目录
1. 前言
2. TD(0)
3. 实现要点解读
3.1 Class Env
3.2 Class State
3.3 Class Agent
3.3.1 class TD0Agent(Agent)
3.3.2 class MinimaxAgent
3.3.3 class RandomAgent(Agent)
3.3.4 class HumanPlayer(Agent)
3.4 棋盘和玩家的表示
4. Utility Function
4.1 所有状态预计算
4.2 play_one_game,单局对战
4.3 TD0_train(epochs, print_every_n=500)
4.4 compete(agent1, agent2, num_games)
4.5 play_human_vs_agent(agent_name)
5. 对战测试
1. 前言
在上一篇中实现一个基于Minimax算法的Tic-Tac-Toe AI Agent,参见:
Tic-Tac-Toe:基于Minimax算法的人机对弈程序(python实现)
本文进一步实现一个基于强化学习的时序差分算法(Temporal Difference, TD(0))的Tic-Tac-Toe AI Agent。并进行了多种Agent之间的对战测试。
本文中的代码是基于【2】中chapter01的代码进行改造的。包括类结构和类中的方法等实现的修改, 追加Minimax Agent,多种Agent之间的对战测试,等等。当然,本文针对关键要点根据我的理解追加了解读代码说明,希望能够有兴趣的小伙伴有所帮助,一起学习进步。
2. TD(0)
关于时序差分算法原理就不在这里啰嗦了,网上的相关资料铺天盖地,或者各种强化学习的教材和专著,比如说Sutton老爷子的seminal book【1】,感兴趣的小伙伴自行服用。这里用的是所谓的TD(0),其更新公式如下:
需要注意的是,以上更新公式说明了更新是反向进行的(类似于深度学习中的back-propagation)。体现在TictacToe游戏agent实现中,就是在训练中,每一局棋(one episode)结束后根据棋局结果给出reward值,然后参照该棋局状态历史从最后一个状态随时间往前回溯计算各状态下的价值估计值的更新。注意,终局状态的价值是预定义的,不需要估计更新了。
其实现代码如下:
TD0Agent::value_update(self):
state_history = [state.hash() for state in self.state_history]
for i in reversed(range(len(state_history) - 1)):
state = state_history[i]
td_error = self.greedy[i] * (
self.estimations[state_history[i + 1]] - self.estimations[state]
)
self.estimations[state] += self.step_size * td_error
其中estimations存储的就是各状态的价值估计值,step_size对应的是以上公式的中的。如上所述,在本井字棋游戏实现中,只有终局状态有reward(直接作为终局状态的价值估计使用),所以以上公式中的
就不需要了。此外,折扣系数
也处于简便直接取为1。
greedy这个参数需要解释一下(这个参数名感觉取得并不妥当)。由于在训练时,有一定概率explore也有一定的概率exploit,exploit是直接利用既有价值估计结果进行行动决策,此时是不需要进行价值估计更新的,只有explore时才需要进行价值估计更新。在棋局进行过程中,某一步棋采用explore时对应的greedy就置为True;反之,采用exploit时就将对应的greedy置为False。
3. 实现要点解读
【2】原始代码中是将agent类作为Env类的成员,然后用Env.play()方法来实现一局棋的进程。但是这样我认为强化学习的一般设定中,agent、env是相互独立的(注意,在两人对弈类游戏中有两个agent:player1和player2),agent与env之间通过行动、状态、奖励等进行交互。原始代码中这种实现与强化学习一般设定不符合,这样的话,这个结构不容易扩展。因此我对agent类、env类的实现进行了修改,包括(但不限于)它们的相互关系、它们之间的交互、以及相应地内部方法的实现等等。
3.1 Class Env
改造后的Env类极度简化,代码如下:
class Env:
def __init__(self):
self.current_state = State()
def reset(self):
self.current_state = State()
def step(self,action):
"""
Update board state according to action, and generate the reward
action: [i,i,player_symbol]
"""
self.current_state = self.current_state.next_state(action[0],action[1],action[2])
_ = self.current_state.is_end()
return self.current_state只有一个step()方法(参考gym的模板),在TieTacTac游戏中表示某一方下一手棋。注意,action中包含了落子方和落子位置的信息。
在更一般的情况下,Env中应该还有描述环境变化动力学机制的转移概率函数(即)用于描述状态转移,以及即时奖励的评估。但是,在本游戏中,基于
的状态转移是确定性的,在State类中用方法next_state()实现了;另一方面,在本实现中,只有终局时一次性地给予奖励,这个为了实现方便放在Agent类的初始化中实现了。当然,这个是可以吸收到Env类中来实现的。
此外,仅在一局游戏结束时给以奖励并不是必然的,也可以设计另外的奖励机制,比如说每走一步棋都根据局面情况评估给予一定奖励。但是这个就有点复杂,对于TieTacTac这样简单的游戏就有杀鸡焉用牛刀之感。
3.2 Class State
