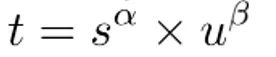这次关注一下最关键的东西:用什么网络,用什么数据,预训练数据在哪里呢?
为了方便,重新贴一下 train.py
import torch
import argparse
import yaml
import time
import multiprocessing as mp
from tabulate import tabulate
from tqdm import tqdm
from torch.utils.data import DataLoader
from pathlib import Path
from torch.utils.tensorboard import SummaryWriter
from torch.cuda.amp import GradScaler, autocast
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data import DistributedSampler, RandomSampler
from torch import distributed as dist
from semseg.models import *
from semseg.datasets import *
from semseg.augmentations import get_train_augmentation, get_val_augmentation
from semseg.losses import get_loss
from semseg.schedulers import get_scheduler
from semseg.optimizers import get_optimizer
from semseg.utils.utils import fix_seeds, setup_cudnn, cleanup_ddp, setup_ddp
from val import evaluate
def main(cfg, gpu, save_dir):
start = time.time()
best_mIoU = 0.0
num_workers = mp.cpu_count()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#device = torch.device(cfg['DEVICE'])
train_cfg, eval_cfg = cfg['TRAIN'], cfg['EVAL']
dataset_cfg, model_cfg = cfg['DATASET'], cfg['MODEL']
loss_cfg, optim_cfg, sched_cfg = cfg['LOSS'], cfg['OPTIMIZER'], cfg['SCHEDULER']
epochs, lr = train_cfg['EPOCHS'], optim_cfg['LR']
traintransform = get_train_augmentation(train_cfg['IMAGE_SIZE'], seg_fill=dataset_cfg['IGNORE_LABEL'])
valtransform = get_val_augmentation(eval_cfg['IMAGE_SIZE'])
trainset = eval(dataset_cfg['NAME'])(dataset_cfg['ROOT'], 'train', traintransform)
valset = eval(dataset_cfg['NAME'])(dataset_cfg['ROOT'], 'val', valtransform)
model = eval(model_cfg['NAME'])(model_cfg['BACKBONE'], trainset.n_classes)
model.init_pretrained(model_cfg['PRETRAINED'])
model = model.to(device)
if train_cfg['DDP']:
