CRE-LLM:告别复杂特征工程,直接关系抽取
- 提出背景
- CRE-LLM 宏观分析
- CRE-LLM 微观分析
- 1. 构建指令集(Instruction Design)
- 2. 高效微调大型语言模型(Efficient Fine-Tuning on LLMs)
- 3. 方法讨论(Discussion of Methods)
- 应用场景:糖尿病治疗反应关系抽取
- 区别对比
- 1. 生成式方法与分类方法的区别
- 2. 指令监督的创新
- 3. 参数效率微调(PEFT)
- 4. 适应领域特定任务的灵活性
- 5. 直接关系提取
提出背景
论文:https://arxiv.org/pdf/2404.18085
代码:https://github.com/SkyuForever/CRE-LLM
在糖尿病领域,基于PLMs的关系抽取方法通常会使用预训练模型(如BERT和T5)来识别文本中的实体和关系。
例如,对于句子“糖尿病患者需要定期检查血糖”,一个基于PLMs的模型可能会识别出“糖尿病患者”作为实体,并提取出与“糖尿病患者”相关的关系,比如“需要定期检查”等。
而CRE-LLM框架则提供了一种新颖的方法来处理这种领域特定的关系抽取任务。
它不再依赖于传统的分类方法,而是利用微调的开源LLMs(如Llama2-7B、ChatGLM2-6B和Baichuan2-7B)通过生成过程直接识别给定实体之间的关系。
在糖尿病领域中,CRE-LLM可以根据给定的文本,例如“糖尿病患者需要定期检查血糖”,直接提取出与“糖尿病患者”相关的关系,而无需先进行实体识别。
这种方法可能会更高效,并且能够更好地适应特定领域的语言特点和语境。
给定一个句子:“该患者被诊断患有2型糖尿病。”
在这个句子中,我们可以识别出实体:患者(entity)、2型糖尿病(entity)。
然后,我们可以使用CRE-LLM框架来识别实体之间的关系。
在这种情况下,可能的关系可以是:
- 患者(entity)- 患有(relation)- 2型糖尿病(entity)