State类中除了盘面状态信息的表示、打印,还有通过方法is_end()进行终局判断处理、以及基于动作和当前状态决定下一个状态的处理。这后两项其实应该是Env类中应该实现的。但是由于比较简单放在State类中显得更加紧凑吧。
值得一提的是State.hash()方法用于计算当前状态的哈希值,这个对于信息存储比较memory efficient。对于TicTacToe这样简单的游戏虽然不是说绝对必需的,但是对于更复杂的游戏,这个就会显得非常有用了。
3.3 Class Agent
在改造后的实现中,用Agent类作为一个基类,然后再追加各种具体的要素来实现基于各种不同算法的子类。这样,以后再追加其它算法实现的ageng就比较方便。
class Agent:
def __init__(self,symbol):
self.state_history = []
self.estimations = dict()
self.symbol = symbol
self.greedy = []
self.name = None
for hash_val in all_states:
state, is_end = all_states[hash_val]
if is_end:
if state.winner == self.symbol:
self.estimations[hash_val] = 1.0
elif state.winner == 0:
# we need to distinguish between a tie and a lose
self.estimations[hash_val] = 0.5
else:
self.estimations[hash_val] = 0
else:
self.estimations[hash_val] = 0.5
def reset(self):
self.state_history = []
def set_state(self, state): # seems better to rename to add_state
self.state_history.append(state)
self.greedy.append(True)
def action(self):
pass
def save_policy(self):
pass
def load_policy(self):
pass在Agent类中实现了一些公共的成员和方法,有些方法只是提供了接口,具体实现留待子类中去实现(这类方法在其它OOP语言有一个名称叫做虚方法,但是python的OOP特性方面还不太熟悉,就先这样对付着了)。
save_policy()和load_policy()分别用于保存训练好的策略数据以及加载已经存在的策略数据,类似于机器学习中模型的保存和加载。这样就避免了每次运行都要重新进行训练的问题。
在当前的实现中只有TD0Agent需要进行训练,使用了这两个方法。
3.3.1 class TD0Agent(Agent)
TD0Agent就是基于一阶时序差分方式实现的agent。其中关键的两个方法是value_update()和action()。其中value_update()用于每个棋局结束时以反向的方式更新所有各状态的价值估计,这个在第2章已经解释了这里不再赘述。
action()中考虑了基于epsilon参数控制的explore和exploit的的控制。根据epsilon所指定的概率,有时选择explore,即随机选择下一步落子点;有时选择exploit,即基于价值估计最大的基准来选择下一步落子点。归根结底,这是一种epsilon-greedy策略。
# choose an action based on the state
def action(self):
state = self.state_history[-1]
next_states = []
next_positions = []
for i in range(BOARD_ROWS):
for j in range(BOARD_COLS):
if state.board[i, j] == 0:
next_positions.append([i, j])
next_states.append(state.next_state(
i, j, self.symbol).hash())
if np.random.rand() < self.epsilon:
action = next_positions[np.random.randint(len(next_positions))]
action.append(self.symbol)
self.greedy[-1] = False
return action
values = []
for hash_val, pos in zip(next_states, next_positions):
values.append((self.estimations[hash_val], pos))
# to select one of the actions of equal value at random due to Python's sort is stable
np.random.shuffle(values)
values.sort(key=lambda x: x[0], reverse=True)
action = values[0][1]
action.append(self.symbol)
return action3.3.2 class MinimaxAgent
在上一篇中我已经实现了基于Minimax的Unbeatable TicTacToe Agent,但是并没有以OOP的方式实现。为了嵌入到本文的OOP框架中,我将代码改写为类的实现。
此外,在上一篇中由于只实现了人机对弈,所以没有关心运行速度的问题(比较人通过鼠标落子一步所需要的时间对于计算机来说已经是沧海桑田般漫长了)。但是在实现各种不同agent自动对战时才发现原始的Minimax实现太慢了。所以,这里也一并做了改造。关键的要点是采用动态规划中常用的memoization(记忆化)技巧,将已经计算过的状态信息保存下来,以避免重复计算浪费时间(相当于是用空间换时间策略),如下所示:
cache_key = state.hash()