sampler = DistributedSampler(trainset, dist.get_world_size(), dist.get_rank(), shuffle=True)
model = DDP(model, device_ids=[gpu])
else:
sampler = RandomSampler(trainset)
trainloader = DataLoader(trainset, batch_size=train_cfg['BATCH_SIZE'], num_workers=num_workers, drop_last=True, pin_memory=True, sampler=sampler)
valloader = DataLoader(valset, batch_size=1, num_workers=1, pin_memory=True)
iters_per_epoch = len(trainset) // train_cfg['BATCH_SIZE']
# class_weights = trainset.class_weights.to(device)
loss_fn = get_loss(loss_cfg['NAME'], trainset.ignore_label, None)
optimizer = get_optimizer(model, optim_cfg['NAME'], lr, optim_cfg['WEIGHT_DECAY'])
scheduler = get_scheduler(sched_cfg['NAME'], optimizer, epochs * iters_per_epoch, sched_cfg['POWER'], iters_per_epoch * sched_cfg['WARMUP'], sched_cfg['WARMUP_RATIO'])
scaler = GradScaler(enabled=train_cfg['AMP'])
writer = SummaryWriter(str(save_dir / 'logs'))
for epoch in range(epochs):
model.train()
if train_cfg['DDP']: sampler.set_epoch(epoch)
train_loss = 0.0
pbar = tqdm(enumerate(trainloader), total=iters_per_epoch, desc=f"Epoch: [{epoch+1}/{epochs}] Iter: [{0}/{iters_per_epoch}] LR: {lr:.8f} Loss: {train_loss:.8f}")
for iter, (img, lbl) in pbar:
optimizer.zero_grad(set_to_none=True)
img = img.to(device)
lbl = lbl.to(device)
with autocast(enabled=train_cfg['AMP']):
logits = model(img)
loss = loss_fn(logits, lbl)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
scheduler.step()
torch.cuda.synchronize()
lr = scheduler.get_lr()
lr = sum(lr) / len(lr)
train_loss += loss.item()
pbar.set_description(f"Epoch: [{epoch+1}/{epochs}] Iter: [{iter+1}/{iters_per_epoch}] LR: {lr:.8f} Loss: {train_loss / (iter+1):.8f}")
train_loss /= iter+1
writer.add_scalar('train/loss', train_loss, epoch)
torch.cuda.empty_cache()
if (epoch+1) % train_cfg['EVAL_INTERVAL'] == 0 or (epoch+1) == epochs:
miou = evaluate(model, valloader, device)[-1]
writer.add_scalar('val/mIoU', miou, epoch)
if miou > best_mIoU:
best_mIoU = miou
torch.save(model.module.state_dict() if train_cfg['DDP'] else model.state_dict(), save_dir / f"{model_cfg['NAME']}_{model_cfg['BACKBONE']}_{dataset_cfg['NAME']}.pth")
print(f"Current mIoU: {miou} Best mIoU: {best_mIoU}")
writer.close()
pbar.close()
end = time.gmtime(time.time() - start)
table = [
['Best mIoU', f"{best_mIoU:.2f}"],
['Total Training Time', time.strftime("%H:%M:%S", end)]
]
print(tabulate(table, numalign='right'))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--cfg', type=str, default='configs/custom.yaml', help='Configuration file to use')
args = parser.parse_args()
with open(args.cfg) as f:
cfg = yaml.load(f, Loader=yaml.SafeLoader)
fix_seeds(3407)
setup_cudnn()
gpu = setup_ddp()
save_dir = Path(cfg['SAVE_DIR'])
save_dir.mkdir(exist_ok=True)
main(cfg, gpu, save_dir)
cleanup_ddp()一、model_cfg
上面第32行,本质说的是
model_cfg = cfg['MODEL']
你看在custom.yaml中,
MODEL:
NAME : SegFormer # name of the model you are using
BACKBONE : MiT-B2 # model variant
PRETRAINED : 'checkpoints/backbones/mit/mit_b2.pth' # backbone model's weight第42行,重量级代码来了
model = eval(model_cfg['NAME'])(model_cfg['BACKBONE'], trainset.n_classes)model_cfg['NAME']其实就是'SegFormer'
这就需要细心地你,注意第15、16行如下:
from semseg.models import *
from semseg.datasets import * 那么,第42行,就是要实现SegFormer类,并且BACKBONE 为 MiT-B2
第43行,说的是预训练模型
model.init_pretrained(model_cfg['PRETRAINED'])你会发现,init_pretrained是个多态的,在这里,由于model已经是SegFormer类,而在SegFormer中,继承了BaseModel,所以,执行的是BaseModel的init_pretrained.
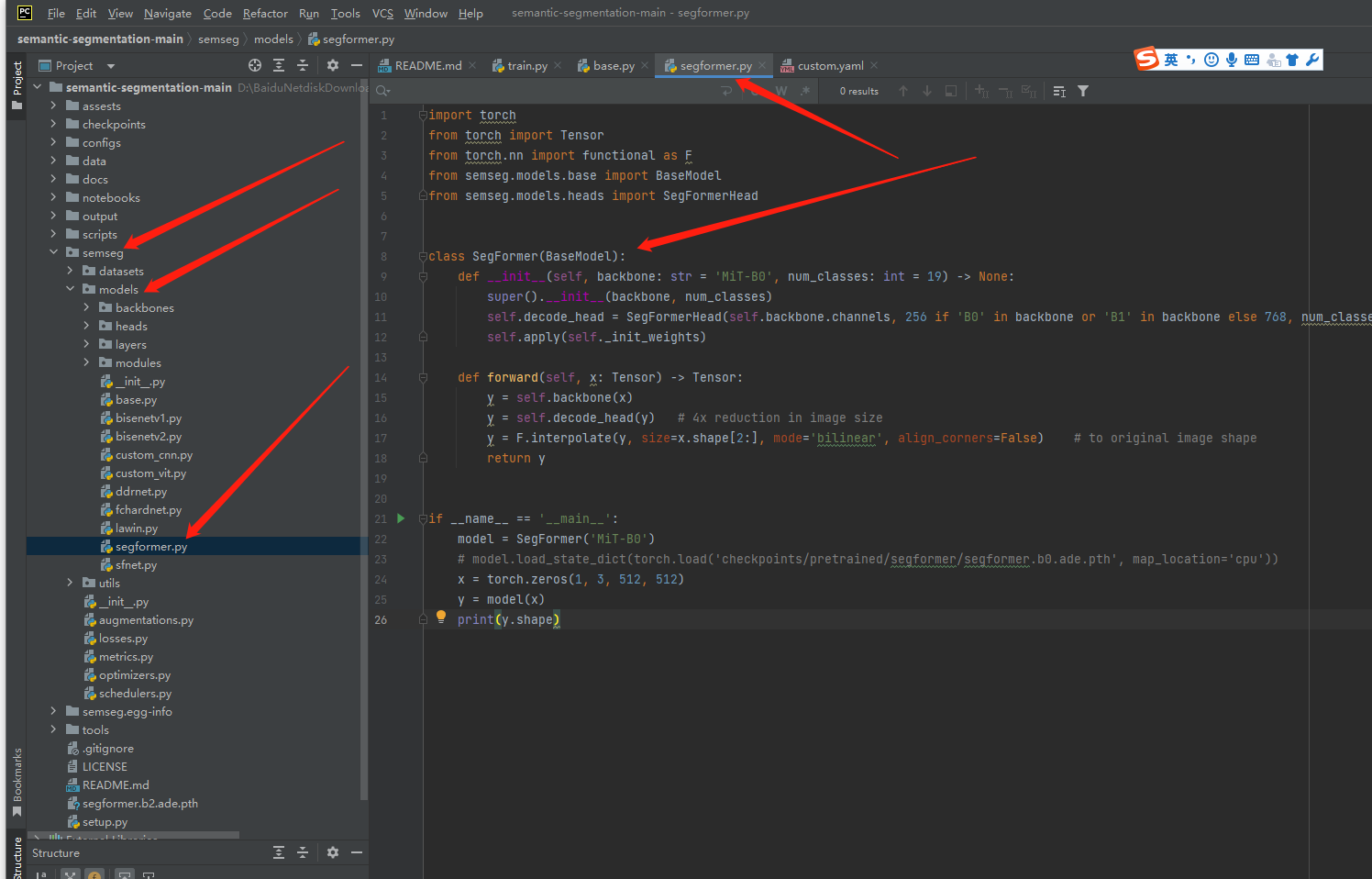
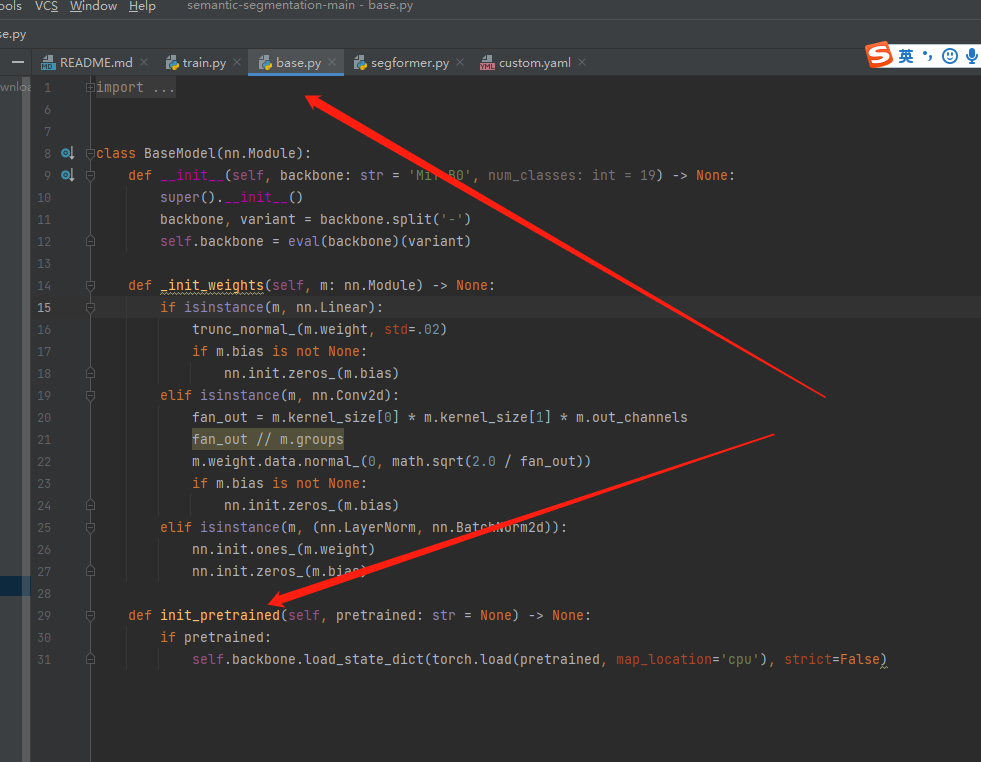
所以,43行执行的是啥?
model.init_pretrained(model_cfg['PRETRAINED'])预训练模型来自model_cfg['PRETRAINED']
对于我来说,