通过这种方式,我们可以利用CRE-LLM框架从给定的句子中提取出实体之间的关系,以帮助理解糖尿病领域的文本信息。
CRE-LLM :这种方法假设模型已经针对糖尿病领域得到了专门的训练和优化。
因此,当输入“糖尿病患者因胰岛素不足而经常感到疲劳”这句话时,模型不仅识别出实体和关系,还能直接输出具体的关系:“糖尿病患者”因“胰岛素不足”而“感到疲劳”,显示出胰岛素不足导致了疲劳。
CRE-LLM 宏观分析
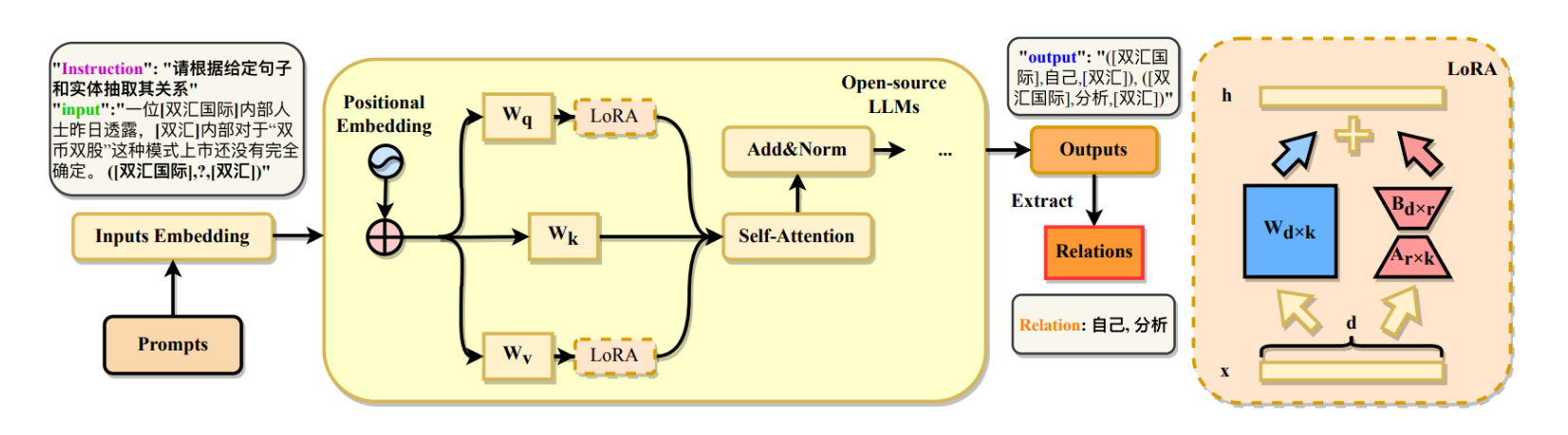
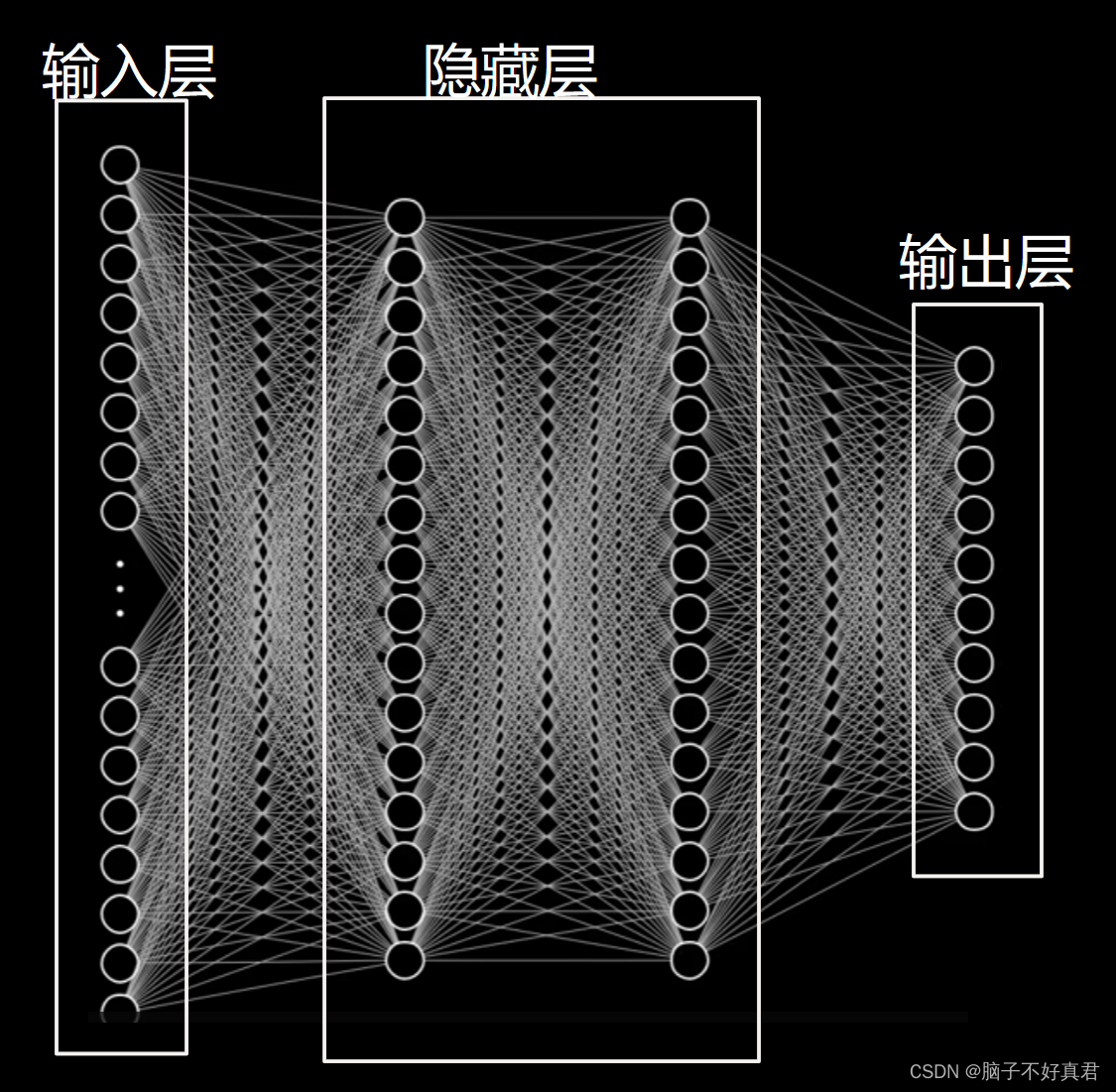
CRE-LLM的总览图
- 展示了CRE-LLM框架如何利用参数高效微调技术(例如LoRA)对领域特定的中文关系抽取进行操作。
- 输入嵌入后,通过LoRA模块和自注意力机制处理,最后输出结构,从而抽取关系。
- “Instructions”和“Input”是用于LLM的提示,指导模型关注任务的关键信息,最终“Output”输出指定实体间的关系。
CRE-LLM 微观分析
CRE-LLM是一个针对领域特定关系抽取(Domain-Specific Chinese Relation Extraction, DSCRE)的框架,它使用基于生成式问答的方法,并结合了指令监督下的大型语言模型(LLMs)微调技术。
CRE-LLM利用微调过的大型语言模型,通过自然语言的指令来引导模型提取和理解特定领域内实体之间的关系。
1. 构建指令集(Instruction Design)
-
子解法1:自然语言指令设计
- 特征:需要明确地指导模型理解和执行特定的任务,例如提取实体之间的关系。
- 原因:通过构建有效的自然语言指令,可以更直观地指引模型聚焦于关键信息,如实体和它们之间的关系。这样做增强了模型对任务的理解,提高了执行任务的准确性。
- 例子:在处理糖尿病相关的医疗记录时,指令可能是“识别文本中糖尿病患者的主要症状和导致这些症状的原因。”
-
子解法2:输入输出格式配置
- 特征:需要结构化的方式来定义模型如何接收输入并生成输出。
