深入 YOLOv8:探索 block.py 中的构建块
YOLOv8,作为最新和最先进的对象检测模型之一,其核心架构由多个精心设计的构建块组成。这些构建块在 block.py 文件中定义,它们共同构成了 YOLOv8 的骨架。在本文中,我们将深入探讨这些构建块的原理和作用。
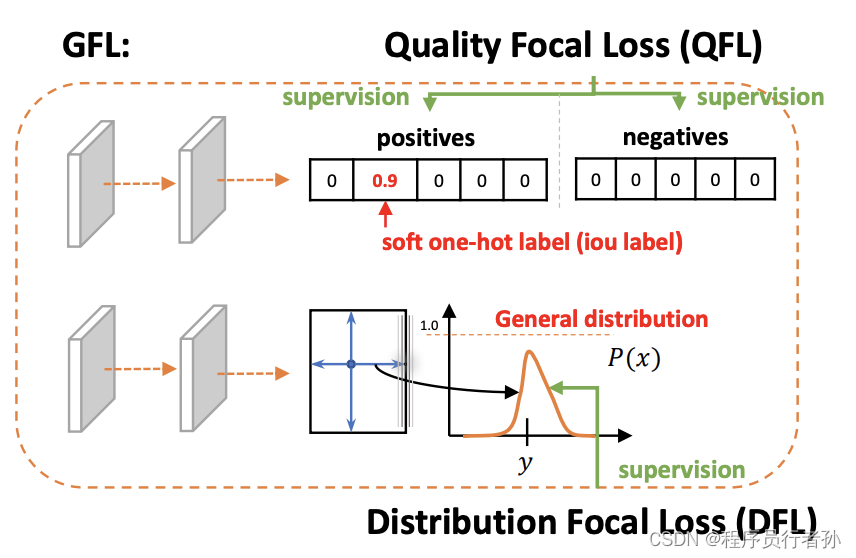
1. DFL (Distribution Focal Loss)
DFL (Distribution Focal Loss) 的原理和作用
DFL,即分布焦点损失(Distribution Focal Loss),是 Focal Loss 的一种改进,它专门设计来处理目标检测任务中的类别不平衡问题,同时允许对边界框位置的不确定性进行建模。DFL 的核心思想是将焦点损失的概念扩展到连续标签的优化问题,这在目标检测中尤其重要,因为除了类别标签外,还需要精确预测边界框的位置。
原理
-
类别不平衡:
在目标检测中,正样本(包含目标的图像区域)通常远少于负样本(不包含目标的图像区域)。这种类别不平衡会导致模型在训练过程中对负样本过拟合。 -
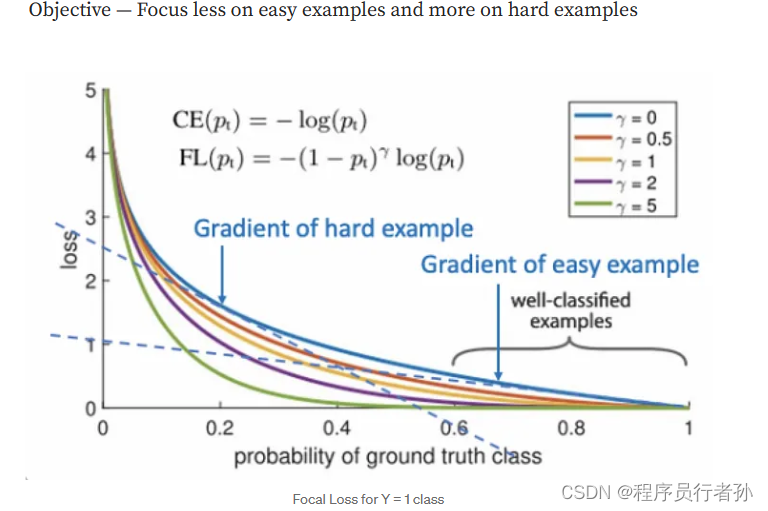
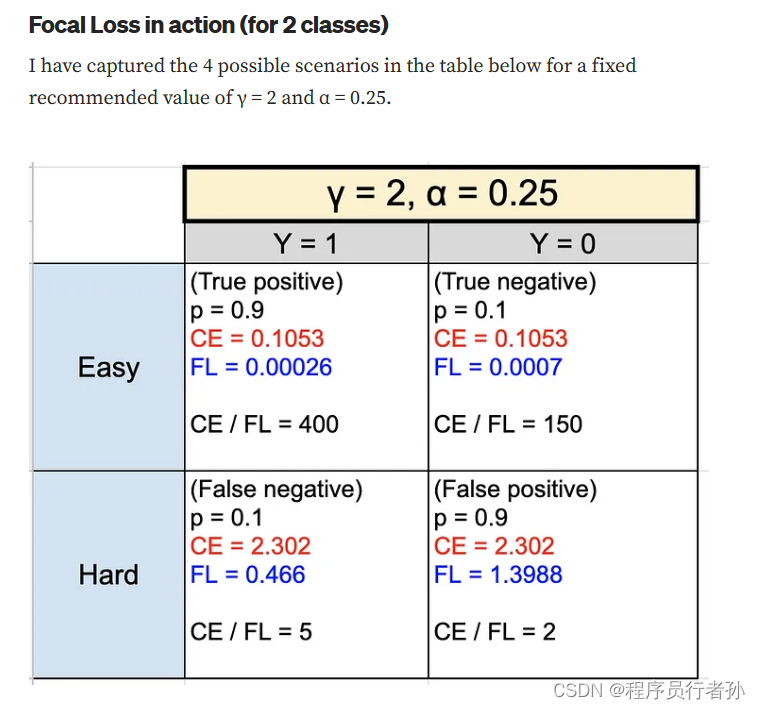
焦点损失 (Focal Loss):
Focal Loss 通过减少对易分类样本的关注,增加对难分类样本的学习,从而解决类别不平衡问题。它为交叉熵损失函数增加了一个缩放因子,该因子根据样本的预测准确性动态调整。

-
边界框预测的不确定性:
在目标检测中,边界框预测通常被视为回归问题,但传统的损失函数(如 L1 或 IoU 损失)可能无法充分捕捉边界框位置的不确定性。DFL 通过使用连续分布来表示边界框的位置,允许模型学习这些不确定性。
-
DFL 的设计:
DFL 将质量估计(如边界框的 IoU 或中心性分数)与类预测向量合并,形成一个联合表示。这样,模型不仅学习类别,还学习边界框的质量估计。此外,DFL 使用向量来表示边界框位置的任意分布,这提供了比传统方法更灵活的边界框表示。