PRETRAINED : 'checkpoints/backbones/mit/mit_b2.pth' # backbone model's weight
细心的你,
BACKBONE : MiT-B2 # model variant
还没用上呢。
再看一遍segformer.py:
import torch
from torch import Tensor
from torch.nn import functional as F
from semseg.models.base import BaseModel
from semseg.models.heads import SegFormerHead
class SegFormer(BaseModel):
def __init__(self, backbone: str = 'MiT-B0', num_classes: int = 19) -> None:
super().__init__(backbone, num_classes)
self.decode_head = SegFormerHead(self.backbone.channels, 256 if 'B0' in backbone or 'B1' in backbone else 768, num_classes)
self.apply(self._init_weights)
def forward(self, x: Tensor) -> Tensor:
y = self.backbone(x)
y = self.decode_head(y) # 4x reduction in image size
y = F.interpolate(y, size=x.shape[2:], mode='bilinear', align_corners=False) # to original image shape
return y
if __name__ == '__main__':
model = SegFormer('MiT-B0')
# model.load_state_dict(torch.load('checkpoints/pretrained/segformer/segformer.b0.ade.pth', map_location='cpu'))
x = torch.zeros(1, 3, 512, 512)
y = model(x)
print(y.shape)上面第11行,就用上了backbone。
二、model_cfg总结
MODEL:
NAME : SegFormer # name of the model you are using
BACKBONE : MiT-B2 # model variant
PRETRAINED : 'checkpoints/backbones/mit/mit_b2.pth' # backbone model's weightNAME 决定了采用哪个类。
BACKBONE 决定了用哪个backbone
PRETRAINED 决定了预编译文件
他们之间是有约束关系的,不是随便乱选。
三、train_cfg
TRAIN:
IMAGE_SIZE : [512, 512] # training image size in (h, w)
BATCH_SIZE : 2 # batch size used to train
EPOCHS : 6 # number of epochs to train
EVAL_INTERVAL : 2 # evaluation interval during training
AMP : false # use AMP in training
DDP : false # use DDP training四、dataset_cfg
DATASET:
NAME : HELEN # dataset name to be trained with (camvid, cityscapes, ade20k)
ROOT : 'data/SmithCVPR2013_dataset_resized' # dataset root path
IGNORE_LABEL : 255这里有意思不?
NAME : HELEN
怎么解释?