# Memoization can improve time efficiency by more than two order of magnitude.
if cache_key in self.cache:
bestMove, bestScore = self.cache[cache_key]
# print('minimax(): Recover from cache: {0}, {1} '.format(bestMove, bestScore))
return bestMove, bestScore这一改造将运行速度提高了大概2到3个数量级,非常惊人!
3.3.3 class RandomAgent(Agent)
顾名思义,RandomAgent就是傻傻地在遵守最基本规则的前提下随机地选择可落子的地方进行落子。其action代码如下:
# choose an action from the available empty positions randomly
def action(self):
state = self.state_history[-1]
next_states = []
next_positions = []
for i in range(BOARD_ROWS):
for j in range(BOARD_COLS):
if state.board[i, j] == 0:
next_positions.append([i, j])
next_states.append(state.next_state(
i, j, self.symbol).hash())
action = next_positions[np.random.randint(len(next_positions))]
action.append(self.symbol)
return action其目的是作为一个基准,用于人工智能Agent的测试对比。如果人工智能算法实现正确的话,肯定应该相对于RandomAgent具有压倒性优势。
3.3.4 class HumanPlayer(Agent)
HumanPlayer是用于实现人机对弈而实现的。它的action实现如下所示,主要就是给出盘面状态,并提示人类棋手输入下一步棋。在本实现中,用二维坐标(i,j)来表示落子位置。如果输入“q”的话就表示放弃当前棋局,如果人类棋手输入了数字对,但是不符合规则(比如说,落在了已经落子的位置,或者落在了棋盘外)的话,会重复提示用户输入正确的位置。
def action(self):
state = self.state_history[-1]
state.print_state()
# loop until human make a legal move
while True:
try:
move = input("Enter box location to make your move in format of [i,j], 'q' to abort : ")
if move == 'q':
return -1,-1,-1
c1, c2 = move.split(',')
if not c1.isdigit() or not c2.isdigit():
print("Please enter valid move [i,j], each number between 0 and {0}".format(BOARD_ROWS-1))
else:
i,j = int(c1.strip()),int(c2.strip())
break
except:
print("Please enter valid move [i,j], each number between 0 and {0}".format(BOARD_ROWS-1))
return [i, j, self.symbol]3.4 棋盘和玩家的表示
符号表示:棋盘(图形化)显示时,用X表示先手方,O表示后手方,空格表示未落子处;内部计算时,用1表示先手方,-1表示后手方,0表示未落子处。即{1,0,-1} --> {“X”, empty, “O”}.