作用
-
提高难分类样本的检测性能:
通过专注于难分类样本,DFL 提高了模型对这些样本的检测性能。 -
更准确的边界框预测:
DFL 允许模型学习边界框位置的分布,从而提高预测的准确性。 -
解决训练与推理的不一致性:
DFL 通过联合表示消除了训练和推理过程中质量估计和分类之间的不一致性。 -
增强模型的泛化能力:
DFL 的连续标签优化有助于提高模型在面对不同数据分布时的泛化能力。
代码分析
在 YOLOv8 的实现中,DFL 类如下所示:
class DFL(nn.Module):
"""
Integral module of Distribution Focal Loss (DFL).
Proposed in Generalized Focal Loss https://ieeexplore.ieee.org/document/9792391
"""
def __init__(self, c1=16):
"""Initialize a convolutional layer with a given number of input channels."""
super().__init__() # 调用父类的初始化方法
# 定义一个卷积层,输入通道数为c1,输出通道数为1,卷积核大小为1x1,没有偏置
self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False)
x = torch.arange(c1, dtype=torch.float) # 创建一个序列,从0到c1-1
# 将卷积层的权重设置为可学习的参数,权重的值为x的视图,形状为(1, c1, 1, 1)
self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1))
self.c1 = c1 # 保存输入通道数
def forward(self, x):
"""Applies a transformer layer on input tensor 'x' and returns a tensor."""
