Union-Find连通性检测之quick-find
理论基础
在图论和计算机科学中,Union-Find 或并查集是一种用于处理一组元素分成的多个不相交集合(即连通分量)的情况,并能快速回答这组元素中任意两个元素是否在同一集合中的问题。Union-Find 特别适用于连通性问题,例如网络连接问题或确定图的连通分量。
Union-Find 的基本操作
Union-Find 数据结构支持两种基本操作:
- Union(合并): 将两个元素所在的集合合并成一个集合。
- Find(查找): 确定某个元素属于哪个集合,这通常涉及找到该集合的“代表元素”或“根元素”。
Union-Find 的结构
Union-Find 通常使用一个整数数组来表示,其中每个元素的值指向它的父节点,这样形成了一种树形结构。集合的“根元素”是其自己的父节点。
Union-Find 的优化技术
为了提高效率,Union-Find 实现中常用两种技术:
- 路径压缩(Path Compression): 在执行“查找”操作时,使路径上的每个节点都直接连接到根节点,从而压缩查找路径,减少后续操作的时间。
- 按秩合并(Union by Rank): 在执行“合并”操作时,总是将较小的树连接到较大的树的根节点上。这里的“秩”可以是树的深度或者树的大小。
应用示例
Union-Find 算法常用于处理动态连通性问题,如网络中的连接/断开问题或者图中连通分量的确定。例如,Kruskal 的最小生成树算法就使用 Union-Find 来选择边,以确保不形成环路。
总结
Union-Find 是解决连通性问题的一种非常高效的数据结构。它能够快速合并集合并快速判断元素之间的连通性。通过路径压缩和按秩合并的优化,Union-Find 在实际应用中可以接近常数时间完成操作。因此,它在算法竞赛、网络连接和社交网络分析等领域有广泛的应用。
数据结构
private int[] id // 分量id(以触点作为索引)
private int count // 分量数量
实验数据和算法流程
本实验使用tinyUF.txt作为实验数据,数据内容如下,一共定义了10对连通性关系
10
4 3
3 8
6 5
9 4
2 1
8 9
5 0
7 2
6 1
1 0
6 7
实验的目的是检测数据中共有多少个连通分量,并打印每个元素所属的连通分量编号
下图是处理元素5和9的一个处理瞬间
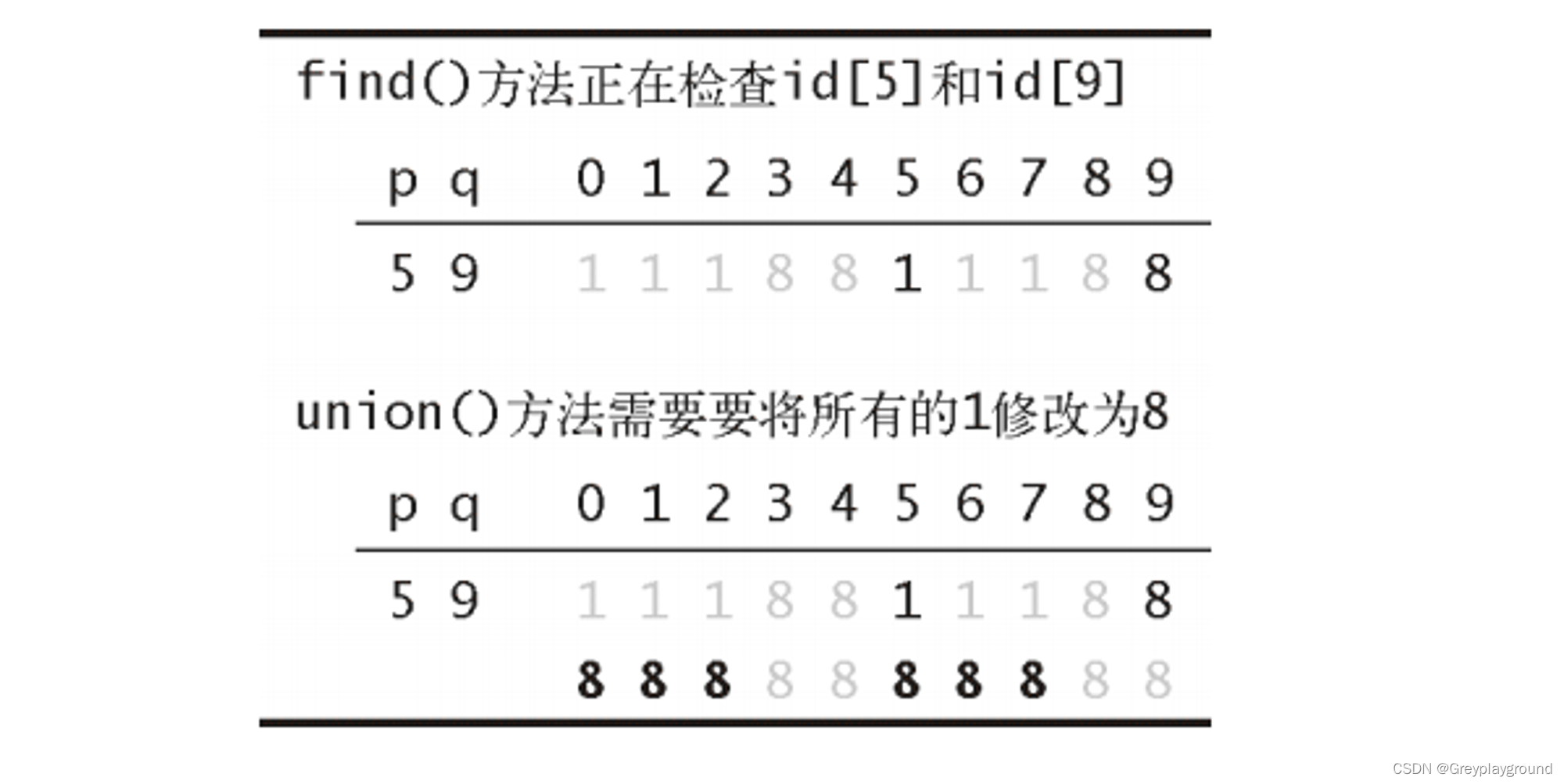
完整流程如下

代码实现
import edu.princeton.cs.algs4.StdOut;
import edu.princeton.cs.algs4.StdIn;
public class myQuickFind
{
private int[] id; // 分量id(以触点作为索引)
private int count; // 分量数量
public myQuickFind(int N)
{ // 初始化分量id数组
count = N;
id = new int[N];
for (int i = 0; i < N; i++)
id[i] = i;
}
public int count()
{ return count; }
public boolean connected(int p, int q)
{ return find(p) == find(q); }
public int find(int p)
{ return id[p]; }
public void union(int p, int q)
{ // 将p和q归并到相同的分量中
int pID = find(p);
int qID = find(q);
// 如果p和q已经在相同的分量之中则不需要采取任何行动
if (pID == qID) return;
// 将p的分量重命名为q的名称
for (int i = 0; i < id.length; i++)
if (id[i] == pID) id[i] = qID;
count--;
}
public static void main(String[] args)
{ // 解决由StdIn得到的动态连通性问题
int N = StdIn.readInt(); // 读取触点数量
myQuickFind qf = new myQuickFind(N); // 初始化N个分量
while (!StdIn.isEmpty())
{
int p = StdIn.readInt();