4. Utility Function
除了以上几个类的实现以外,本程序中还实现了以下一些Utility函数用于实现TD0Agent的训练、单局游戏、自动对战、人机对战等目的。此外,还有所有状态的预计算。
4.1 所有状态预计算
本实现中由于状态数有限,所以对所有可能出现的状态及其是否终局等信息进行了预计算并保存下来,代码如下所示:
def get_all_states_impl(current_state, current_symbol, all_states):
for i in range(BOARD_ROWS):
for j in range(BOARD_COLS):
if current_state.board[i][j] == 0:
new_state = current_state.next_state(i, j, current_symbol)
new_hash = new_state.hash()
if new_hash not in all_states:
is_end = new_state.is_end()
all_states[new_hash] = (new_state, is_end)
if not is_end:
get_all_states_impl(new_state, -current_symbol, all_states)
def get_all_states():
current_symbol = 1
current_state = State()
all_states = dict()
all_states[current_state.hash()] = (current_state, current_state.is_end())
get_all_states_impl(current_state, current_symbol, all_states)
return all_states
# all possible board configurations
all_states = get_all_states()以上实现采用了深度优先遍历的算法。我在前面的博客(Tic-Tac-Toe可能棋局遍历的实现(python))中也实现了我的遍历搜索所有可能的棋局和状态的程序,有兴趣的话可以参考关于如何进行遍历搜索的算法说明。
注意,对于更大规模的对弈游戏,这种策略就不一定可行,需要改用动态计算和判断的方式实现。比如说如果从3x3的棋盘扩展到4x4或者5x5,可能的状态数就会剧烈增长,更不用提像象棋、围棋那种游戏了。
4.2 play_one_game,单局对战
单局对战的处理流程(伪代码)如下所示(基本上就是强化学习的agent-env标准框架的描述直接应用到本游戏中来,只不过这里有两个agent):
Def play_one_game(agent1, agent2,env)àwinner, reward:
# Assuming three objects are passed as input parameter. The object instantiation are done in top level.
Env.reset() # no need of agent1,2 reset.
Agent1.reset() # agent reset doesn’t reset value function data
Agent2.reset()
While True:
Agt1 decides the next action
Env.step(agt1.action)
如果是终局局面,跳出循环
Agt2 decides the next action
Env.step(agt2.action)
如果是终局局面,跳出循环
Agt1 accept updated state from env
Agt2 accept updated state from env
4.3 TD0_train(epochs, print_every_n=500)
初始化:Agent1、agent2、env对象创建,及其它变量初始化
While 训练局数未满:
play_one_game(agent1, agent2,env)
胜负信息统计
player1.value_update() # 注意,每一局棋结束后才进行以此价值函数更新!
player2.value_update()
保存policy
def TD0_train(epochs, print_every_n=500):
player1 = TD0Agent(symbol=1, epsilon=0.01)
player2 = TD0Agent(symbol=-1,epsilon=0.01)
env = Env()
player1_win = 0.0
player2_win = 0.0
for i in range(1, epochs + 1):
winner = play_one_game(player1, player2, env)
if winner == 1:
player1_win += 1
if winner == -1:
player2_win += 1
if i % print_every_n == 0:
print('Epoch %d, player 1 winrate: %.02f, player 2 winrate: %.02f' % (i, player1_win / i, player2_win / i))
player1.value_update()
player2.value_update()
env.reset()
player1.save_policy()
player2.save_policy()就是一个单纯的多局循环,每次循环中调用play_one_game()进行一局对局。然后,调用value_update()函数进行价值估计更新,这个是训练的核心之所在,也就和时序差分算法核心的实现。
4.4 compete(agent1, agent2, num_games)
初始化:Agent1、agent2、env对象创建,及其它变量初始化
根据需要agents加载策略模型
While 对战局数未满:
play_one_game(agent1, agent2,env)
胜负信息统计
player1.value_update() # 注意,每一局棋结束后才进行以此价值函数更新!