b, _, a = x.shape # 获取输入张量的形状,其中b是批大小,_表示通道数(在这里不需要),a是锚点(anchors)的数量
# 对输入张量进行reshape、转置、softmax等操作,并返回结果
return self.conv(x.view(b, 4, self.c1, a).transpose(2, 1).softmax(1)).view(b, 4, a)
# 如果需要使用另一种reshape和计算方式,可以使用下面的一行代码
# return self.conv(x.view(b, self.c1, 4, a).softmax(1)).view(b, 4, a)
在这个实现中:
__init__方法初始化一个卷积层self.conv,其权重被设置为输入通道数的参数值。forward方法接受输入张量x,对其进行重塑和转置,应用 softmax 函数来获取概率分布,然后通过卷积层self.conv,并最后将结果重塑为原始的形状。
DFL 模块的这种设计允许它作为一个损失函数的组成部分,用于训练过程中的优化。通过这种方式,DFL 有助于提高目标检测模型在处理不平衡数据和边界框不确定性方面的能力。
2. Proto
Proto的原理和作用
Proto 是 YOLOv8 中用于分割模型的一个组件,它代表“Prototype”(原型)。在分割任务中,Proto 模块用于生成分割掩码,这些掩码描述了目标对象在图像中的精确轮廓。Proto 模块通常与上采样(或转置卷积)一起使用,以将高级特征映射到与输入图像相同的分辨率。
原理
-
特征提取:
在分割任务中,网络首先通过多个卷积层和层间连接提取图像的特征。 -
特征上采样:
由于卷积操作通常会降低特征图的空间分辨率,Proto 模块使用上采样将这些特征映射回原始图像的尺寸。
-
分割掩码生成:
上采样的特征图经过一系列的卷积操作,最终生成每个类别的分割掩码。这些掩码是二值图,表示每个像素属于特定类别的概率。 -
损失函数优化:
分割掩码通过与真实掩码的比较来计算损失,这个损失通过反向传播来更新网络的权重。
作用
-
精确的分割:
Proto 模块能够生成高质量的分割掩码,从而实现对目标对象的精确分割。 -
多尺度特征融合:
通过上采样,Proto 模块能够将低层次的细节信息与高层次的语义信息融合,提高分割的准确性。 -
端到端学习:
Proto 模块允许端到端地从图像到分割掩码的直接学习,无需额外的后处理步骤。 -
适用于实时应用:
Proto 模块的设计使其适用于实时分割任务,因为它可以快速生成分割掩码。
代码分析
在 YOLOv8 的实现中,Proto 类如下所示:
class Proto(nn.Module):
"""YOLOv8 mask Proto module for segmentation models."""
def __init__(self, c1, c_=256, c2=32):
"""
Initializes the YOLOv8 mask Proto module with specified number of protos and masks.
Input arguments are ch_in, number of protos, number of masks.
"""
super().__init__()
# 第一个卷积层,将输入通道数 c1 转换为中间通道数 c_
self.cv1 = Conv(c1, c_, k=3)
# 上采样层,将特征图尺寸扩大两倍,同时保持通道数 c_
self.upsample = nn.ConvTranspose2d(c_, c_, 2, 2, 0, bias=True)
# 第二个卷积层,进一步提取特征
self.cv2 = Conv(c_, c_, k=3)
# 第三个卷积层,将中间通道数 c_ 转换为输出通道数 c2,生成分割掩码
self.cv3 = Conv(c_, c2)
def forward(self, x):
"""Performs a forward pass through layers using an upsampled input image."""
# 通过第一个卷积层
x = self.cv1(x)
# 通过上采样层
x = self.upsample(x)
