Tensor Cores 使用介绍

概要介绍
TensorCore是英伟达GPU自Volta架构起支持的特性,允许CUDA开发者利用混合精度来显著提升吞吐量,且不影响精度。TensorCore在Tensorflow、PyTorch、MXNet和Caffe2等深度学习框架中得到广泛支持,用于深度学习训练。本文阐述了如何使用CUDA库在应用程序中运用TensorCore,以及如何在CUDA C++设备代码中对其进行直接编程。
TensorCore
TensorCore 是一种可编程矩阵乘法和累加单元,带来高达 125 Tensor TFLOPS 的训练和推理性能。它的定制数据路径优化了浮点计算吞吐量。
每个 TensorCore 拥有一个 4x4x4 矩阵处理数组,执行运算 D=A*B+C。A 和 B 是 FP16 矩阵,C 和 D 可以是 FP16 或 FP32 矩阵。
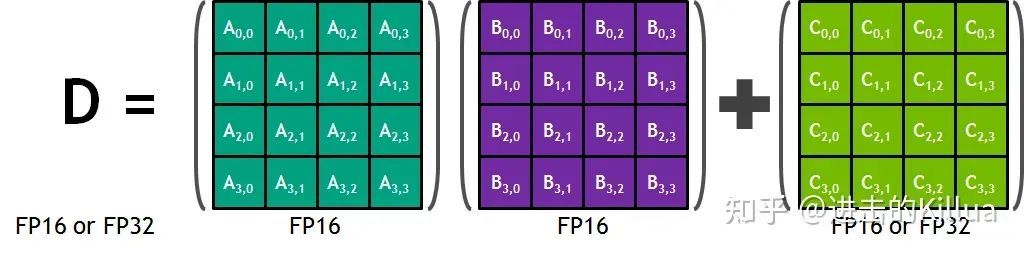
凭借每时钟可执行 64 个混合精度浮点 FMA 操作的 8 个 TensorCore,每个流多处理器 (SM) 每时钟可处理 1024 个浮点运算。
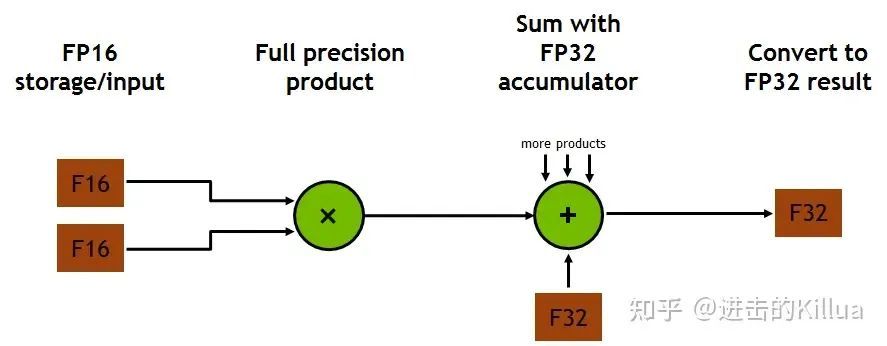
TensorCore 使用 FP16 输入进行计算,同时以 FP32 累加。以下图所示,FP16 乘法结果为完整精度值,在 4x4x4 矩阵乘积点积计算中,与其他乘积累加在 FP32 操作中。
解锁 GPU 性能:使用 Tensor Cores 提速人工智能计算
借助 cuBLAS 和 cuDNN 库,普通用户可通过 CUDA 技术充分利用 Tensor Cores。
cuBLAS 加速矩阵乘法 (GEMM),而 cuDNN 优化卷积和循环神经网络 (RNN) 计算,提升 AI 模型性能。
cuBLAS中使用TensorCore
通过优化cuBLAS代码充分利用Tensor Cores,仅需对cuBLAS API进行微调。遵循简单规则,如示例代码所示,即可指示cuBLAS使用Tensor Cores。此优化可显著提升AI计算性能。
// First, create a cuBLAS handle:
cublasStatus_t cublasStat = cublasCreate(&handle);
// Set the math mode to allow cuBLAS to use Tensor Cores:
cublasStat = cublasSetMathMode(handle, CUBLAS_TENSOR_OP_MATH);
// Allocate and initialize your matrices (only the A matrix is shown):
size_t matrixSizeA = (size_t)rowsA * colsA;
T_ELEM_IN **devPtrA = 0;
cudaMalloc((void**)&devPtrA[0], matrixSizeA * sizeof(devPtrA[0][0]));
T_ELEM_IN A = (T_ELEM_IN *)malloc(matrixSizeA * sizeof(A[0]));
memset( A, 0xFF, matrixSizeA* sizeof(A[0]));
status1 = cublasSetMatrix(rowsA, colsA, sizeof(A[0]), A, rowsA, devPtrA[i], rowsA);
// ... allocate and initialize B and C matrices (not shown) ...
