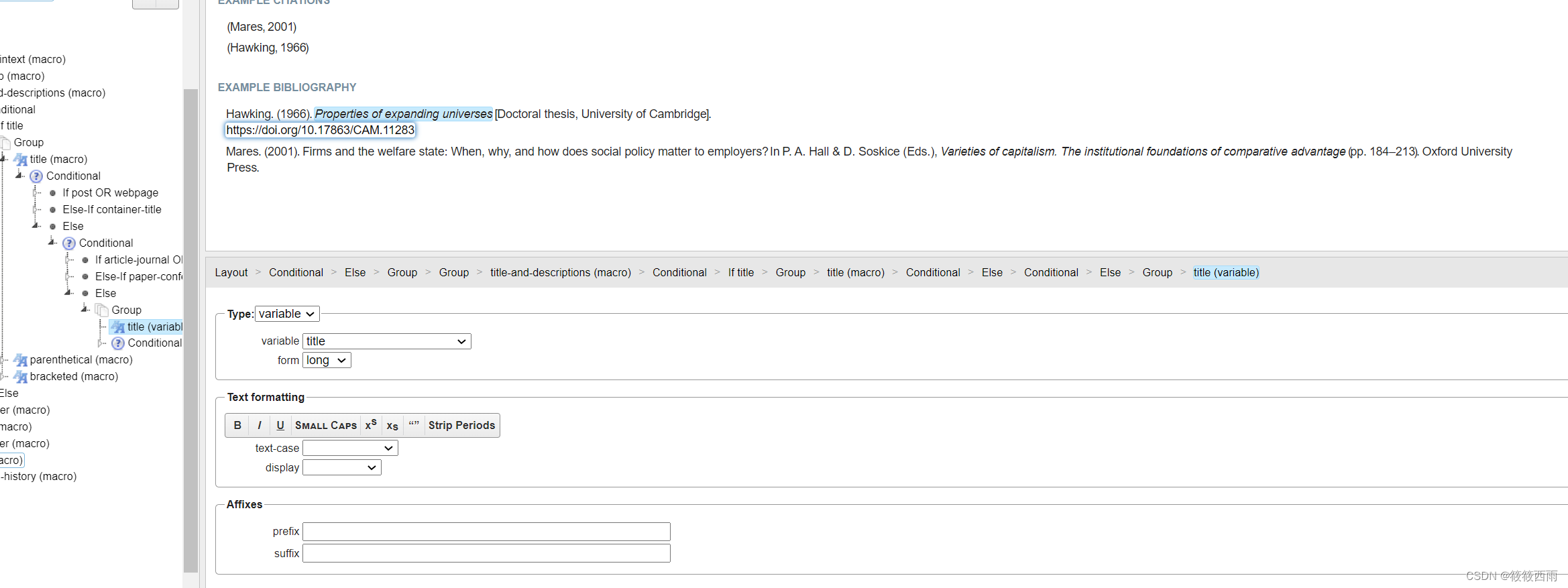
python 中的数据结构

1.1 序列
序列时有索引的数组
举例实现:
a=["北京","上海","广州","深圳","重庆","成都"]
print(a[2])
print(a[-1] + " " + a[-2])
print(a[1:3])
# 运行结果
"""
广州
成都 重庆
['上海', '广州']
"""
在序列中可以实现切片功能,切片功能非常重要,后续再Pandas的应用中会重点学习。
b=["北京","上海","广州","深圳","重庆","成都","兰州","乌鲁木齐"]
print(b[0:5:2])
"""
['北京', '广州', '重庆']
"""
上面代码中,0和5分别是序列的启示和终止位置,2时步长,因此出现这种运行结果。
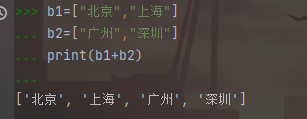
序列也可以相加
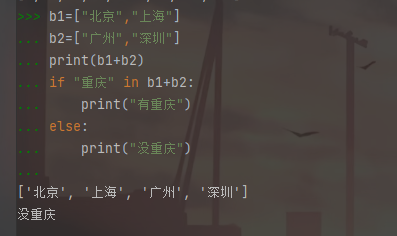
序列的 in 应用,用于判断字符串中是否存在序列之中
注:sorted()用于对序列进行排序,list()用于将序列转化为列表,len,min,max,等则分别用于计算序列的长度、最小值、最大值……
1.2 列表
-
列表创建
三种创建的方式,一是手工创建,二是创建空列表之后再添加表元素,三是直接创建一个数据列表。
a=["北京","上海","广州","深圳","重庆","成都"] b=[] c=list(range(0,20,2)) print(a) print(b) print(c)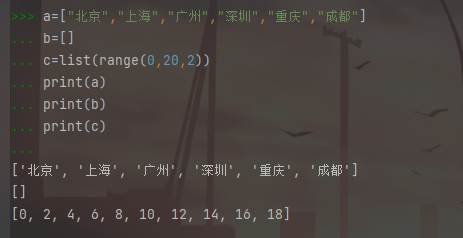
-
列表元素操作
列表建立之后,主要就是对列表进行增删改,
#用append方式添加列表元素 for i in range(1,10): b.append(i) print("原来的",b) b.insert(2,2.3) print("insert方法之后的:",b) c=[100,200,300] print("extend之后的:") b.extend(c) print(b) b[0]=10000 print("修改过的:",b) del b[-1] print("删除过的:") b.remove(2.3) print(b)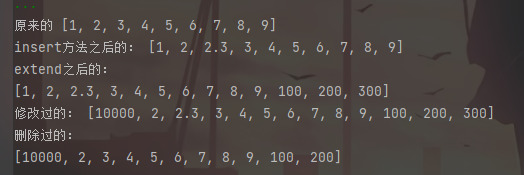
第一个循环以append方式汪列表b中添加数据,再用insert方式往列表中插入数据,insert方式准确的确定插入位置,extend 方法可以实现两个列表的合并,但是只能简单的合并再一块,对重复的数据不会进行处理。
a=[1,2,3] b=[1,2,4] a.extend(b) print('看有重复数据的列表的extend结果:',a)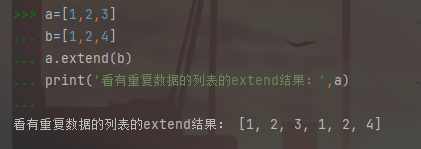
列表元素的命令
- 删除命令:del(根据列表的索引删除),remove(根据列表的值删除)
- 统计方法:count,index,sum……
-
列表循环语句
一是 for 循环,二是 enumerate 函数
print('for循环的输出:') for item in a: print(item) print('for+enumerate循环的输出:') for index,item in enumerate(a): print(index+1,item)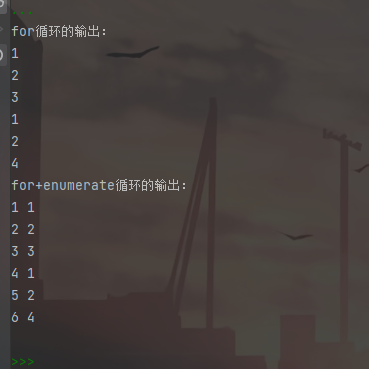
1.3 元组
元组内容不可改变,并且可以将不同类型的数据放入元组中
元组与列表的操作很类是,唯一区别在于元组再代码中是用圆括号括起来的
a=("北京","上海","广州","深圳","重庆","成都")
b=()
c=tuple(range(0,20,2))
print(a)
print(b)
print(c)
a=("哈哈","嘿嘿","呵呵")
print(a)
1.4 字典
-
字典的典型作用
- 一、去重统计
- 二、提高检索效率
-
创建字典
三种方式创建。
- 手工直接创建
- 通过单列表的方法创建
- 通过两个列表的方式创建