player2.value_update()
打印胜负统计信息
本函数实现了两个指定的agent的对战,用于各种不同agent之间的实力对比测试,
def compete(agent1, agent2, num_games):
# agent1 play first
if agent1 == 'TD0Agent':
player1 = TD0Agent(symbol=1,epsilon=0)
elif agent1 == 'MinimaxAgent':
player1 = MinimaxAgent(symbol=1)
elif agent1 == 'RandomAgent':
player1 = RandomAgent(symbol=1)
else:
print('Invalid agent name {0} for agent1!'.format(agent1))
return;
if agent2 == 'TD0Agent':
player2 = TD0Agent(symbol=-1, epsilon=0)
elif agent2 == 'MinimaxAgent':
player2 = MinimaxAgent(symbol=-1)
elif agent2 == 'RandomAgent':
player2 = RandomAgent(symbol=-1)
else:
print('Invalid agent name {0} for agent2!'.format(agent2))
return;
player1_win = 0.0
player2_win = 0.0
env = Env()
player1.load_policy()
player2.load_policy()
t_start = time.time()
for _ in range(num_games):
winner = play_one_game(player1, player2, env)
if winner == 1:
player1_win += 1
if winner == -1:
player2_win += 1
env.reset()
player1_winrate = player1_win / num_games
player2_winrate = player2_win / num_games
draw_rate = 1 - player1_winrate - player2_winrate
t_stop = time.time()
print('{0} games, {1:12}_win: {2:.02f}, {3:12}_win: {4:.02f}, draw_rate = {5:.02f}, tCost = {6:.02f}(sec) '.\
format(num_games, player1.name, player1_winrate, player2.name, player2_winrate, draw_rate, t_stop-t_start))
return除了输入初始化处理(根据输入参数进行指定agent对象的实例化) 外,对局循环部分与TD0_train()其实是一样的,只不过由于是纯粹的对战,所以不需要调用value_update()函数进行价值估计更新。
另外,对于TD0Agent,在训练时需要指定epsilon为非0,而在对战测试时则需要指定为0.
4.5 play_human_vs_agent(agent_name)
这个函数用于实现人机对战。输入参数用于指定对战用的计算机agent。代码实现如下:
def askGameStart():
# Ask human start a game or not;
print('Do you want to start a game? Y or y to start; Others to exit');
inputWord = input().lower();
if inputWord.startswith('y'):
startNewGame = True;
else:
startNewGame = False;
return startNewGame
def play_human_vs_agent(agent_name):
while askGameStart():
# Decide who, either human or AI, play first.
# 0: computer; 1: human.
print('Who play first? [0: computer; 1: human; enter: guess first]');
cmd = input()
if not cmd.isdigit():
who_first = random.randint(0,1);
else:
if int(cmd)==0:
who_first = 0
else:
who_first = 1
if who_first == 1: # HumanPlayer first
print('You play first!')
player1 = HumanPlayer(symbol=1 )
if agent_name == 'TD0Agent':
player2 = TD0Agent(symbol=-1, epsilon=0)
elif agent_name == 'MinimaxAgent':
player2 = MinimaxAgent(symbol=-1)
elif agent_name == 'RandomAgent':
player2 = RandomAgent(symbol=-1)
else:
print('Invalid agent name {0} for agent!'.format(agent_name))
return;
player2.load_policy()
else: # Computer first
print('Computer play first!')
player2 = HumanPlayer(symbol=-1 )
if agent_name == 'TD0Agent':
player1 = TD0Agent(symbol=1, epsilon=0)
elif agent_name == 'MinimaxAgent':
player1 = MinimaxAgent(symbol=1)
elif agent_name == 'RandomAgent':
player1 = RandomAgent(symbol=1)
else:
print('Invalid agent name {0} for agent!'.format(agent_name))
return;
player1.load_policy()
env = Env()
winner = play_one_game(player1, player2, env)
if winner == (2*who_first-1):
print("You win!")
elif winner == (1-2*who_first):
print("You lose!")
elif winner == 0:
print("A tie game!")