// Invoke the GEMM, ensuring k, lda, ldb, and ldc are all multiples of 8,
// and m is a multiple of 4:
cublasStat = cublasGemmEx(handle, transa, transb, m, n, k, alpha,
A, CUDA_R_16F, lda,
B, CUDA_R_16F, ldb,
beta, C, CUDA_R_16F, ldc, CUDA_R_32F, algo);
cuBLAS用户将注意到与现有的cuBLAS GEMM代码相比有一些变化:
- 例程必须是一个GEMM;目前只有GEMM支持Tensor Core执行。
- 数学模式必须设置为CUBLAS_TENSOR_OP_MATH。
- Tensor Core 运算要求输入数据按 8 步长跨越,因此矩阵维度须为 8 的倍数:
* k、lda、ldb、ldc:8 的倍数
* m:4 的倍数 - 矩阵的输入和输出数据类型必须是半精度或单精度。
- 不满足上述规则的GEMM将回退到非Tensor Core实现。
cuDNN中使用TensorCore
在 cuDNN 中轻松使用 Tensor Cores,只需对代码进行简单修改。提高性能,无需大动干戈。
// Create a cuDNN handle:
checkCudnnErr(cudnnCreate(&handle_));
// Create your tensor descriptors:
checkCudnnErr( cudnnCreateTensorDescriptor( &cudnnIdesc ));
checkCudnnErr( cudnnCreateFilterDescriptor( &cudnnFdesc ));
checkCudnnErr( cudnnCreateTensorDescriptor( &cudnnOdesc ));
checkCudnnErr( cudnnCreateConvolutionDescriptor( &cudnnConvDesc ));
// Set tensor dimensions as multiples of eight (only the input tensor is shown here):
int dimA[] = {1, 8, 32, 32};
int strideA[] = {8192, 1024, 32, 1};
checkCudnnErr( cudnnSetTensorNdDescriptor(cudnnIdesc, getDataType(),
convDim+2, dimA, strideA) );
// Allocate and initialize tensors (again, only the input tensor is shown):
checkCudaErr( cudaMalloc((void**)&(devPtrI), (insize) * sizeof(devPtrI[0]) ));
hostI = (T_ELEM*)calloc (insize, sizeof(hostI[0]) );
initImage(hostI, insize);
checkCudaErr( cudaMemcpy(devPtrI, hostI, sizeof(hostI[0]) * insize, cudaMemcpyHostToDevice));
// Set the compute data type (below as CUDNN_DATA_FLOAT):
checkCudnnErr( cudnnSetConvolutionNdDescriptor(cudnnConvDesc,
convDim,
padA,
convstrideA,
dilationA,
CUDNN_CONVOLUTION,
CUDNN_DATA_FLOAT) );
// Set the math type to allow cuDNN to use Tensor Cores:
checkCudnnErr( cudnnSetConvolutionMathType(cudnnConvDesc, CUDNN_TENSOR_OP_MATH) );
// Choose a supported algorithm:
cudnnConvolutionFwdAlgo_t algo = CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PRECOMP_GEMM;
// Allocate your workspace:
checkCudnnErr( cudnnGetConvolutionForwardWorkspaceSize(handle_, cudnnIdesc,
cudnnFdesc, cudnnConvDesc,
cudnnOdesc, algo, &workSpaceSize) );
if (workSpaceSize > 0) {
cudaMalloc(&workSpace, workSpaceSize);
}
// Invoke the convolution:
checkCudnnErr( cudnnConvolutionForward(handle_, (void*)(&alpha), cudnnIdesc, devPtrI,
cudnnFdesc, devPtrF, cudnnConvDesc, algo,
workSpace, workSpaceSize, (void*)(&beta),
cudnnOdesc, devPtrO) );
注意一下与常见cuDNN使用的一些变化:
- 卷积算法必须为 ALGO_1(前向传播为 IMPLICIT_PRECOMP_GEMM)。
ALGO_1 以外的算法,未来版本可能启用 Tensor Core 利用。 - 数学类型必须设置为CUDNN_TENSOR_OP_MATH,与cuBLAS类似.
