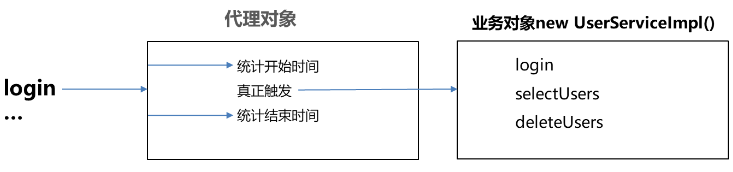
✨背景
对于设计的工作流来说,智能图像分割也是一个很重要的课题,尤其是像照片换脸、照片高清写真等等的工作流,可能要多次把人物的脸部或者手部抠图出来进行合成,工作流如果可以直接智能分割图像并合成,就可以避免自己再到ps中去抠图了,目前也的确有不少的模型和节点是用来做这个事情的,比如说ComfyUI中的Clipseg节点、GroundingDINO还有Yoloworld模型相关的节点等等。这里就简单测试下这三个模型,看下具体的效果如何。
(如果大家觉得有帮助的话,记得点点赞啊~🏃♀️)
🎡测试方法及结果
我们拿到这样一张原图:
(避免版权问题,这张图其实是midjourney直接生成的。)

然后搭建一个三种分割算法的工作流,并写提示词(比如说“face”)把面部分割出来,形成蒙版,然后把蒙版和原图进行合成,这样比较容易看出效果;
工作流截图:
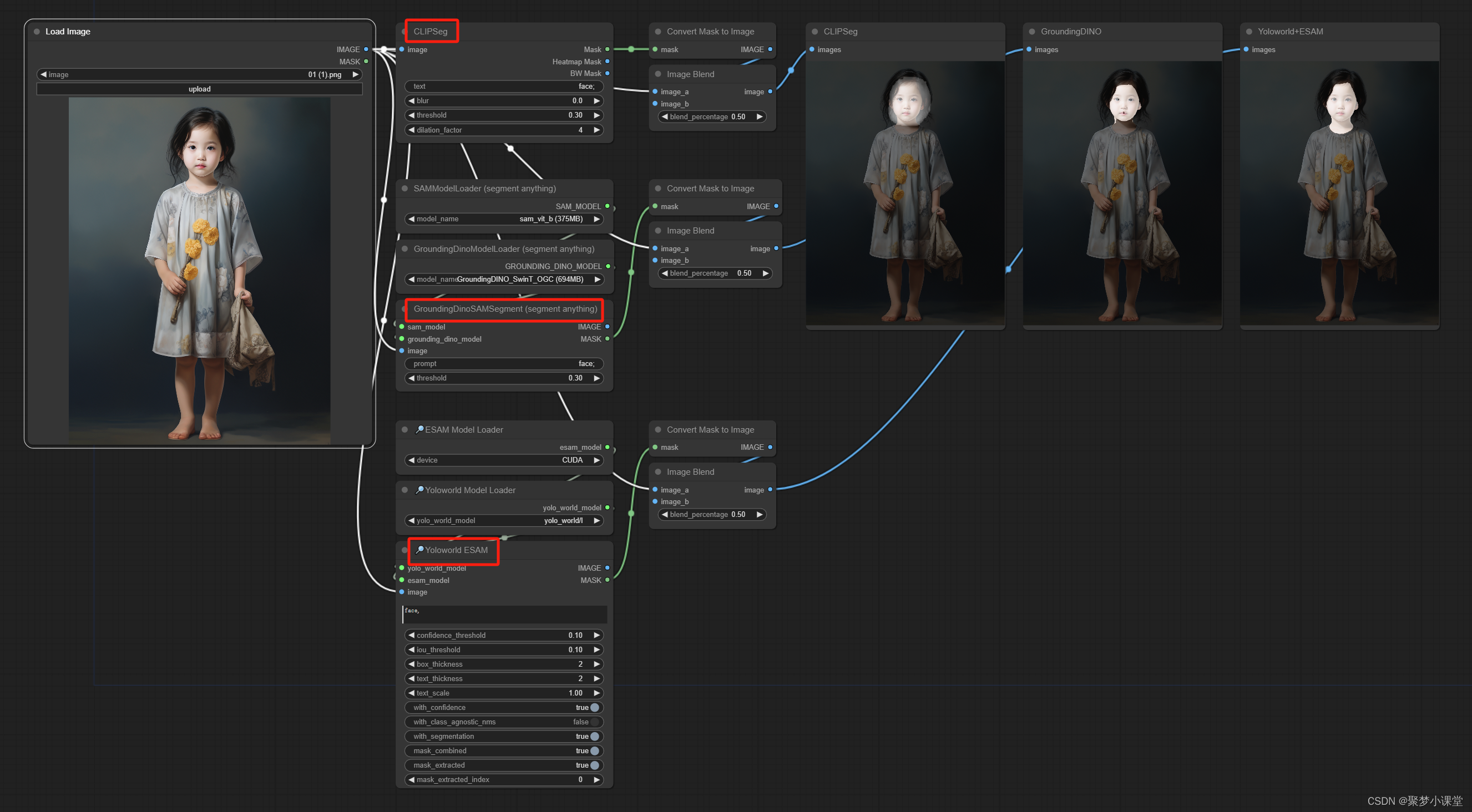
🙋♂️测试结果
face的分割效果:
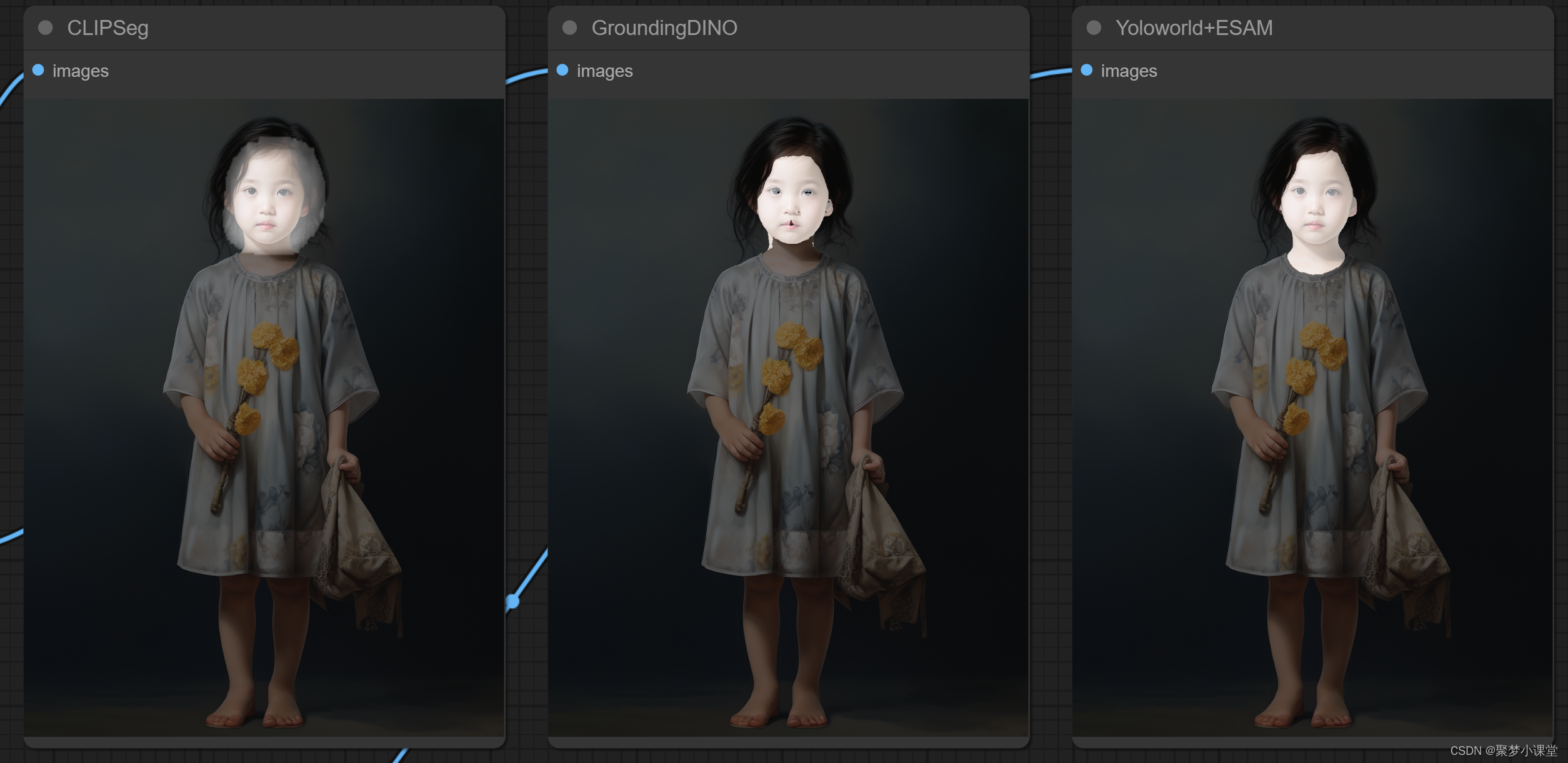
girl 的分割效果:
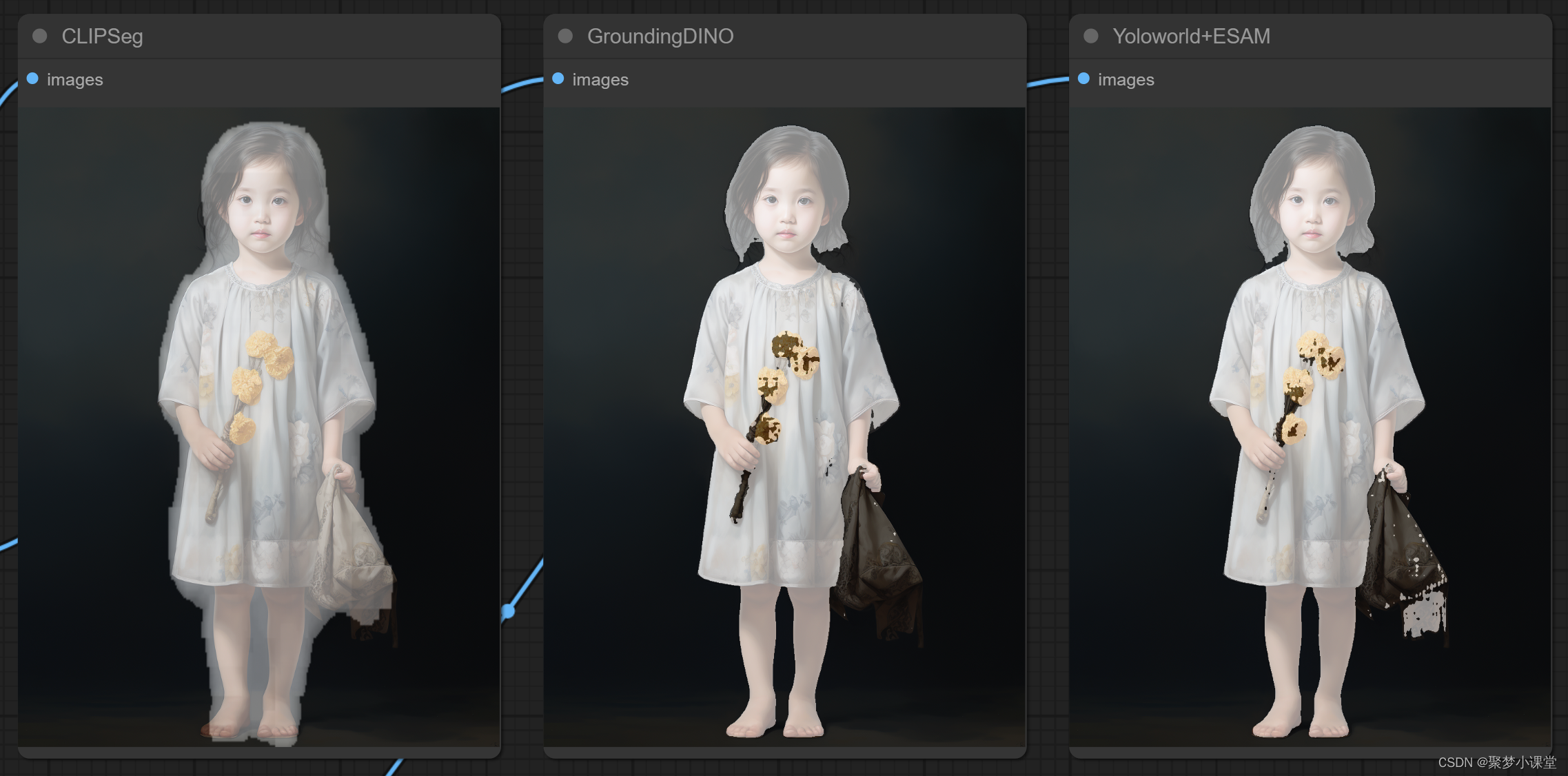
如果说AI生成的图像可能会有偏差,我们再从pixabay上找到一张图做一下测试:

还是用girl来做过滤:

再试验下组合词:hand,arm

dresses:
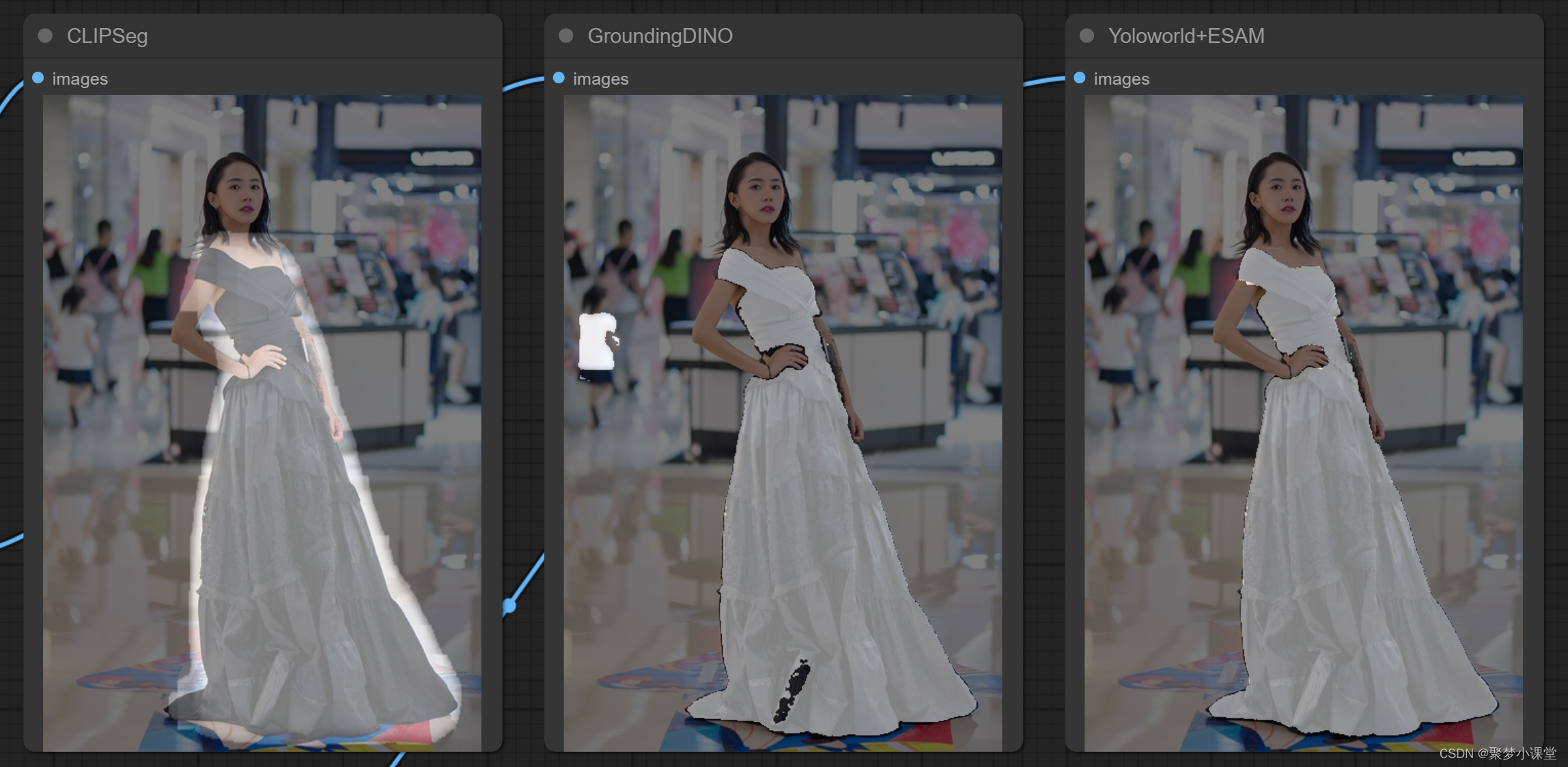
简单可以得出一个结论:
clipseg基本完败,这也是为什么用这个节点的时候,经常角色周围会有一圈很难处理干净,需要处理蒙版向内缩小一圈才能用;
GroundingDINO效果还可以,但是仔细看的话,经常会有一些莫名其妙的地方处理不干净,比如说人物面部:

综合来看,yoloworld-efficientSAM这个节点的效果最好。
(而且安装起来并不会比clipseg这个节点更复杂...)
🤶YoloWorld-EfficientSAM节点地址:
GitHub - ZHO-ZHO-ZHO/ComfyUI-YoloWorld-EfficientSAM: Unofficial implementation of YOLO-World + EfficientSAM for ComfyUI
👨测试工作流下载
下载地址:https://pan.quark.cn/s/16227e56e2a4
🎉写在最后~
去年的时候写了两门比较基础的Stable Diffuison WebUI的基础文字课程,大家如果喜欢的话,可以按需购买,在这里首先感谢各位老板的支持和厚爱~
✨StableDiffusion系统基础课(适合啥也不会的朋友,但是得有块Nvidia显卡):
https://blog.csdn.net/jumengxiaoketang/category_12477471.html
 🎆综合案例课程(适合有一点基础的朋友):
🎆综合案例课程(适合有一点基础的朋友):
https://blog.csdn.net/jumengxiaoketang/category_12526584.html
这里是聚梦小课堂,就算不买课也没关系,点个关注,交个朋友😄