- 原因:合理的输入输出配置确保了数据在模型中的正确处理,使得输出的数据结构能够直接用于下一步的处理或分析。
- 例子:设定输入为“糖尿病患者报告说他们经常感到疲劳”,输出为“([糖尿病患者], 经常感到疲劳, 疲劳原因是[高血糖])”。
2. 高效微调大型语言模型(Efficient Fine-Tuning on LLMs)
- 子解法1:参数高效微调(PEFT)技术应用
- 特征:大型语言模型通常参数庞大,直接微调成本高。
- 原因:通过PEFT技术,如LoRA,可以仅对模型的部分关键参数进行调整,这样不仅降低了计算和存储的需求,还保持了模型的学习能力。
- 例子:在糖尿病病例分析中,使用PEFT技术微调模型处理“哪些药物对治疗疲劳有效?”的问题,只调整与药物和症状关系识别相关的模型部分。
3. 方法讨论(Discussion of Methods)
- 子解法1:生成式问答模式应用
- 特征:生成式问答能直接从文本生成答案,适用于复杂关系的提取。
- 原因:此方法能动态地根据问题的上下文生成关系答案,不受固定模式的限制,更适合处理多变和非结构化的医疗数据。
- 例子:在询问“糖尿病患者使用什么药物后疲劳减轻?”时,生成式问答模式能够直接提供药物名称和关联的效果描述。
这种方法通过将复杂的任务细分为特定的子任务来增强模型的针对性和效率,使其能够在特定领域,如糖尿病医疗数据中,进行更为精确的信息抽取和分析。
考虑使用CRE-LLM框架来处理糖尿病相关的医学文本。
在这个例子中,假设我们有一个包含丰富信息的医学数据库,其中包括糖尿病患者的详细病历和治疗记录。
我们的目标是从这些文本中提取出有关糖尿病患者的特定治疗反应和并发症的关系。
应用场景:糖尿病治疗反应关系抽取
-
输入数据:假设我们有以下句子作为输入数据:“张三因为糖尿病并发了视网膜病变,正在接受激光治疗。”
-
指令设计:为了引导模型正确抽取信息,我们设计一条指令:“请根据下面的描述提取糖尿病患者的并发症及其治疗方式。”这条指令被用来让模型聚焦于‘并发症’和‘治疗方式’这两个实体及其之间的关系。