- Tensor Core 数学例程每步处理 8 个值,要求输入和输出通道维度为 8 的倍数,与 cuBLAS 一致,确保了最佳性能。
- 卷积的输入、滤波器和输出数据类型必须是半精度。
- 不满足上述规则的卷积将回退到非Tensor Core实现。
CUDA C++中使用TensorCore
虽然cuBLAS和cuDNN涵盖了许多Tensor Cores的潜在用途,但用户还可以直接在CUDA C++中编程。Tensor Cores通过nvcuda::wmma命名空间中的一组函数和类型在CUDA 9.0中公开。这些函数和类型允许您将值加载或初始化到张量核心所需的特殊格式中,执行矩阵乘累加(MMA)步骤,并将值存回内存。在程序执行期间,一个完整的warp可以同时使用多个Tensor Cores,这使得warp能够以非常高的吞吐量执行16x16x16的MMA。核心的API如下所示,详细介绍见文档。
template<typename Use, int m, int n, int k, typename T, typename Layout=void> class fragment;
// 等待直到所有warp lanes都到达load_matrix_sync,然后从内存中加载矩阵片段a。
void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned ldm);
void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned ldm, layout_t layout);
// 等待,直到所有warp lanes都到达store_matrix_sync,然后将矩阵片段a存储到内存中。
void store_matrix_sync(T* mptr, const fragment<...> &a, unsigned ldm, layout_t layout);
// 使用常量值v填充一个矩阵片段。
void fill_fragment(fragment<...> &a, const T& v);
// 等待直到所有warp lanes都到达mma_sync,然后执行warp同步的矩阵乘累加操作D = A * B + C。
void mma_sync(fragment<...> &d, const fragment<...> &a, const fragment<...> &b, const fragment<...> &c, bool satf=false);
下面来看个实际的简单例子。
头文件引用
#include <mma.h>
using namespace nvcuda;
声明和定义
GEMM算法优化:
通过分配每个warp处理输出矩阵一个16x16部分,算法有效利用了二维网格和线程块。该策略允许灵活地处理a或b的转置,并支持数据步幅大于矩阵步幅。
// The only dimensions currently supported by WMMA
const int WMMA_M = 16;
const int WMMA_N = 16;
const int WMMA_K = 16;
__global__ void wmma_example(half *a, half *b, float *c,
int M, int N, int K,
float alpha, float beta)
{
// Leading dimensions. Packed with no transpositions.
