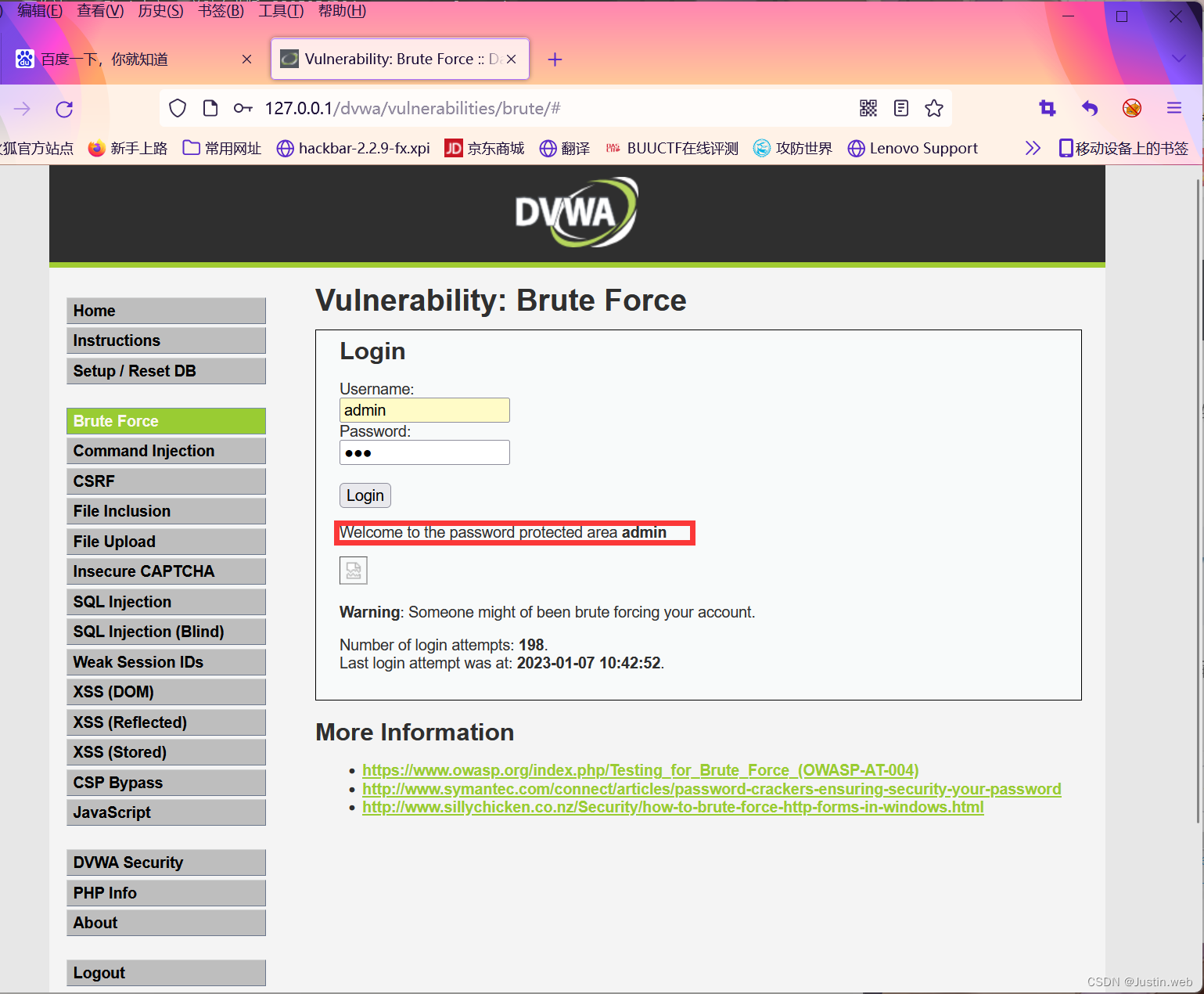
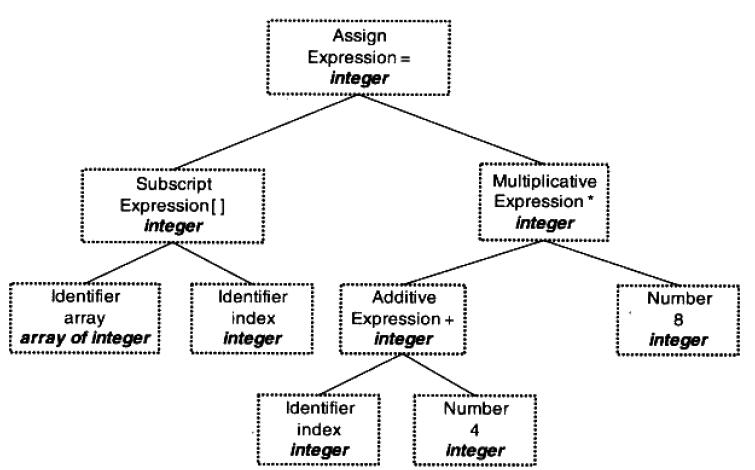
特征数据集是用于在机器学习中进行训练,有关特征的算法的分类如下所示:
|
特征抽取(Feature Extractors)
主要包括的算法是TF-IDF、Word2Vec、CountVectorizer、FeatureHasher。
TF-IDF
频繁项与倒排频繁文档(Term frequency-inverse document frequency),该算法用于特征向量化,被广泛地应用于文本挖掘,以反映出总体上一个词条项在文档中的重要性,假设,用t表示项,d表示文档,D表示全集,则频繁项TF(t,d)表示t在文档d中出现的次数,则频繁文档DF(t,D)表示包含t的文档个数,如果只是用频繁项去测量重要性,则很容易造成过于强调项是经常出现,但是在文档中却携带很少的信息,例如,a或者the或者of这些单词,很明显,这些词在文档中出现的次数不能体现出词的重要性。因此,倒排频繁文档是一个数字测量单位,用于体现一个项能提供多少信息,其公式定义如下所示:

如上所示,其中,|D|表示文档全集的数量,由于使用了对数,如果一个项在所有文档中都出现,则|D|等于DF(t,D),则该项对应的IDF值等于0,TF-IDF的公式定义如下所示:
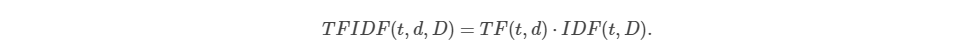
如上所示,其中,TFIDF包括了有关频繁项与频繁文档的变量,在Spark的机器学习技术框架MLlib中,TF与IDF是分开计算,以保证算法的灵活性。
TF
MLlib技术框架的HashingTF与CountVectorizer都可以应用于生成频繁项向量集。
其中,HashingTF是一个转换器,其使用特定的哈希技术将来自项的数据集合转换成固定长度的特征向量集合,在文本的处理过程中,项的集合对应单词词汇的集合。HashingTF使用哈希算法,一个项对应的原始特征通过一个哈希函数转换成一个索引值,频繁项基于索引值出现的次数进行计算,使用哈希技术的好处是,不必要创建一个项的总集以及每个项都映射到总集的位置上,从而节省了大量的内存空间。然而,使用哈希技术,当项对应的哈希值相同的时候,会出现碰撞的情况,为了降低哈希值碰撞的几率,可以提升哈希取模的维度,或者提升哈希表每个桶的大小,为了保证哈希值能均匀地分布,建议取模的维度设置为2的次方,默认的模维度是218等于262144,HashingTF也提供了其他参数设置,控制项频繁总数,当设置为true时,所有项频繁总数等于1,当进行概率模型的计算时,该参数设置非常有用。
其中,CountVectorizer提供将文本文档转换成项对应的向量集的总数。
IDF
IDF是一个估算器Estimator,用于对HashingTF 或者CountVectorizer创建的数据集进行拟合与训练、最终生成一个IDFModel类型的倒排频繁文档模型,该模型的输出提供缩小特征值的范围(特征规范化),也就是,降低在总集中频繁地出现的特征的权重值。
示例代码


如上所示,data是原文,定义三行记录的数据样本集,每行的第一列表示标签,第二列表示句子,schema定义一个数据表的元数据,包括两列,第一列label表示标签,第二列sentence表示句子,sentenceData是使用前面定义的data以及schema定义一个数据框架,tokenizer定义一个分词器用于对句子进行分词处理,输出单词词汇集,wordsData分词器输出单词词汇集,hashingTF是定义一个哈希转换器使用哈希算法对单词集合进行特征规范化处理,featurizedData是使用哈希算法处理的特征集,idf是定义一个估算器对特征集进行拟合以及训练,idfModel是使用特征集进行训练完成的模型,rescaledData是使用训练完成的模型对特征集进行预测,最后输出标签与特征的对应关系。
(未完待续)









![[硬核] Bootstrap Blazor Table 综合演示例子](https://img-blog.csdnimg.cn/img_convert/83cc3b1324c50758031c1c2cf53d6547.gif)