-
模型运作:CRE-LLM通过这个指令开始分析文本,首先识别出“糖尿病”作为疾病实体,"视网膜病变"作为并发症实体,和"激光治疗"作为治疗方式实体。
-
关系提取:然后,模型使用其微调后的生成式能力,生成一个关系描述,这可能是:“糖尿病导致视网膜病变"和"视网膜病变正在接受激光治疗”。这些关系直接反映了疾病、并发症和治疗之间的逻辑联系。
-
输出结果:最终输出的三元组可能是 [(“糖尿病”, “导致”, “视网膜病变”), (“视网膜病变”, “治疗方式”, “激光治疗”)]。这些输出有助于医疗专业人员快速理解患者的病情和治疗方案。
通过这样的应用,CRE-LLM不仅提高了从医学文本中自动提取关键信息的效率,而且通过精确的关系抽取,支持了更深入的医学研究和更有针对性的治疗决策。
这种技术特别适用于处理复杂的医疗情况,其中需要理解多个实体之间的多层次关系。
区别对比
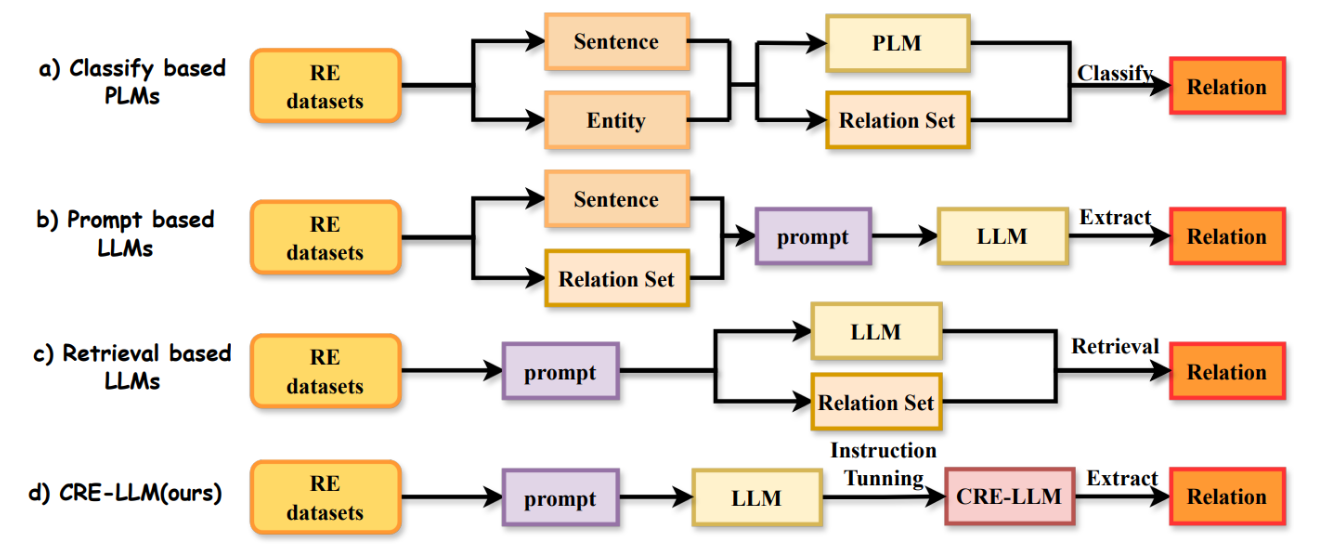
解决CRE任务的四种不同范式
- 这张图说明了四种解决CRE任务的方法:
- (a) 基于分类的PLMs: 使用预训练语言模型(PLM),通过关系集合输出概率最高的关系。
- (b) 基于提示的LLMs: 利用RE数据集和关系集合构建提示,然后输入到大型语言模型(LLM)中提取关系。
- © 基于检索的LLMs: 使用RE数据集构建提示,通过检索机制在LLM中提取关系。
- (d) CRE-LLM(本文的方法): 直接利用RE数据集构建的微调数据集来微调LLM,并生成准确的关系抽取结果。
CRE-LLM的主要作用是提取三元组(即实体-关系-实体的结构),但它在方法和应用方面具有几个独特的特点,尤其是在处理领域特定的文本数据时。
这种方法利用大型语言模型(LLMs)的强大能力,通过指令监督和微调,以生成式的方式提取和理解文本中的复杂关系。
以下是CRE-LLM与其他常见关系抽取方法相比的主要区别:
1. 生成式方法与分类方法的区别
- 分类方法(如传统的PLMs方法)通常基于固定的类别进行关系判定,需要大量的标注数据来训练模型识别预定义的关系类型。