# 通过第二个卷积层
x = self.cv2(x)
# 通过第三个卷积层,输出分割掩码
return self.cv3(x)
在这个实现中:
__init__方法初始化了三个卷积层cv1,cv2,cv3和一个上采样层upsample。上采样层使用转置卷积来增加特征图的空间尺寸。forward方法定义了数据如何通过网络流动。输入x首先通过cv1,然后是上采样层,接着是cv2,最后通过cv3来生成分割掩码。
Proto 模块的设计使其成为一个功能强大且灵活的组件,可以集成到不同的分割网络架构中,以提高分割任务的性能。
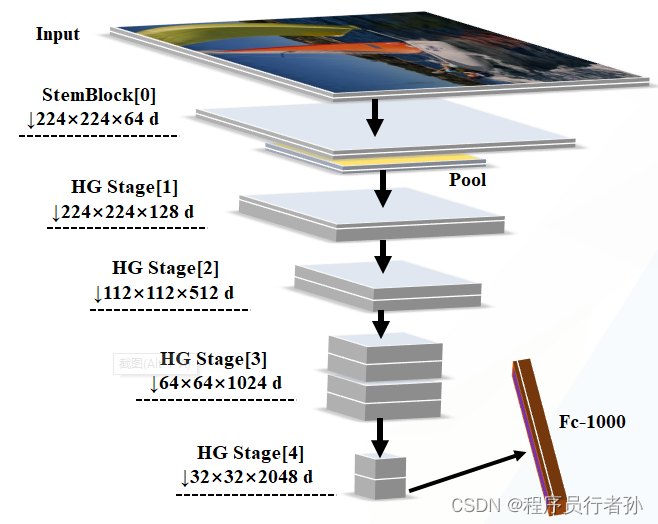
3. HGStem
HGStem的原理和作用
HGStem 是一种网络结构组件,通常用于卷积神经网络(CNN)的“stem”部分,即输入图像首先通过的一系列卷积层。HGStem 特别设计用于 PPHGNetV2(High-Performance and Generalizable Network),这是一种为图像识别任务优化的网络架构。
原理
-
特征提取:
HGStem 的目标是在网络的早期阶段快速提取特征,并通过降低特征图的空间分辨率来减少计算量。 -
多尺度特征融合:
通过使用不同尺寸的卷积核和池化层,HGStem 能够捕获不同尺度的特征,这有助于网络学习到更丰富的视觉信息。

-
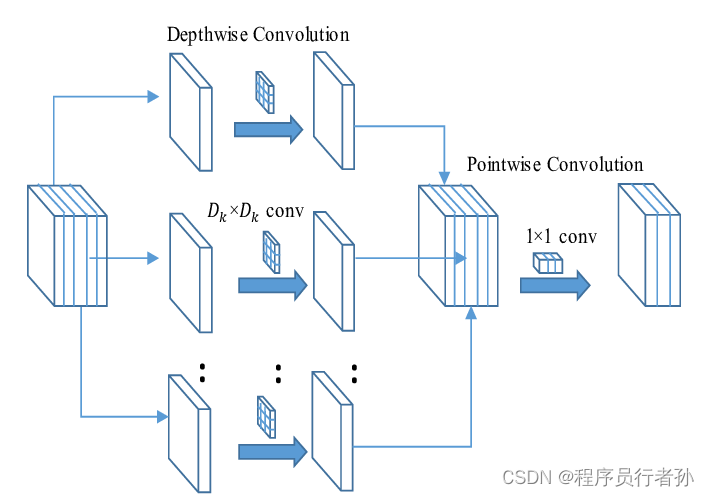
轻量化设计:
HGStem 通常包含轻量化的卷积操作,如深度可分离卷积(Depthwise Separable Convolution),以减少模型的参数数量和计算复杂度。
-
激活函数:
在卷积层之后,HGStem 使用激活函数(如 ReLU)来引入非线性,这有助于网络学习更复杂的特征表示。
作用
-
高效的特征提取:
HGStem 为网络提供了一个高效的起点,能够快速提取图像特征并为后续层提供良好的基础。 -
减少计算量:
通过轻量化设计,HGStem 减少了整个网络的计算量,使模型更适合实时应用。 -
适应性强:
由于能够捕获多尺度的特征,HGStem 增强了网络对不同尺寸目标的适应性。 -
端到端学习:
HGStem 作为网络的一部分,可以通过端到端的方式进行训练,无需额外的预训练步骤。
代码分析
在 YOLOv8 的实现中,HGStem 类如下所示:
class HGStem(nn.Module):
"""
StemBlock of PPHGNetV2 with 5 convolutions and one maxpool2d.
"""
def __init__(self, c1, cm, c2):
"""
Initialize the SPP layer with input/output channels and specified kernel sizes for max pooling.
"""
super().__init__()
# 第一个卷积层,将输入通道数 c1 转换为中间通道数 cm
self.stem1 = Conv(c1, cm, 3, 2, act=nn.ReLU())
# 第二个卷积层,使用填充使特征图尺寸保持不变
self.stem2a = Conv(cm, cm // 2, 2, 1, 0, act=nn.ReLU())
# 第三个卷积层,将通道数增加回 cm
self.stem2b = Conv(cm // 2, cm, 2, 1, 0, act=nn.ReLU())
# 第四个卷积层,进一步提取特征
self.stem3 = Conv(cm * 2, cm, 3, 2, act=nn.ReLU())
# 第五个卷积层,将中间通道数 cm 转换为输出通道数 c2
self.stem4 = Conv(cm, c2, 1, 1, act=nn.ReLU())
# 池化层,用于降低特征图的空间分辨率
self.pool = nn.MaxPool2d(kernel_size=2, stride=1, padding=0, ceil_mode=True)
def forward(self, x):
"""Forward pass of a PPHGNetV2 backbone layer."""