else:
print("Abort the game!")5. 对战测试
最后,基于以上实现进行了三种agent(RandomAgent、TD0Agent、MinimaxAgent)之间的对战测试(当然,TD0Agent需要先进行训练,如以下被注释掉的第2行语句,训练完以后会生成policy_first.bin和policy_second.bin,然后就可以关掉该语句进行对战测试了)。
if __name__ == '__main__':
# TD0_train(int(1e4))
num_games = 1000
compete("TD0Agent", "TD0Agent", num_games)
compete("RandomAgent", "TD0Agent", num_games)
compete("TD0Agent", "RandomAgent", num_games)
compete("RandomAgent", "RandomAgent", num_games)
compete("RandomAgent", "MinimaxAgent", num_games)
compete("MinimaxAgent", "RandomAgent", num_games)
compete("MinimaxAgent", "MinimaxAgent", num_games)
compete("TD0Agent", "MinimaxAgent", num_games)
compete("MinimaxAgent", "TD0Agent", num_games)
try:
play_human_vs_agent('TD0Agent')
except:
play_human_vs_agent('TD0Agent')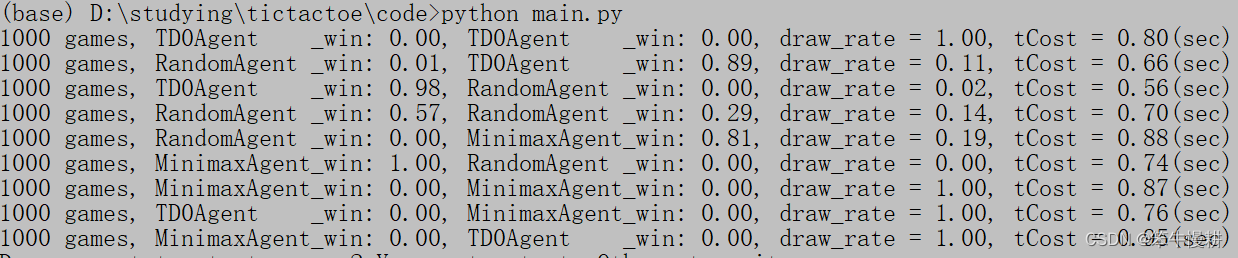 从结果来看,TD0Agent和MinimaxAgent不管是自我对战还是相互对战,部分先后手,都是100%的平局,这个是符合预期的。一方面TicTacToe比较简单,理论上双方都能走最优解的话就必然是平局。这个结果表明,TD0Agent和MinimaxAgent基本上都正确实现了。
从结果来看,TD0Agent和MinimaxAgent不管是自我对战还是相互对战,部分先后手,都是100%的平局,这个是符合预期的。一方面TicTacToe比较简单,理论上双方都能走最优解的话就必然是平局。这个结果表明,TD0Agent和MinimaxAgent基本上都正确实现了。
两个RandomAgent之间对战的话,先手方约60%弱胜,后手方约30%弱胜,其余平局,这个也是符合预期的。对所有可能棋局的遍历结果的仿真分析可以得到这同样的结果。因此可以说,两个RandomAgent之间进行对战的话,只要对局数足够大的话,总能遍历所有可能的棋局。关于总共可能有多少种可能的棋局,可以参考博客【3】。
MinimaxAgent作为先手与RandomAgent对战的话100%取胜,这个符合预期,毕竟本来先手就有优势,再加上算法加持,100%毫不意外(但是这个100%也可能是因为对局数还不够多所致)。但是MinimaxAgent作为后手的话,只能保证81%的胜率,考虑到先手优势以及Random可能随机地走出最优步骤确保平局,这个结果可以理解。但是甚至比RandomAgent-vs-TD0Agent时TD0Agent要低,这个有点意外,原因待分析。
RandomAgent-vs-TD0Agent以及RandomAgent-vs-TD0Agent的结果也基本符合预期。但是RandomAgent先手时居然还能够取得一些胜局,这个只能说明TD0Agent训练得还不够充分,还没有达到完美决策的水平。但是,如上所示,TD0Agent作为后手对战RandomAgent时的胜率比MinimaxAgent要高,这个有点费解,原因待分析。
以上结果可能因为对局数(1000)的不足而有一定的偏差。要对以上问题进行进一步分析,可以考虑增加对局数、增加TD0Agent的训练长度等等。。。
完整的代码参见:tictactoe-chenxy.py。
参考文献:
【1】Sutton, Reinforcement Learning: An introduction
【2】GitHub - ShangtongZhang/reinforcement-learning-an-introduction
【3】Tic-Tac-Toe有多少种不同棋局和盘面状态(python实现)