int lda = M;
int ldb = K;
int ldc = M;
// Tile using a 2D grid
int warpM = (blockIdx.x * blockDim.x + threadIdx.x) / warpSize;
int warpN = (blockIdx.y * blockDim.y + threadIdx.y);
在执行MMA操作之前,操作数矩阵必须表示在GPU的寄存器中。由于MMA是一个warp范围的操作,这些寄存器分布在warp的各个线程之间,每个线程持有整个矩阵的一个fragment。在CUDA中,fragment是一个模板类型,具有描述片段持有的矩阵、整个WMMA操作的形状、数据类型以及A和B矩阵中数据是按行还是按列主序的模板参数。最后一个参数可以用于对A或B矩阵进行转置。这个示例中没有进行转置,所以两个矩阵都是按列主序的,这是GEMM的标准方式。
// Declare the fragments
wmma::fragment<wmma::matrix_a, WMMA_M, WMMA_N, WMMA_K, half, wmma::col_major> a_frag;
wmma::fragment<wmma::matrix_b, WMMA_M, WMMA_N, WMMA_K, half, wmma::col_major> b_frag;
wmma::fragment<wmma::accumulator, WMMA_M, WMMA_N, WMMA_K, float> acc_frag;
wmma::fragment<wmma::accumulator, WMMA_M, WMMA_N, WMMA_K, float> c_frag;
// set o in accumulator fragment
wmma::fill_fragment(acc_frag, 0.0f);
内部循环
我们用于GEMM的策略是每个warp计算输出矩阵的一个tile。为此,我们需要在A矩阵的行和B矩阵的列上进行循环。这沿着这两个矩阵的K维度进行,并生成一个MxN的输出tile。load矩阵函数从内存中获取数据(在这个示例中是全局内存,尽管它可以是任何内存空间),并将其放入一个fragment中。load的第三个参数是矩阵在内存中的“主导维度”;我们加载的16×16 tile在内存中是不连续的,因此函数需要知道连续列(或行,如果这些是按行主序的片段)之间的跨度。MMA调用在原地累积,因此第一个和最后一个参数都是我们之前初始化为零的累加器fragment。
// Loop over the K-dimension
for (int i = 0; i < K; i += WMMA_K) {
int aRow = warpM * WMMA_M;
int aCol = i;
int bRow = i;
int bCol = warpN * WMMA_N;
// Bounds checking
if (aRow < M && aCol < K && bRow < K && bCol < N) {
// Load the inputs
wmma::load_matrix_sync(a_frag, a + aRow + aCol * lda, lda);
wmma::load_matrix_sync(b_frag, b + bRow + bCol * ldb, ldb);
// Perform the matrix multiplication
wmma::mma_sync(acc_frag, a_frag, b_frag, acc_frag);
}
}
结果写回
现在,acc_frag根据A和B的乘积持有了这个warp输出tile的结果。完整的GEMM规范允许对这个结果进行缩放,并且可以就地累积到一个矩阵上。进行这种缩放的一种方法是对fragment执行逐元素操作。尽管从矩阵坐标到线程的映射未定义,但逐元素操作不需要知道这种映射,因此仍然可以使用片段执行这些操作。因此,对fragment执行缩放操作或将一个fragment的内容添加到另一个fragment中是合法的,只要这两个fragment具有相同的模板参数。利用这个特性,我们加载了C中的现有数据,并在正确的缩放下将计算结果迄今为止与之累积。
数据存储于内存中,目标指针可指向 GPU 可见的内存空间。主导维度必须指定,此外可选择按行或列主序写入输出。
// Load in current value of c, scale by beta, and add to result scaled by alpha
int cRow = warpM * WMMA_M;
int cCol = warpN * WMMA_N;
if (cRow < M && cCol < N) {
wmma::load_matrix_sync(c_frag, c + cRow + cCol * ldc, ldc, wmma::mem_col_major);
for(int i=0; i < c_frag.num_elements; i++) {
c_frag.x[i] = alpha * acc_frag.x[i] + beta * c_frag.x[i];
}
// Store the output
wmma::store_matrix_sync(c + cRow + cCol * ldc, c_frag, ldc, wmma::mem_col_major);
}
}
总结
TensorCore 通过其 API wmma 实现了 warp 级并行矩阵运算。与常规 CUDA C 相比,wmma API 可利用线程寄存器 (GPR) 和 TensorCore 硬件加速运算。所有 API 函数均以 "sync" 结尾,表明所有线程在 TensorCore 操作完成前处于同步状态。
尽管 cuBLAS 和 cuDNN 通常足以满足矩阵运算需求,但直接使用 wmma API 可在某些情况下提供性能优势。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-