# 通过第一个卷积层和池化层
x = self.stem1(x)
x = F.pad(x, [0, 1, 0, 1])
# 通过第二个和第三个卷积层
x2 = self.stem2a(x)
x2 = F.pad(x2, [0, 1, 0, 1])
x2 = self.stem2b(x2)
# 通过池化层
x1 = self.pool(x)
# 将两个分支的特征图合并
x = torch.cat([x1, x2], dim=1)
# 通过第四个和第五个卷积层
x = self.stem3(x)
x = self.stem4(x)
return x
在这个实现中:
__init__方法初始化了五个卷积层stem1到stem4和一个池化层pool。这些层共同构成了 HGStem 的主体。forward方法定义了数据通过网络的流动方式。输入x首先通过stem1和pool,然后通过stem2a和stem2b,接着是pool和stem3,最后通过stem4来生成输出。
HGStem 的设计使其成为一个高效的特征提取模块,适用于需要处理高分辨率输入图像的应用,如图像分割、目标检测等。通过精心设计的卷积和池化操作,HGStem 能够为网络的深层提供有用的特征表示。
4. HGBlock
HGBlock的原理和作用

HGBlock 是 PPHGNetV2(High-Performance and Generalizable Network)中的一个构建块,它用于构建卷积神经网络的主体部分。HGBlock 的设计旨在通过轻量化的卷积操作和有效的特征融合策略来提高网络的性能和泛化能力。
原理
-
轻量化卷积:
HGBlock 使用轻量化的卷积操作,如 LightConv,来减少模型的参数数量和计算量。
-
特征融合:
通过使用深度可分离卷积(Depthwise Separable Convolution)和 ShuffleNet 风格的通道混洗,HGBlock 能够在网络的不同层之间有效地融合特征。 -
多尺度特征:
HGBlock 能够捕获和融合多尺度的特征,这有助于网络对不同尺寸的目标进行检测。 -
残差连接:
HGBlock 通常包含残差连接,这有助于在深层网络中缓解梯度消失问题,提高训练的效率。

作用
-
提高计算效率:
通过使用轻量化的卷积操作,HGBlock 减少了模型的计算负担,使其更适合实时应用。 -
增强特征表达:
HGBlock 的设计增强了网络对图像特征的表达能力,有助于提高检测和识别的准确性。 -
提高网络泛化能力:
通过融合多尺度的特征,HGBlock 提高了网络对不同尺寸目标的泛化能力。 -
简化网络结构:
HGBlock 作为可复用的构建块,简化了网络结构的设计,便于实现和维护。
代码分析
在 YOLOv8 的实现中,HGBlock 类可能如下所示:
class HGBlock(nn.Module):
"""
HG_Block of PPHGNetV2 with 2 convolutions and LightConv.
"""
def __init__(self, c1, cm, c2, k=3, n=6, lightconv=False, shortcut=False, act=nn.ReLU()):
super().__init__()
# 选择使用 LightConv 或普通 Conv,取决于 lightconv 参数
block = LightConv if lightconv else Conv
# 构建多个卷积层
self.m = nn.ModuleList(block(c1 if i == 0 else cm, cm, k=k, act=act) for i in range(n))
# 挤压卷积(Squeeze convolution),将多个卷积层的输出合并
self.sc = Conv(c1 + n * cm, c2 // 2, 1, 1, act=act)
# 激励卷积(Excitation convolution),进一步提取特征
self.ec = Conv(c2 // 2, c2, 1, 1, act=act)
# 决定是否使用残差连接
self.add = shortcut and c1 == c2
def forward(self, x):
# 通过多个卷积层
y = [x]
y.extend(m(y[-1]) for m in self.m)
# 将所有卷积层的输出合并
y = self.ec(self.sc(torch.cat(y, 1)))
# 如果有残差连接,将输入和输出相加
return x + y if self.add else y
在这个实现中:
__init__方法初始化了多个卷积层self.m,一个挤压卷积层self.sc,和一个激励卷积层self.ec。lightconv参数决定是否使用 LightConv。forward方法定义了数据通过网络的流动方式。输入x通过多个卷积层,然后通过挤压卷积层合并,最后通过激励卷积层输出。如果设置了残差连接,还会将输入x和最终输出相加。
HGBlock 的设计使其成为一个高效的特征提取和融合模块,适用于需要处理高分辨率输入图像的深度学习任务,如图像分类、目标检测和分割。通过精心设计的卷积和残差连接,HGBlock 能够为网络的深层提供有用的特征表示。