int q = StdIn.readInt(); // 读取整数对
if (qf.connected(p, q)) continue; // 如果已经连通则忽略
qf.union(p, q); // 归并分量
}
StdOut.println(qf.count() + " components");
for(int i = 0;i<N;i++){
StdOut.println(i + ":"+qf.find(i));
}
}
}
代码详解
这段代码实现了一种名为 Quick-Find 的并查集算法,用来解决动态连通性问题。下面是详细的代码解读:
类定义和变量
public class myQuickFind {
private int[] id; // 分量id(以触点作为索引)
private int count; // 分量数量
id数组用来存储每个节点的分量标识。在 Quick-Find 中,id数组的每个位置的值表示那个位置所属的组。count记录当前图中连通分量的数量。
构造函数
public myQuickFind(int N) {
count = N;
id = new int[N];
for (int i = 0; i < N; i++)
id[i] = i;
}
构造函数接受一个整数 N,表示图中节点的数量。初始时,每个节点自成一个连通分量,即每个节点都是自己的代表,因此 id[i] 初始化为 i。
辅助方法
public int count() { return count; }
public boolean connected(int p, int q) { return find(p) == find(q); }
public int find(int p) { return id[p]; }
count()返回当前连通分量的数量。connected(p, q)检查两个节点是否属于同一个连通分量。find(p)查找节点p的连通分量标识。
Union 操作
public void union(int p, int q) {
int pID = find(p);
int qID = find(q);
if (pID == qID) return; // 如果p和q已经在相同的分量之中则不需要采取任何行动
for (int i = 0; i < id.length; i++)
if (id[i] == pID) id[i] = qID;
count--;
}
union(p, q) 方法用于合并包含节点 p 和 q 的两个连通分量。如果两者已经在同一个连通分量中,则不做任何操作。否则,遍历 id 数组,将所有属于 p 的连通分量的节点都重新标记为属于 q 的连通分量。
主函数
public static void main(String[] args) {
int N = StdIn.readInt(); // 读取触点数量
myQuickFind qf = new myQuickFind(N); // 初始化N个分量
while (!StdIn.isEmpty()) {
int p = StdIn.readInt();
int q = StdIn.readInt(); // 读取整数对
if (qf.connected(p, q)) continue; // 如果已经连通则忽略
qf.union(p, q); // 归并分量
}
StdOut.println(qf.count() + " components");
for(int i = 0;i<N;i++){
StdOut.println(i + ":"+qf.find(i));
}
}
主函数从标准输入读取节点数量和一系列整数对。对于每对整数,如果它们不属于同一个连通分量,则调用 union 方法将它们合并。程序的最终输出是图中的连通分量数量,以及每个节点的连通分量标识。
Quick-Find 的性能
Quick-Find 算法的缺点在于 union 操作的高成本,它需要 O(N) 时间来处理每次合并操作,这在处理大量操作时可能变得非常慢。尽管如此,它的 find 操作非常快,只需常数时间 O(1)。因此,这种数据结构适用于不频繁进行 union 操作但需要频繁进行连通性检查的场景。
实验
代码编译
javac myQuickFind.java
代码运行
java myQuickFind < ..\data\tinyUF.txt
2 components
0:1
1:1
2:1
3:8
4:8
5:1
6:1
7:1
8:8
9:8
参考资料
算法(第四版) 人民邮电出版社