- 生成式方法(如CRE-LLM采用的方法)则更灵活,它不依赖于事先定义的关系类型,而是可以生成关系的描述,允许模型探索文本中未预先标记的关系类型。
2. 指令监督的创新
- 其他方法往往重点关注模型的算法优化和数据的质量。
- CRE-LLM通过指令监督引导模型的关注点,使其能够更准确地聚焦于任务的关键部分。这种方式提供了一种直观的模型交互手段,能够有效地通过自然语言指令提高模型对复杂任务的理解。
3. 参数效率微调(PEFT)
- 许多现有的关系抽取方法依赖于对整个模型的重训练或广泛的微调。
- CRE-LLM采用的PEFT技术允许在保持模型底层复杂性的同时,仅微调模型的一小部分参数,这样做显著减少了计算资源的消耗,加快了模型调整的速度。
4. 适应领域特定任务的灵活性
- 许多关系抽取工具通用性较强,但可能在特定领域(如医疗、法律或金融)的适应性不足。
- CRE-LLM特别设计用于适应领域特定的数据和需求,通过针对特定领域的指令和微调策略,增强了模型在特定领域内的表现和准确性。
5. 直接关系提取
- 传统方法可能需要多步骤处理,如先分类后提取,或生成后检索。
- CRE-LLM通过生成直接的关系描述,简化了处理流程,提高了效率和准确性。
总的来说,CRE-LLM通过结合最新的大型语言模型技术、创新的指令监督方法和参数高效的微调策略,为领域特定的关系抽取任务提供了一个高效、灵活且资源节约的解决方案。
这使得它在处理需要深度理解和高精度的复杂文本数据时,特别是在有限的监督下,表现出其他方法难以匹敌的优势。
CRE-LLM通过直接生成三元组的方式简化了传统关系抽取流程中的多个步骤,减少了对复杂特征工程的依赖,并提高了处理速度和灵活性。
这种方法特别适合于处理大规模和复杂的文本数据,尤其是在需要快速有效地从大量文本中抽取精确关系时。
![[数据结构]———归并排序](https://img-blog.csdnimg.cn/direct/c6d4a450684449d0ac5cf1e14e89cca7.png)