# 手工创建 d={'name':'王猪猪','name1':'李大壮'} if 'name2' in d: print(d['name']) else: print(d['name1'])# 单列表创建,fromkeys语句 a=["北京","上海","广州"] d1=dict.fromkeys(a) print(d1)# zip语句痛过两个列表创建 a2=["哈哈","呵呵","嘿嘿"] a3=[1,2,3] d2=dict(zip(a2,a3)) print(d2) -
字典内容的引用
两种方式引用
- 直接引用
- get方法
#直接引用方式和get引用方式 for i in range(len(a2)): print(a2[i]+" "+str(d2[a2[i]])) print(a2[i] + " " + str(d2.get(a2[i]))) -
字典的增删改查
d2["嘟嘟"]=4 print(d2) d2["哈哈"]=10000 print(d2) del d2["哈哈"] print(d2) print(d2.keys()) print(d2.items()) for x in d2.keys(): print(x) for y in d2.items(): print(y) -
字典在多分支判断中的应用
from distutils import log def stateA(): print('stateA called') def stateB(): print('stateB called') def stateC(): print('stateC called') def stateDefault(): print('stateDefault called') cases = {'a':stateA, 'b':stateB, 'c':stateC}#定义一个字典 def switch(case): if case in cases: cases[case]() else: stateDefault() def test(): switch('b') switch('c') switch('a') switch('x') test()先定义四个函数,随后定义一个字典 cases,在随后定义switch 的过程中,可以利用字典的 in 语句获取相应的数据。
1.5 集合
集合是一组元素的组合,其嘴重要的特征是保存不重复元素
- 两种创建方式
- 直接创建
- 用 set() 函数创建
set1={"北京","上海","广州","深圳"}
set2={"北京","重庆","成都","西安"}
a=["北京","三亚","海口","南宁"]
set3=set(a)
print(set1)
print(set2)
print(set3)
-
增删改功能
- 添加:add
- 定点删除:remove
- 弹出方式:pop
set1.add("乌鲁木齐") print(set1) set1.remove("乌鲁木齐") print(set1) print("现在开始进pop了:") print(len(set1)) for i in range(1,len(set1)+1): set1.pop() print(set1) -
集合运算
交集&,并集|,差集-
set1={"北京","上海","广州","深圳"} set2={"北京","重庆","成都","西安"} print(set1 & set2) print(set1 | set2) print(set1-set2) -
集合综合案例
import openpyxl from openpyxl.reader.excel import load_workbook import sys import os wk=load_workbook(filename="基金数据.xlsx") sht1=wk["基金1"] sht2=wk["基金2"] a=set() b=set() for i in range(1,sht1.max_row+1): a.add(sht1.cell(i,1).value) for i in range(1,sht2.max_row+1): b.add(sht2.cell(i,1).value) print(a-b) print(b-a)