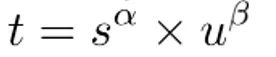PG15新特性-加速WAL日志归档
PG15通过:一次扫描64个待归档的日志,将其放到一个数组中以供归档,当处理完这64个文件后,再进行下一次扫描。这样达到减少archive_status目录扫描次数提升性能的目的。
WAL归档
介绍PG15如何加速归档前,先看下PG14及老版本如何归档的。
PG在pg_wal目录产生WAL段文件时,会在pg_wal/archive_status子目录产生相关的.ready文件。例如:
$ ls -alrth pg_wal/
drwx------ 3 postgres postgres 68 Dec 7 05:47 .
drwx------ 21 postgres postgres 32 Dec 21 03:54 ..
-rw------- 1 postgres postgres 16M Dec 21 04:38 0000000200000008000000E4
-rw------- 1 postgres postgres 16M Dec 21 04:38 0000000200000008000000E5
-rw------- 1 postgres postgres 16M Dec 21 04:38 0000000200000008000000E6
-rw------- 1 postgres postgres 16M Dec 21 04:38 0000000200000008000000E7
drwx------ 2 postgres postgres 6 Dec 21 04:38 archive_status
-rw------- 1 postgres postgres 16M Dec 21 04:38 0000000200000008000000E8
-bash-4.2$ ls -alrth pg_wal/archive_status/
total 5.0K
drwx------ 3 postgres postgres 68 Dec 7 05:47 ..
-rw------- 1 postgres postgres 0 Dec 21 04:38 0000000200000008000000E4.ready
-rw------- 1 postgres postgres 0 Dec 21 04:38 0000000200000008000000E5.ready
-rw------- 1 postgres postgres 0 Dec 21 04:38 0000000200000008000000E6.ready
-rw------- 1 postgres postgres 0 Dec 21 04:38 0000000200000008000000E7.ready
drwx------ 2 postgres postgres 6 Dec 21 04:38 .这表示WAL文件0000000200000008000000E7准备好归档了,0000000200000008000000E8是当前使用的WAL文件,还没有准备好归档。
postgres=# SELECT pg_walfile_name(pg_current_wal_lsn());
pg_walfile_name
--------------------------
0000000200000008000000E8
(1 row)一旦WAL日志归档到backup位置(归档目标),状态改成.done:
$ ls -alrth pg_wal/archive_status/
total 5.0K
drwx------ 3 postgres postgres 68 Dec 7 05:47 ..
-rw------- 1 postgres postgres 0 Dec 21 04:38 0000000200000008000000E4.done
-rw------- 1 postgres postgres 0 Dec 21 04:38 0000000200000008000000E5.done
-rw------- 1 postgres postgres 0 Dec 21 04:38 0000000200000008000000E6.done
-rw------- 1 postgres postgres 0 Dec 21 04:38 0000000200000008000000E7.donePG使用这些状态文件了解哪些是待归档的日志文件。PG扫描目录pg_wal/archive_status/从而了解哪个是还没有归档的最老的WAL段文件。PG的归档进程每60秒(默认)被唤醒一次,并尝试执行内部函数pgarch_ArchiverCopyLoop()来处理每个挂起的WAL段文件;依次为每个WAL段文件执行archive_command。当WAL归档应以正确的顺序发生,并只针对剩余的WAL段文件。接下来要处理哪个WAL段文件由函数pgarch_readyXlog()决定。PG代码中注释可以说明整个流程:
/*
* pgarch_readyXlog
*
* Return name of the oldest xlog file that has not yet been archived.
* No notification is set that file archiving is now in progress, so
* this would need to be extended if multiple concurrent archival
* tasks were created. If a failure occurs, we will completely
* re-copy the file at the next available opportunity.
*
* It is important that we return the oldest, so that we archive xlogs
* in order that they were written, for two reasons:
* 1) to maintain the sequential chain of xlogs required for recovery
* 2) because the oldest ones will sooner become candidates for
* recycling at time of checkpoint
*
* NOTE: the "oldest" comparison will consider any .history file to be older
* than any other file except another .history file. Segments on a timeline
* with a smaller ID will be older than all segments on a timeline with a
* larger ID; the net result being that past timelines are given higher
* priority for archiving. This seems okay, or at least not obviously worth
* changing.
*/问题
pgarch_readyXlog()函数需要扫描pg_wal/archive_status/目录下的文件来决定哪个文件是下一个归档候选者。因此,对于每个要归档的WAL文件来说,实际上都会导致完整的目录扫描。
如果pg_wal/archive_status/中有数千或者数百万个文件怎么办?这发生在大事务系统中,WAL归档无法在高峰时段赶上WAL生成,或者如果WAL归档在一段时间内失败了。一旦积累了大量的.ready状态文件,目录扫描本身就会花费更多时间。这样,WAL归档赶上的机会就变得非常渺茫了。
PG14及之前版本唯一的解决方案是:尝试将wal_segment_size增大,以便产生更少梳理的文件。可以将默认的16MB增加到1GB来解决整个问题。当然,这是一个不太好的解决方法,如果需要recovery备份,就会带来明显的后果,比如大量数据丢失。
PG15如何解决这个问题
邮件列表中讨论了各种解决方案和补丁:
https://www.postgresql.org/message-id/flat/CA%2BTgmobhAbs2yabTuTRkJTq_kkC80-%2Bjw%3DpfpypdOJ7%2BgAbQbw%40mail.gmail.com
总结出两种方法:
1)扫描目录并将结果保存到数组中,并为archive_command或模块提供相同的结果。即使这可以大大减少目录扫描次数,但是仍旧会扫描目录,复杂性O(n2)
2)另一个更加巧妙的方法是预测下一个WAL段文件(基于WAL文件名格式)并尝试在目录中查看相同的文件。逻辑的主要部分中可以避免目录扫描。
采取哪一种方法是一个非常困难的决定。权衡所有影响后,选则了第一种方法,即将WAL段文件名保存在一个数组种。主要是因为这个数组可以进一步改进依次将多个文件发送到archive_command或模块,这是另一个改进的地方。
PG15种如何工作
这个想法是:用.ready文件扫描archive_status目录,并将要归档的WAL文件列表累积到一个数组中。数组的大小可以在编译的时会使用常量来定义:
/*
* Maximum number of .ready files to gather per directory scan.
*/
#define NUM_FILES_PER_DIRECTORY_SCAN 64因此,在处理完64个.ready文件后,再进行目录扫描。
由于将时间线历史文件推送到归档非常重要,因此它将优先于WAL段文件。通过时间线切换时触发目录扫描来完成。
总体而言,社区报告中性能提升了20倍或更多。
更好地监控WAL归档
PG15添加了一组新的wait_events,以便更好地观察和排除WAL归档、恢复、清理阶段的故障。
ArchiveCleanupCommand | 等待archive_cleanup_command完成. |
ArchiveCommand | 等待archive_command完成. |
RecoveryEndCommand | 等待recovery_end_command完成. |
RestoreCommand | 等待restore_command完成. |
这些等待事件监控可以告诉我们在特定操作上花费的时间是多少。例如,等待事件“ArchiveCommand”告诉我们“archive_command”中指定的shell命令正在执行中。
向pg_gather这样的工具/脚本可以有效地利用这些等待来了解执行archive_command所花费的事件百分比以及archive_command的速度是否是WAL归档的瓶颈。

原文
https://www.percona.com/blog/speed-up-of-the-wal-archiving-in-postgresql-15/