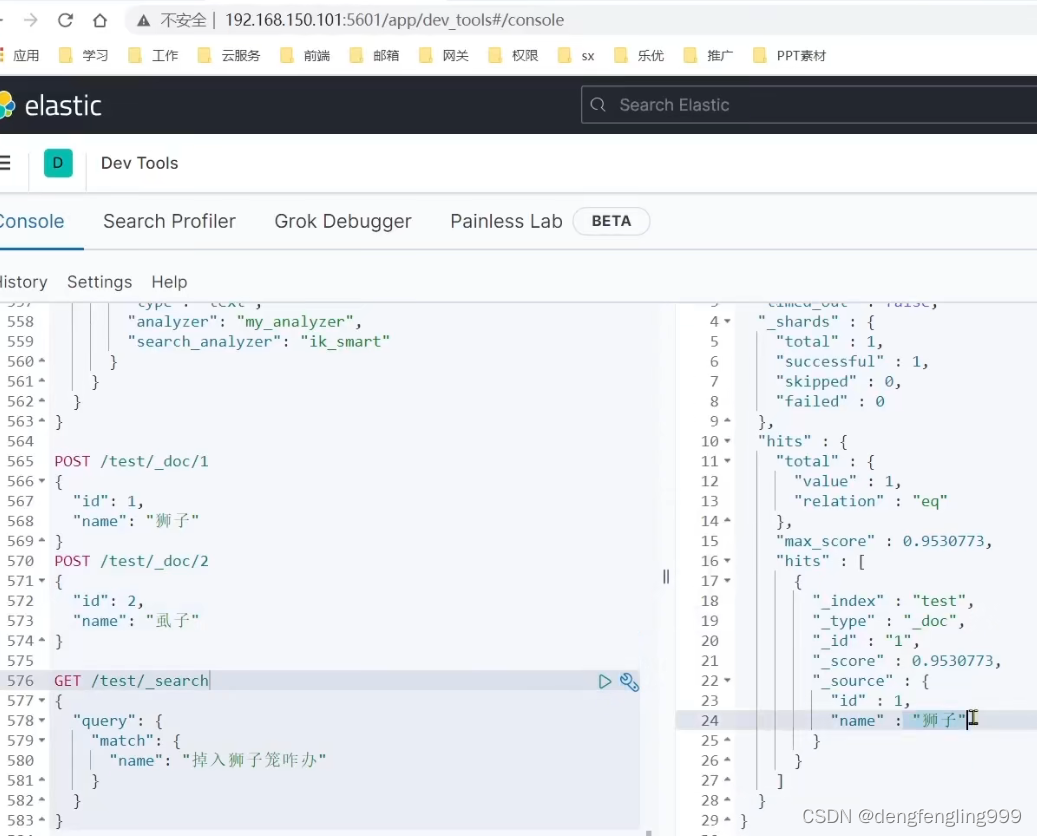
运行:在插入两条数据:

重新搜索:此时就搜索到一个
character filter:是对特殊字符做处理的
(3)自动补全-DSL实现自动补全查询


创建索引库:

插入数据:3条
 查询:s
查询:s

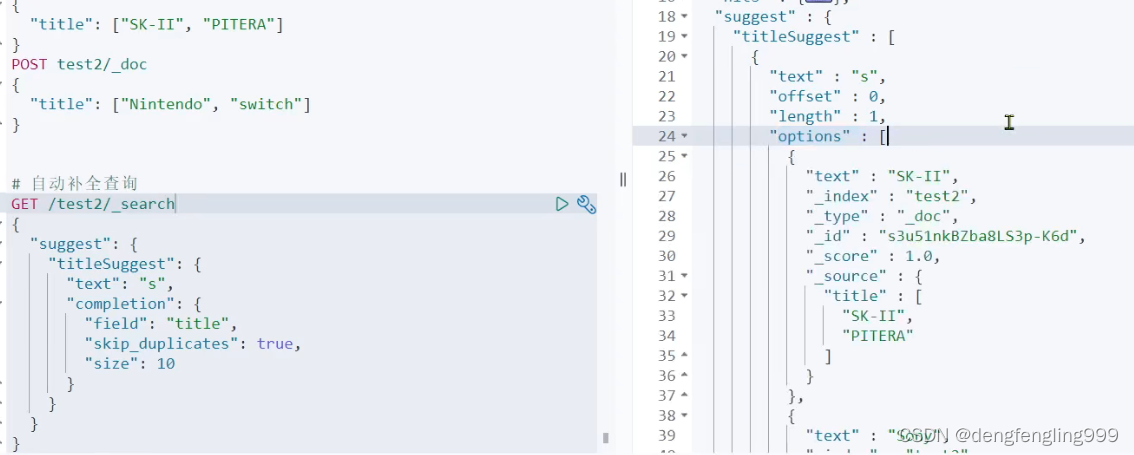

更改输入so

(4) 自动补全-修改酒店索引库结构

查看数据库结构: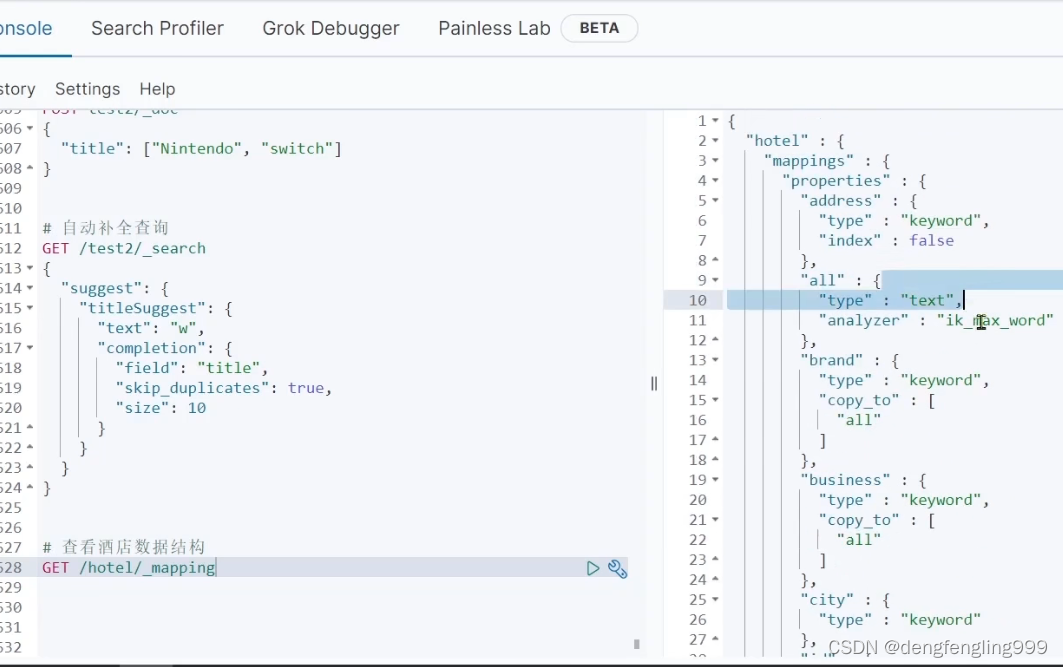

修改:





这里添加了一个sugession字段,所以对应的java代码里面也要加一个sugession字段

然后把brand和business放进这个集合,将来可以根据这个自动补全
使用Arrays.asList()进行集合的使用
重新运行原来写过的测试类:导入数据

运行一下:发现在搜索的当中包含y一个sugession,里面有品牌信息和商圈信息

这个商圈信息,有江湾和/五角场 有一个小问题将来只能根据江来提示信息不能根据五来进行提示
可以把它切割一下,需要修改java代码

改造实体类代码:
Collections集合工具类中的addAll()往集合中一次性添加多个元素
、
运行再次查询:business就切割成多个了

自动补全查询测试:
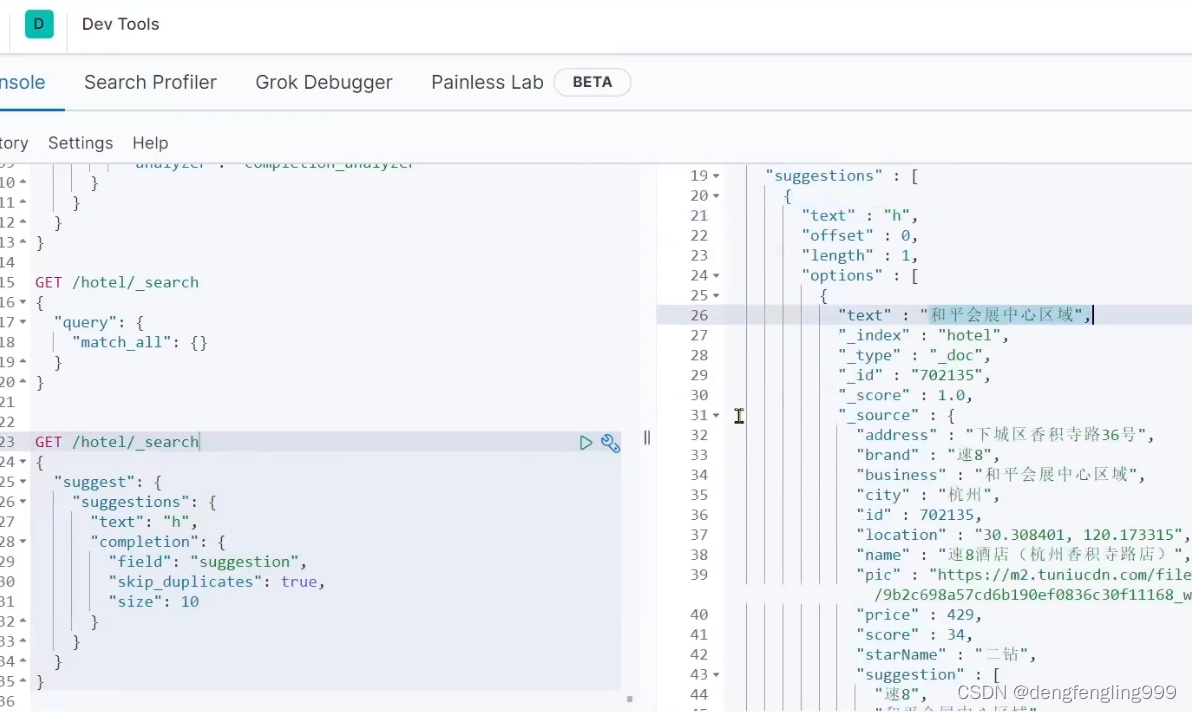

(5)自动补全-RestAPI实现自动补全查询

