目录
概述
1 认识stack和heap
1.1 栈区(stack)
1.2 堆区(heap)
2 stack和heap的区别
2.1 管理方式的不同
2.2 空间大小不同
2.3 产生碎片不同
2.4 增长方式不同
2.5 分配方式不同
2.6 分配效率不同
3 确定stack和heap空间
概述
本文主要讲述了嵌入式开发中的stack和heap的概念,还详细比较了它们之间的区别,以及在实际应该过程中注意的问题。
1 认识stack和heap

1.1 栈区(stack)
由编译器自动分配释放,存放函数的参数值、返回值、局部变量等。在程序运行的过程中实时的加载和释放。因此,局部变量的生存周期为申请到释放该段栈空间的过程。

1.2 堆区(heap)
用于动态内存分配,堆在内存中位于BSS区和栈区之间。一般由程序员分配和释放。对于有内存管理的OS来说,OS会定期回收没有被释放且没有被使用的内存。
在 ANSI C 中可以用 malloc()和 free()两个函数动态地分配内存和释放内存。但是,在嵌入式实时操作系统中,多次这样做会把原来很大的一块连续内存区域,逐渐地分割成许多非常小而且彼此又不相邻的内存区域,也就是内存碎片。由于这些碎片的大量存在,使得程序到后来连非常小的内存也分配不到。 在 4.02 节的任务堆栈中, 我们讲到过用 malloc()函数来分配堆栈时, 曾经讨论过内存碎片的问题。 另外, 由于内存管理算法的原因, malloc()和 free()函数执行时间是不确定的。
分配单个堆空间

分配多个堆空间

2 stack和heap的区别
stack是由编译器在程序运行时分配空间区域,由操作系统维护。在C语言中,堆是由malloc()函数分配的内存区,该内存的释放是由free()函数来完成。
stack和heap的区别由如下几点:
2.1 管理方式的不同
stack在程序运行时,由操作系统自动管理,无需程序员手动操作。堆的操作必须有程序员手工操作,否则会出现内存泄漏的情况。
一个stack调用的范例:

2.2 空间大小不同
stack是一个向地址扩展的数据结构,是一块连续的内存区域。即栈顶的地址和栈的最大容量是由系统预先规定好的,当申请的空间超过栈的剩余空间时,将提示溢出,因此,能重栈获得空间大小。
heap是想高地址扩展的数据结构,是不连续的内存区域。系统使用链表来存储空闲的内存地址,而链表遍历方式是从低地址开始,到高地址结束。堆获取内存空间比较灵活。
2.3 产生碎片不同
对heap来说,需要频繁的使用malloc/free来申请或者释放内存,可能会造成内存空间的不连续,从而造成大量的碎片,使得程序运行的效率降低。而stack的空间在程序运行时已经被分配好了。所以,不会出现这样的情况。
2.4 增长方式不同
heap的增长方式是向上的,朝着内存地址增加的方向增长

stack的增长方式是向下的,即朝着内存地址减少的方向增长

2.5 分配方式不同
heap都是由malloc/free来申请或者释放内存。stack的申请和释放是由操作系统自动完成的。
stack的动态分配是由alloca()函数来完成的,但其释放是由操作系统自动完成的。
2.6 分配效率不同
stack是系统提供的数据结构,操作系统会在底层对其提供支持,分配专门的寄存器存放栈的地址,压栈和出栈都有专门的指令执行,堆是由C函数库提供的。堆的操作由一整套算法来寻找内存空间,所以,堆的分配效率和栈相比会低很多。
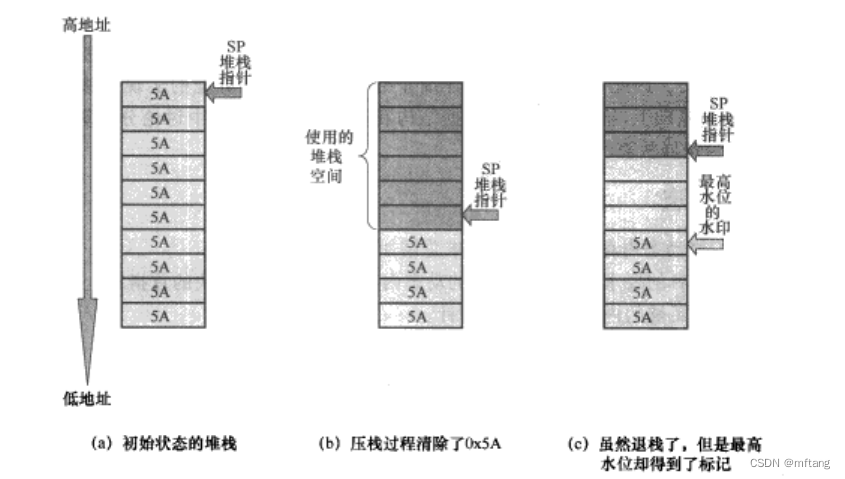
3 确定stack和heap空间
Step -1: 在初始化时,将栈空间全部初始化一个固定数据0x5a
step -2: 初始化完成后,程序可以正常使用堆栈,由于程序会忘栈中压入新的数据,这将覆盖原来的数据0x5a
step - 3: 程序在运行的过程中,堆栈中的数据会起起落落的变化,最终在程序运行完成时,会有一个最大的栈空间。这个最大的栈空间是程序所需要最大的栈空间