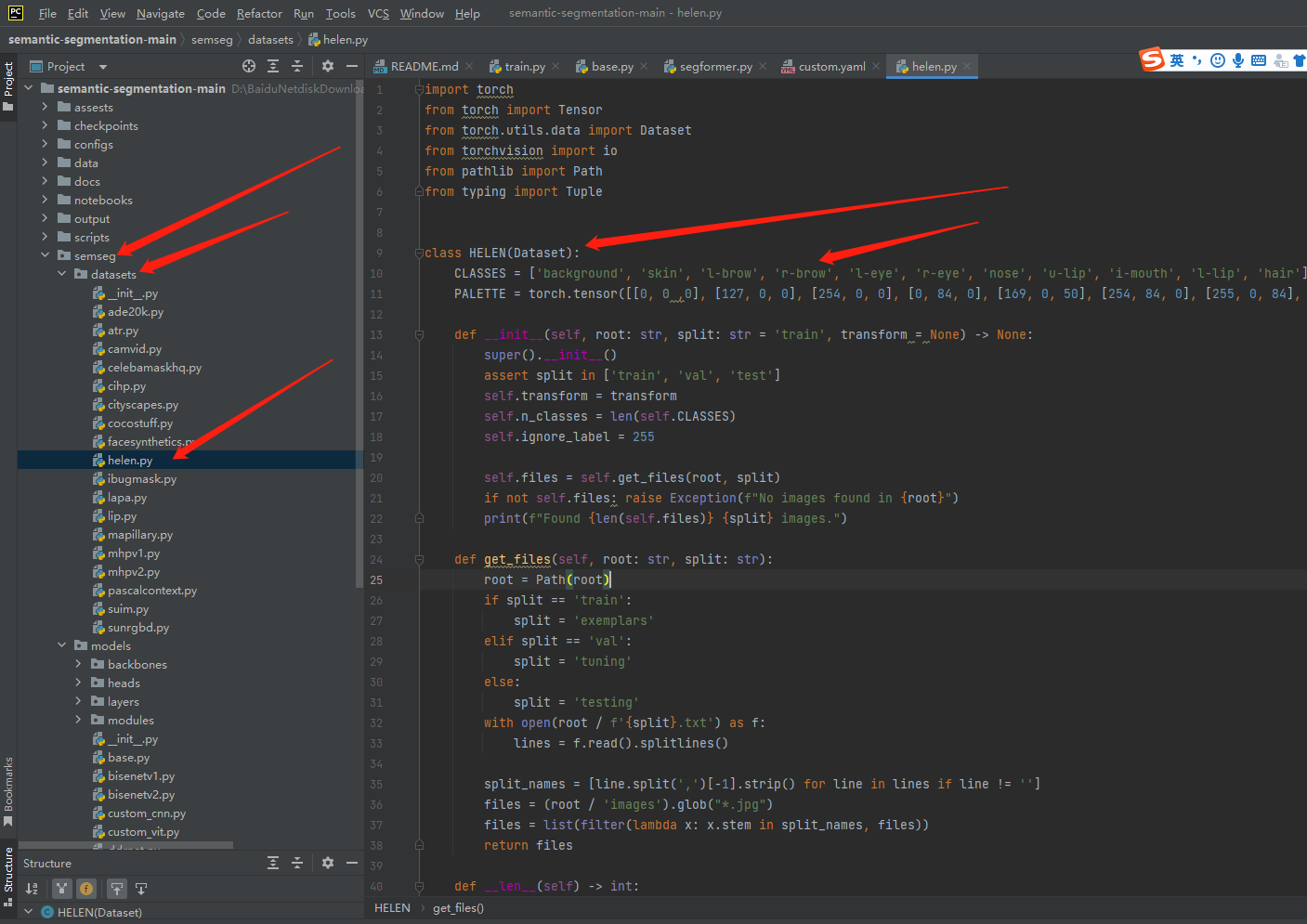

五、eval_cfg
EVAL:
MODEL_PATH : 'checkpoints/pretrained/ddrnet/ddrnet_23slim_city.pth' # trained model file path
IMAGE_SIZE : [1024, 1024] # evaluation image size in (h, w)
MSF:
ENABLE : false # multi-scale and flip evaluation
FLIP : true # use flip in evaluation
SCALES : [0.5, 0.75, 1.0, 1.25, 1.5, 1.75] # scales used in MSF evaluation