在测试类中添加新的测试方法:
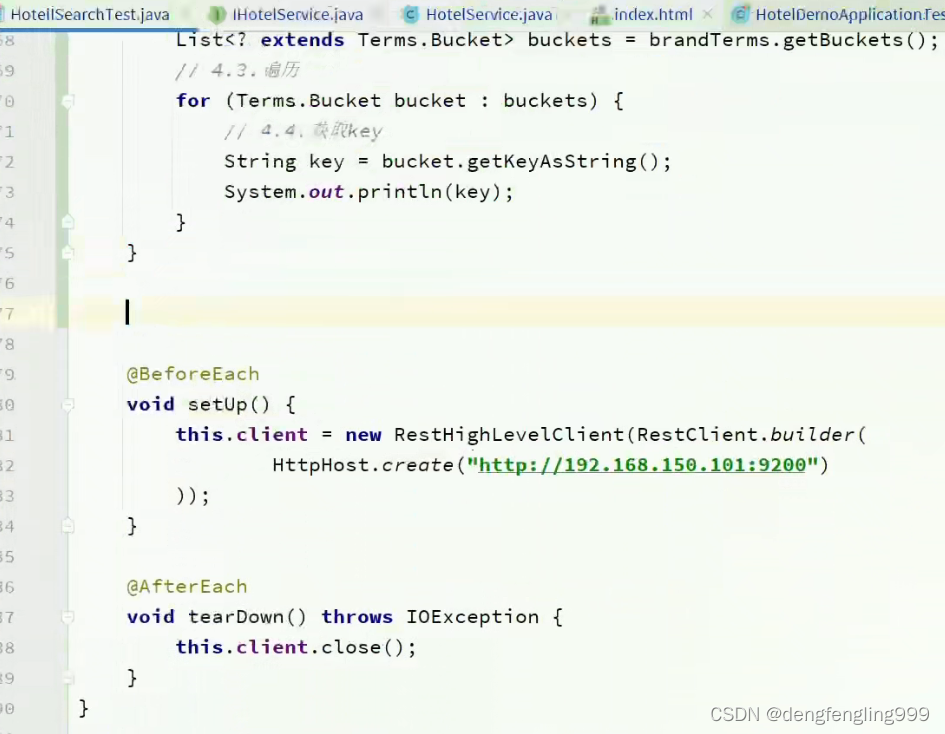

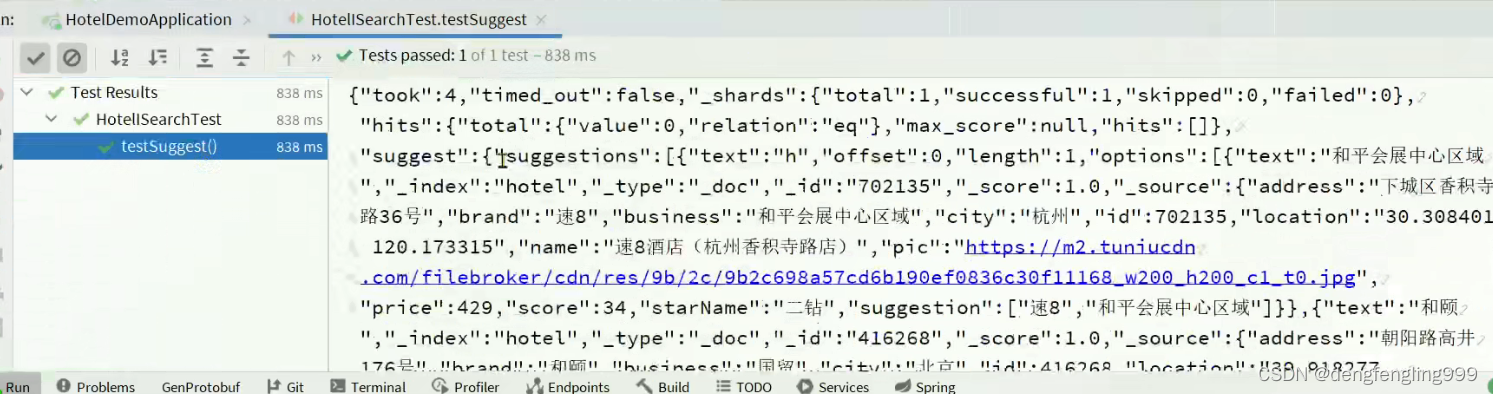





(6)自动补全-实现搜索框自动补全

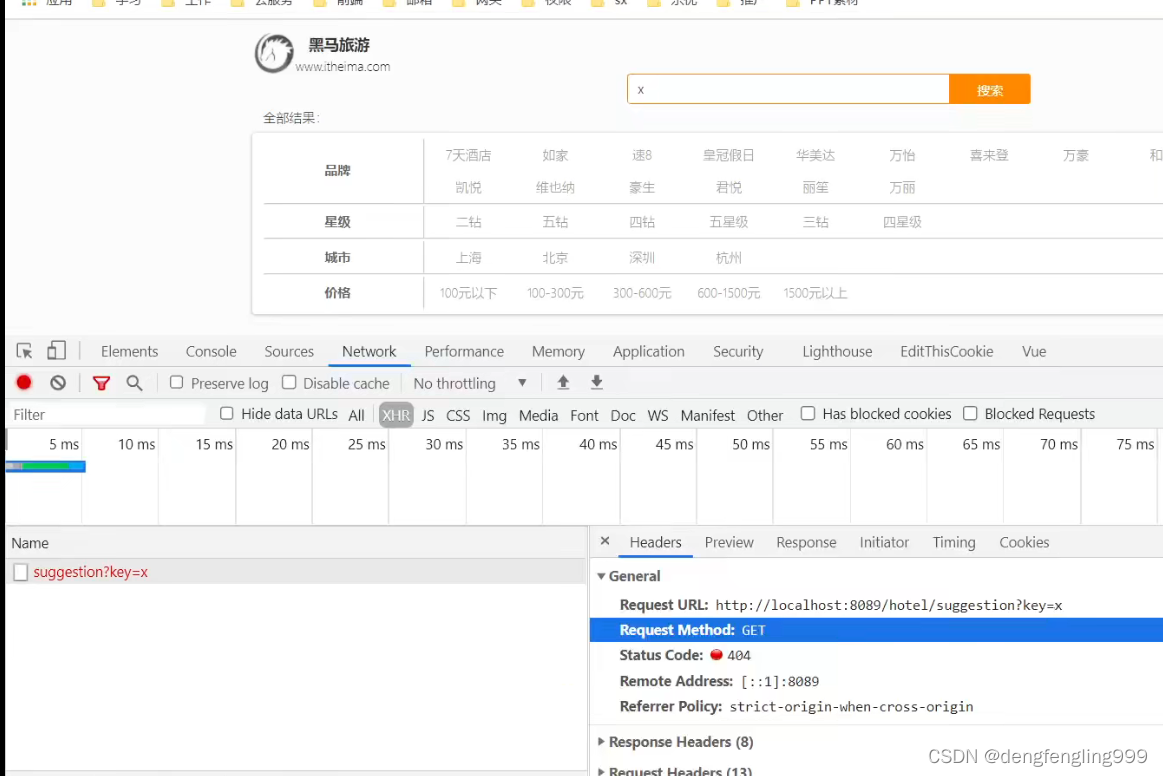
在HotelController中添加新的请求:


IHotelService:接口
IHotelServiceImpl实现类实现方法:1的前面有一个
try{


重启测试:输入x就会显示跟x有关的所有结果


这样就实现了拼音搜索的自动补全功能










![[iHooya]1月15日寒假班作业解析](https://img-blog.csdnimg.cn/c430bcda67d442ba8c8b982909add71e.png#pic_center)